Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
淡淡忧伤的程序员
DolphinScheduler
提交
c2e6352e
DolphinScheduler
项目概览
淡淡忧伤的程序员
/
DolphinScheduler
与 Fork 源项目一致
Fork自
apache / DolphinScheduler
通知
48
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
DolphinScheduler
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
c2e6352e
编写于
7月 16, 2019
作者:
L
lidongdai
浏览文件
操作
浏览文件
下载
差异文件
merge from 1.1.0 upstream
上级
a62ba2b4
bd30d48c
变更
14
隐藏空白更改
内联
并排
Showing
14 changed file
with
139 addition
and
42 deletion
+139
-42
docs/zh_CN/1.1.0-release.md
docs/zh_CN/1.1.0-release.md
+55
-0
docs/zh_CN/SUMMARY.md
docs/zh_CN/SUMMARY.md
+1
-0
docs/zh_CN/book.json
docs/zh_CN/book.json
+1
-1
docs/zh_CN/images/hive_kerberos.png
docs/zh_CN/images/hive_kerberos.png
+0
-0
docs/zh_CN/images/sparksql_kerberos.png
docs/zh_CN/images/sparksql_kerberos.png
+0
-0
docs/zh_CN/系统使用手册.md
docs/zh_CN/系统使用手册.md
+38
-22
escheduler-api/src/main/java/cn/escheduler/api/enums/Status.java
...ler-api/src/main/java/cn/escheduler/api/enums/Status.java
+1
-0
escheduler-api/src/main/java/cn/escheduler/api/service/ExecutorService.java
.../main/java/cn/escheduler/api/service/ExecutorService.java
+24
-7
escheduler-api/src/main/java/cn/escheduler/api/service/ProcessDefinitionService.java
...a/cn/escheduler/api/service/ProcessDefinitionService.java
+1
-1
escheduler-api/src/main/java/cn/escheduler/api/service/SchedulerService.java
...main/java/cn/escheduler/api/service/SchedulerService.java
+4
-4
escheduler-common/src/main/java/cn/escheduler/common/queue/TaskQueueZkImpl.java
...main/java/cn/escheduler/common/queue/TaskQueueZkImpl.java
+7
-4
escheduler-server/src/main/java/cn/escheduler/server/utils/LoggerUtils.java
...src/main/java/cn/escheduler/server/utils/LoggerUtils.java
+2
-1
escheduler-server/src/main/java/cn/escheduler/server/worker/runner/FetchTaskThread.java
...a/cn/escheduler/server/worker/runner/FetchTaskThread.java
+5
-0
escheduler-ui/src/js/conf/home/pages/dag/_source/dag.vue
escheduler-ui/src/js/conf/home/pages/dag/_source/dag.vue
+0
-2
未找到文件。
docs/zh_CN/1.1.0-release.md
0 → 100644
浏览文件 @
c2e6352e
Easy Scheduler Release 1.1.0
===
Easy Scheduler 1.1.0是1.x系列中的第五个版本。
新特性:
===
-
[
[EasyScheduler-391
](
https://github.com/analysys/EasyScheduler/issues/391
)
] run a process under a specified tenement user
-
[
[EasyScheduler-288
](
https://github.com/analysys/EasyScheduler/issues/288
)
] Feature/qiye_weixin
-
[
[EasyScheduler-189
](
https://github.com/analysys/EasyScheduler/issues/189
)
] Kerberos等安全支持
-
[
[EasyScheduler-398
](
https://github.com/analysys/EasyScheduler/issues/398
)
]管理员,有租户(install.sh设置默认租户),可以创建资源、项目和数据源(限制有一个管理员)
-
[
[EasyScheduler-293
](
https://github.com/analysys/EasyScheduler/issues/293
)
]点击运行流程时候选择的参数,没有地方可查看,也没有保存
-
[
[EasyScheduler-401
](
https://github.com/analysys/EasyScheduler/issues/401
)
]定时很容易定时每秒一次,定时完成以后可以在页面显示一下下次触发时间
-
[
[EasyScheduler-493
](
https://github.com/analysys/EasyScheduler/pull/493
)
]add datasource kerberos auth and FAQ modify and add resource upload s3
增强:
===
-
[
[EasyScheduler-227
](
https://github.com/analysys/EasyScheduler/issues/227
)
] upgrade spring-boot to 2.1.x and spring to 5.x
-
[
[EasyScheduler-434
](
https://github.com/analysys/EasyScheduler/issues/434
)
] worker节点数量 zk和mysql中不一致
-
[
[EasyScheduler-435
](
https://github.com/analysys/EasyScheduler/issues/435
)
]邮箱格式的验证
-
[
[EasyScheduler-441
](
https://github.com/analysys/EasyScheduler/issues/441
)
] 禁止运行节点加入已完成节点检测
-
[
[EasyScheduler-400
](
https://github.com/analysys/EasyScheduler/issues/400
)
] 首页页面,队列统计不和谐,命令统计无数据
-
[
[EasyScheduler-395
](
https://github.com/analysys/EasyScheduler/issues/395
)
] 对于容错恢复的流程,状态不能为
**
正在运行
-
[
[EasyScheduler-529
](
https://github.com/analysys/EasyScheduler/issues/529
)
] optimize poll task from zookeeper
-
[
[EasyScheduler-242
](
https://github.com/analysys/EasyScheduler/issues/242
)
]worker-server节点获取任务性能问题
-
[
[EasyScheduler-352
](
https://github.com/analysys/EasyScheduler/issues/352
)
]worker 分组, 队列消费问题
-
[
[EasyScheduler-461
](
https://github.com/analysys/EasyScheduler/issues/461
)
]查看数据源参数,需要加密账号密码信息
-
[
[EasyScheduler-396
](
https://github.com/analysys/EasyScheduler/issues/396
)
]Dockerfile优化,并关联Dockerfile和github实现自动打镜像
-
[
[EasyScheduler-389
](
https://github.com/analysys/EasyScheduler/issues/389
)
]service monitor cannot find the change of master/worker
-
[
[EasyScheduler-511
](
https://github.com/analysys/EasyScheduler/issues/511
)
]support recovery process from stop/kill nodes.
-
[
[EasyScheduler-399
](
https://github.com/analysys/EasyScheduler/issues/399
)
]HadoopUtils指定用户操作,而不是
**
部署用户
修复:
===
-
[
[EasyScheduler-394
](
https://github.com/analysys/EasyScheduler/issues/394
)
] master&worker部署在同一台机器上时,如果重启master&worker服务,会导致之前调度的任务无法继续调度
-
[
[EasyScheduler-469
](
https://github.com/analysys/EasyScheduler/issues/469
)
]Fix naming errors,monitor page
-
[
[EasyScheduler-392
](
https://github.com/analysys/EasyScheduler/issues/392
)
]Feature request: fix email regex check
-
[
[EasyScheduler-405
](
https://github.com/analysys/EasyScheduler/issues/405
)
]定时修改/添加页面,开始时间和结束时间不能相同
-
[
[EasyScheduler-517
](
https://github.com/analysys/EasyScheduler/issues/517
)
]补数 - 子工作流 - 时间参数
-
[
[EasyScheduler-532
](
https://github.com/analysys/EasyScheduler/issues/532
)
]python节点不执行的问题
-
[
[EasyScheduler-543
](
https://github.com/analysys/EasyScheduler/issues/543
)
]optimize datasource connection params safety
-
[
[EasyScheduler-569
](
https://github.com/analysys/EasyScheduler/issues/569
)
]定时任务无法真正停止
-
[
[EasyScheduler-463
](
https://github.com/analysys/EasyScheduler/issues/463
)
]邮箱验证不支持非常见后缀邮箱
感谢:
===
最后但最重要的是,没有以下伙伴的贡献就没有新版本的诞生:
Baoqi, jimmy201602, samz406, petersear, millionfor, hyperknob, fanguanqun, yangqinlong, qq389401879, chgxtony, Stanfan, lfyee, thisnew, hujiang75277381, sunnyingit, lgbo-ustc, ivivi, lzy305, JackIllkid, telltime, lipengbo2018, wuchunfu, telltime
以及微信群里众多的热心伙伴!在此非常感谢!
docs/zh_CN/SUMMARY.md
浏览文件 @
c2e6352e
...
...
@@ -35,6 +35,7 @@
*
系统版本升级文档
*
[
版本升级
](
升级文档.md
)
*
历次版本发布内容
*
[
1.1.0 release
](
1.1.0-release.md
)
*
[
1.0.3 release
](
1.0.3-release.md
)
*
[
1.0.2 release
](
1.0.2-release.md
)
*
[
1.0.1 release
](
1.0.1-release.md
)
...
...
docs/zh_CN/book.json
浏览文件 @
c2e6352e
{
"title"
:
"调度系统-EasyScheduler"
,
"author"
:
"
YIGUAN
"
,
"author"
:
""
,
"description"
:
"调度系统"
,
"language"
:
"zh-hans"
,
"gitbook"
:
"3.2.3"
,
...
...
docs/zh_CN/images/hive_kerberos.png
0 → 100644
浏览文件 @
c2e6352e
36.2 KB
docs/zh_CN/images/sparksql_kerberos.png
0 → 100644
浏览文件 @
c2e6352e
36.5 KB
docs/zh_CN/系统使用手册.md
浏览文件 @
c2e6352e
...
...
@@ -60,7 +60,7 @@
### 执行流程定义
-
**未上线状态的流程定义可以编辑,但是不可以运行**
,所以先上线工作流
> 点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
> "下线"工作流之前,要先将定时管理的定时下线,才能成功下线工作流定义
-
点击”运行“,执行工作流。运行参数说明:
...
...
@@ -98,28 +98,28 @@
### 查看流程实例
> 点击“工作流实例”,查看流程实例列表。
> 点击工作流名称,查看任务执行状态。
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/instance-detail.png"
width=
"60%"
/>
</p>
> 点击任务节点,点击“查看日志”,查看任务执行日志。
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/task-log.png"
width=
"60%"
/>
</p>
> 点击任务实例节点,点击**查看历史**,可以查看该流程实例运行的该任务实例列表
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/EasyScheduler/zh_CN/images/task_history.png"
width=
"60%"
/>
</p>
> 对工作流实例的操作:
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/instance-list.png"
width=
"60%"
/>
</p>
...
...
@@ -165,7 +165,7 @@
-
密码:设置连接MySQL的密码
-
数据库名:输入连接MySQL的数据库名称
-
Jdbc连接参数:用于MySQL连接的参数设置,以JSON形式填写
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/mysql_edit.png"
width=
"60%"
/>
</p>
...
...
@@ -191,7 +191,7 @@
#### 创建、编辑HIVE数据源
1.
使用HiveServer2方式连接
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/hive_edit.png"
width=
"60%"
/>
</p>
...
...
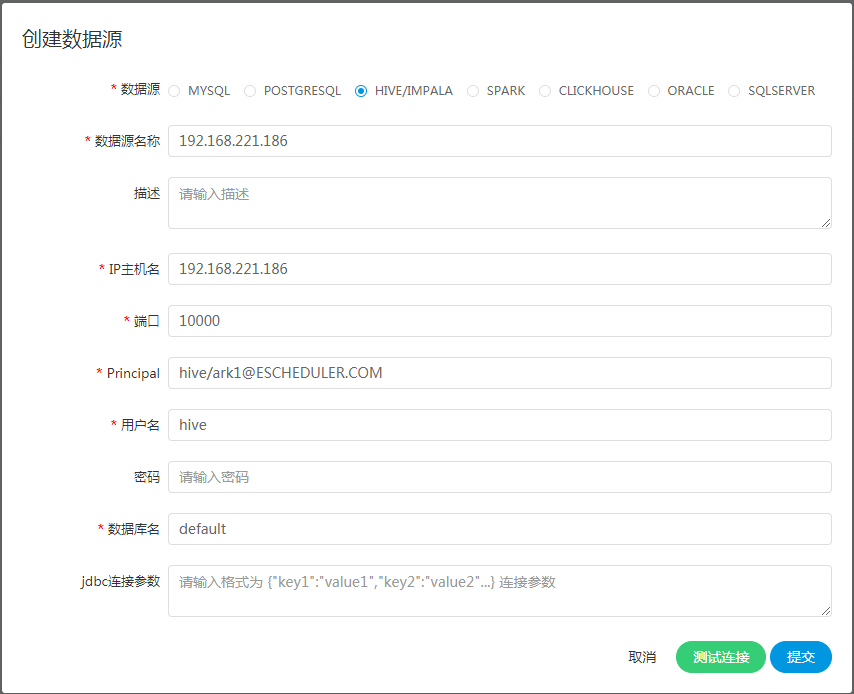
@@ -207,12 +207,20 @@
-
Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写
2.
使用HiveServer2 HA Zookeeper方式连接
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/hive_edit2.png"
width=
"60%"
/>
</p>
注意:如果开启了
**kerberos**
,则需要填写
**Principal**
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/hive_kerberos.png"
width=
"60%"
/>
</p>
#### 创建、编辑Spark数据源
<p
align=
"center"
>
...
...
@@ -229,9 +237,17 @@
-
数据库名:输入连接Spark的数据库名称
-
Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
注意:如果开启了
**kerberos**
,则需要填写
**Principal**
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/sparksql_kerberos.png"
width=
"60%"
/>
</p>
### 上传资源
-
上传资源文件和udf函数,所有上传的文件和资源都会被存储到hdfs上,所以需要以下配置项:
```
conf/common/common.properties
-- hdfs.startup.state=true
...
...
@@ -242,7 +258,7 @@ conf/common/hadoop.properties
```
#### 文件管理
> 是对各种资源文件的管理,包括创建基本的txt/log/sh/conf等文件、上传jar包等各种类型文件,以及编辑、下载、删除等操作。
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/file-manage.png"
width=
"60%"
/>
...
...
@@ -287,7 +303,7 @@ conf/common/hadoop.properties
#### 资源管理
> 资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件
*
上传udf资源
> 和上传文件相同。
...
...
@@ -303,7 +319,7 @@ conf/common/hadoop.properties
-
参数:用来标注函数的输入参数
-
数据库名:预留字段,用于创建永久UDF函数
-
UDF资源:设置创建的UDF对应的资源文件
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/udf_edit.png"
width=
"60%"
/>
</p>
...
...
@@ -312,7 +328,7 @@ conf/common/hadoop.properties
-
安全中心是只有管理员账户才有权限的功能,有队列管理、租户管理、用户管理、告警组管理、worker分组、令牌管理等功能,还可以对资源、数据源、项目等授权
-
管理员登录,默认用户名密码:admin/escheduler123
### 创建队列
-
队列是在执行spark、mapreduce等程序,需要用到“队列”参数时使用的。
-
“安全中心”->“队列管理”->“创建队列”
...
...
@@ -357,7 +373,7 @@ conf/common/hadoop.properties
### 令牌管理
-
由于后端接口有登录检查,令牌管理,提供了一种可以通过调用接口的方式对系统进行各种操作。
-
调用示例:
```
令牌调用示例
/**
* test token
...
...
@@ -477,15 +493,15 @@ conf/common/hadoop.properties
### 依赖(DEPENDENT)节点
-
依赖节点,就是
**依赖检查节点**
。比如A流程依赖昨天的B流程执行成功,依赖节点会去检查B流程在昨天是否有执行成功的实例。
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/dependent_edit.png"
width=
"60%"
/>
</p>
> 依赖节点提供了逻辑判断功能,比如检查昨天的B流程是否成功,或者C流程是否执行成功。
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/depend-node.png"
width=
"80%"
/>
</p>
...
...
@@ -536,7 +552,7 @@ conf/common/hadoop.properties
### SPARK节点
-
通过SPARK节点,可以直接直接执行SPARK程序,对于spark节点,worker会使用
`spark-submit`
方式提交任务
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
<p
align=
"center"
>
...
...
@@ -563,7 +579,7 @@ conf/common/hadoop.properties
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
1.
JAVA程序
<p
align=
"center"
>
<img
src=
"https://analysys.github.io/easyscheduler_docs_cn/images/mr_java.png"
width=
"60%"
/>
</p>
...
...
@@ -592,7 +608,7 @@ conf/common/hadoop.properties
### Python节点
-
使用python节点,可以直接执行python脚本,对于python节点,worker会使用
`python **`
方式提交任务。
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
...
...
escheduler-api/src/main/java/cn/escheduler/api/enums/Status.java
浏览文件 @
c2e6352e
...
...
@@ -212,6 +212,7 @@ public enum Status {
DELETE_SCHEDULE_CRON_BY_ID_ERROR
(
50024
,
"delete schedule by id error"
),
BATCH_DELETE_PROCESS_DEFINE_ERROR
(
50025
,
"batch delete process definition error"
),
BATCH_DELETE_PROCESS_DEFINE_BY_IDS_ERROR
(
50026
,
"batch delete process definition by ids {0} error"
),
TENANT_NOT_SUITABLE
(
50027
,
"there is not any tenant suitable, please choose a tenant available."
),
HDFS_NOT_STARTUP
(
60001
,
"hdfs not startup"
),
HDFS_TERANT_RESOURCES_FILE_EXISTS
(
60002
,
"resource file exists,please delete resource first"
),
...
...
escheduler-api/src/main/java/cn/escheduler/api/service/ExecutorService.java
浏览文件 @
c2e6352e
...
...
@@ -110,6 +110,13 @@ public class ExecutorService extends BaseService{
return
result
;
}
if
(!
checkTenantSuitable
(
processDefinition
)){
logger
.
error
(
"there is not any vaild tenant for the process definition: id:{},name:{}, "
,
processDefinition
.
getId
(),
processDefinition
.
getName
());
putMsg
(
result
,
Status
.
TENANT_NOT_SUITABLE
);
return
result
;
}
/**
* create command
*/
...
...
@@ -190,15 +197,10 @@ public class ExecutorService extends BaseService{
if
(
status
!=
Status
.
SUCCESS
)
{
return
checkResult
;
}
// checkTenantExists();
Tenant
tenant
=
processDao
.
getTenantForProcess
(
processDefinition
.
getTenantId
(),
processDefinition
.
getUserId
());
if
(
tenant
==
null
){
if
(!
checkTenantSuitable
(
processDefinition
)){
logger
.
error
(
"there is not any vaild tenant for the process definition: id:{},name:{}, "
,
processDefinition
.
getId
(),
processDefinition
.
getName
());
putMsg
(
result
,
Status
.
PROCESS_INSTANCE_NOT_EXIST
,
processInstanceId
);
return
result
;
putMsg
(
result
,
Status
.
TENANT_NOT_SUITABLE
);
}
switch
(
executeType
)
{
...
...
@@ -240,6 +242,21 @@ public class ExecutorService extends BaseService{
return
result
;
}
/**
* check tenant suitable
* @param processDefinition
* @return
*/
private
boolean
checkTenantSuitable
(
ProcessDefinition
processDefinition
)
{
// checkTenantExists();
Tenant
tenant
=
processDao
.
getTenantForProcess
(
processDefinition
.
getTenantId
(),
processDefinition
.
getUserId
());
if
(
tenant
==
null
){
return
false
;
}
return
true
;
}
/**
* Check the state of process instance and the type of operation match
*
...
...
escheduler-api/src/main/java/cn/escheduler/api/service/ProcessDefinitionService.java
浏览文件 @
c2e6352e
...
...
@@ -490,7 +490,7 @@ public class ProcessDefinitionService extends BaseDAGService {
// set status
schedule
.
setReleaseState
(
ReleaseState
.
OFFLINE
);
scheduleMapper
.
update
(
schedule
);
deleteSchedule
(
project
.
getId
(),
id
);
deleteSchedule
(
project
.
getId
(),
schedule
.
getId
()
);
}
break
;
}
...
...
escheduler-api/src/main/java/cn/escheduler/api/service/SchedulerService.java
浏览文件 @
c2e6352e
...
...
@@ -456,14 +456,14 @@ public class SchedulerService extends BaseService {
/**
* delete schedule
*/
public
static
void
deleteSchedule
(
int
projectId
,
int
process
Id
)
throws
RuntimeException
{
logger
.
info
(
"delete schedules of project id:{},
flow id:{}"
,
projectId
,
process
Id
);
public
static
void
deleteSchedule
(
int
projectId
,
int
schedule
Id
)
throws
RuntimeException
{
logger
.
info
(
"delete schedules of project id:{},
schedule id:{}"
,
projectId
,
schedule
Id
);
String
jobName
=
QuartzExecutors
.
buildJobName
(
process
Id
);
String
jobName
=
QuartzExecutors
.
buildJobName
(
schedule
Id
);
String
jobGroupName
=
QuartzExecutors
.
buildJobGroupName
(
projectId
);
if
(!
QuartzExecutors
.
getInstance
().
deleteJob
(
jobName
,
jobGroupName
)){
logger
.
warn
(
"set offline failure:projectId:{},
processId:{}"
,
projectId
,
process
Id
);
logger
.
warn
(
"set offline failure:projectId:{},
scheduleId:{}"
,
projectId
,
schedule
Id
);
throw
new
RuntimeException
(
String
.
format
(
"set offline failure"
));
}
...
...
escheduler-common/src/main/java/cn/escheduler/common/queue/TaskQueueZkImpl.java
浏览文件 @
c2e6352e
...
...
@@ -228,11 +228,11 @@ public class TaskQueueZkImpl extends AbstractZKClient implements ITaskQueue {
int
j
=
0
;
List
<
String
>
taskslist
=
new
ArrayList
<>(
tasksNum
);
while
(
iterator
.
hasNext
()){
if
(
j
++
<
tasksNum
){
String
task
=
iterator
.
next
();
taskslist
.
add
(
getOriginTaskFormat
(
task
));
if
(
j
++
>=
tasksNum
){
break
;
}
String
task
=
iterator
.
next
();
taskslist
.
add
(
getOriginTaskFormat
(
task
));
}
return
taskslist
;
}
...
...
@@ -245,6 +245,9 @@ public class TaskQueueZkImpl extends AbstractZKClient implements ITaskQueue {
*/
private
String
getOriginTaskFormat
(
String
formatTask
){
String
[]
taskArray
=
formatTask
.
split
(
Constants
.
UNDERLINE
);
if
(
taskArray
.
length
<
4
){
return
formatTask
;
}
int
processInstanceId
=
Integer
.
parseInt
(
taskArray
[
1
]);
int
taskId
=
Integer
.
parseInt
(
taskArray
[
3
]);
...
...
escheduler-server/src/main/java/cn/escheduler/server/utils/LoggerUtils.java
浏览文件 @
c2e6352e
...
...
@@ -16,6 +16,7 @@
*/
package
cn.escheduler.server.utils
;
import
cn.escheduler.common.Constants
;
import
org.slf4j.Logger
;
import
java.util.ArrayList
;
...
...
@@ -31,7 +32,7 @@ public class LoggerUtils {
/**
* rules for extracting application ID
*/
private
static
final
Pattern
APPLICATION_REGEX
=
Pattern
.
compile
(
"\\d+_\\d+"
);
private
static
final
Pattern
APPLICATION_REGEX
=
Pattern
.
compile
(
Constants
.
APPLICATION_REGEX
);
/**
* build job id
...
...
escheduler-server/src/main/java/cn/escheduler/server/worker/runner/FetchTaskThread.java
浏览文件 @
c2e6352e
...
...
@@ -210,6 +210,11 @@ public class FetchTaskThread implements Runnable{
Tenant
tenant
=
processDao
.
getTenantForProcess
(
processInstance
.
getTenantId
(),
processDefine
.
getUserId
());
if
(
tenant
==
null
){
logger
.
error
(
"cannot find suitable tenant for the task:{}, process instance tenant:{}, process definition tenant:{}"
,
taskInstance
.
getName
(),
processInstance
.
getTenantId
(),
processDefine
.
getTenantId
());
continue
;
}
// check and create Linux users
FileUtils
.
createWorkDirAndUserIfAbsent
(
execLocalPath
,
...
...
escheduler-ui/src/js/conf/home/pages/dag/_source/dag.vue
浏览文件 @
c2e6352e
...
...
@@ -459,8 +459,6 @@
'
tasks
'
:
{
deep
:
true
,
handler
(
o
)
{
console
.
log
(
'
+++++ save dag params +++++
'
)
console
.
log
(
o
)
// Edit state does not allow deletion of node a...
this
.
setIsEditDag
(
true
)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
