Merge branch 'develop' into memory.set_input
Showing
demo/introduction/api_train_v2.py
0 → 100644
demo/mnist/api_train_v2.py
0 → 100644
demo/sentiment/train_v2.py
0 → 100644
demo/seqToseq/api_train_v2.py
0 → 100644
demo/word2vec/train_v2.py
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
doc/api/v1/index_cn.rst
0 → 100644
doc/api/v1/index_en.rst
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
doc/api/v2/config/activation.rst
0 → 100644
doc/api/v2/config/attr.rst
0 → 100644
doc/api/v2/config/layer.rst
0 → 100644
doc/api/v2/config/networks.rst
0 → 100644
doc/api/v2/config/optimizer.rst
0 → 100644
doc/api/v2/config/pooling.rst
0 → 100644
doc/api/v2/data.rst
0 → 100644
doc/api/v2/model_configs.rst
0 → 100644
doc/api/v2/run_logic.rst
0 → 100644
doc/design/reader/README.md
0 → 100644
{kind=link}
{kind=link}
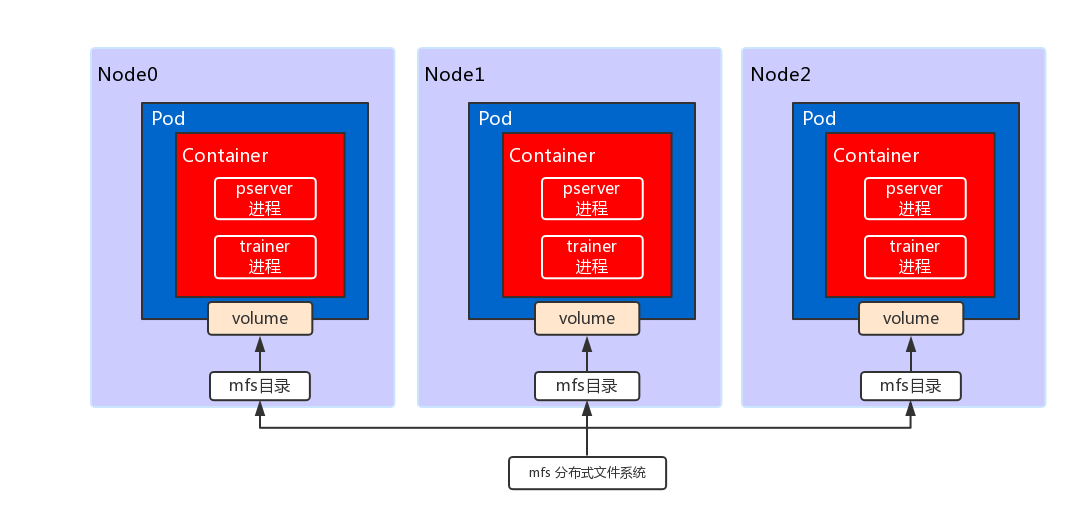
| W: | H:
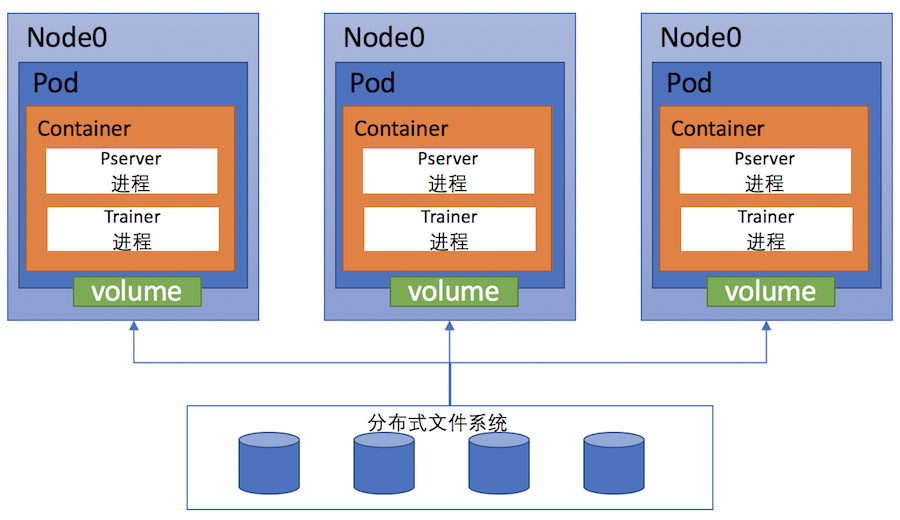
| W: | H:
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/deb/postinst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/v2/activation.py
0 → 100644
此差异已折叠。
python/paddle/v2/attr.py
0 → 100644
此差异已折叠。
python/paddle/v2/config_base.py
0 → 100644
此差异已折叠。
python/paddle/v2/data_feeder.py
0 → 100644
此差异已折叠。
python/paddle/v2/data_type.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/paddle/v2/dataset/cifar.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/v2/dataset/imdb.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/paddle/v2/dataset/mnist.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/v2/dataset/wmt14.py
0 → 100644
此差异已折叠。
python/paddle/v2/event.py
0 → 100644
此差异已折叠。
python/paddle/v2/inference.py
0 → 100644
此差异已折叠。
python/paddle/v2/layer.py
0 → 100644
此差异已折叠。
python/paddle/v2/minibatch.py
0 → 100644
此差异已折叠。
python/paddle/v2/networks.py
0 → 100644
此差异已折叠。
python/paddle/v2/parameters.py
0 → 100644
此差异已折叠。
python/paddle/v2/pooling.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/v2/topology.py
0 → 100644
此差异已折叠。
python/paddle/v2/trainer.py
0 → 100644
此差异已折叠。
此差异已折叠。