fix conflicts
Showing
StyleTextRec/README.md
0 → 100644
StyleTextRec/README_ch.md
0 → 100644
StyleTextRec/__init__.py
0 → 100644
StyleTextRec/arch/__init__.py
0 → 100644
StyleTextRec/arch/base_module.py
0 → 100644
StyleTextRec/arch/decoder.py
0 → 100644
StyleTextRec/arch/encoder.py
0 → 100644
StyleTextRec/configs/config.yml
0 → 100644
StyleTextRec/doc/images/1.png
0 → 100644
{kind=link}

167.9 KB
StyleTextRec/doc/images/2.png
0 → 100644
{kind=link}

200.7 KB
StyleTextRec/doc/images/3.png
0 → 100644
{kind=link}
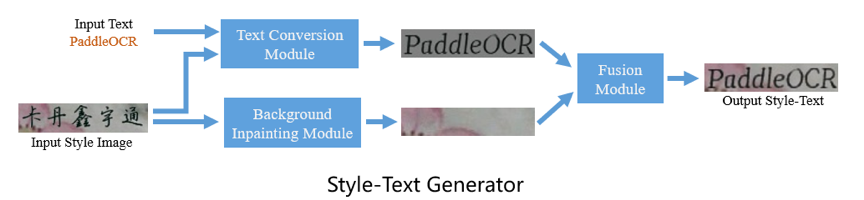
67.7 KB
StyleTextRec/doc/images/4.jpg
0 → 100644
{kind=link}

2.2 KB
StyleTextRec/doc/images/5.png
0 → 100644
{kind=link}

122.5 KB
StyleTextRec/doc/images/6.png
0 → 100644
{kind=link}

124.7 KB
StyleTextRec/engine/__init__.py
0 → 100644
StyleTextRec/engine/predictors.py
0 → 100644
StyleTextRec/engine/writers.py
0 → 100644
{kind=link}

2.5 KB
{kind=link}

3.8 KB
文件已添加
文件已添加
文件已添加
StyleTextRec/tools/__init__.py
0 → 100644
StyleTextRec/tools/synth_image.py
0 → 100644
StyleTextRec/utils/__init__.py
0 → 100644
StyleTextRec/utils/config.py
0 → 100644
StyleTextRec/utils/load_params.py
0 → 100644
StyleTextRec/utils/logging.py
0 → 100644
StyleTextRec/utils/sys_funcs.py
0 → 100644
doc/doc_en/benchmark_en.md
100644 → 100755
文件模式从 100644 更改为 100755
doc/imgs_results/det_res_22.jpg
0 → 100644
{kind=link}

76.3 KB
doc/imgs_words_en/.DS_Store
已删除
100644 → 0
文件已删除