2020-09-02 08:20:29
Showing
docs/dl-cv/00.md
0 → 100644
docs/dl-cv/01.md
0 → 100644
此差异已折叠。
docs/dl-cv/02.md
0 → 100644
此差异已折叠。
docs/dl-cv/03.md
0 → 100644
此差异已折叠。
docs/dl-cv/04.md
0 → 100644
此差异已折叠。
docs/dl-cv/05.md
0 → 100644
此差异已折叠。
docs/dl-cv/06.md
0 → 100644
此差异已折叠。
docs/dl-cv/07.md
0 → 100644
docs/dl-cv/08.md
0 → 100644
此差异已折叠。
docs/dl-cv/09.md
0 → 100644
此差异已折叠。
docs/dl-cv/10.md
0 → 100644
此差异已折叠。
docs/dl-cv/cover.jpg
0 → 100644
{kind=link}

23.7 KB
{kind=link}
5.6 KB
{kind=link}
11.0 KB
{kind=link}

932 字节
{kind=link}

1.0 KB
{kind=link}
4.8 KB
{kind=link}

24.7 KB
{kind=link}

9.7 KB
{kind=link}

31.1 KB
{kind=link}
10.0 KB
{kind=link}

18.0 KB
{kind=link}
11.2 KB
{kind=link}
7.3 KB
{kind=link}

37.0 KB
{kind=link}
9.2 KB
{kind=link}

62.4 KB
{kind=link}

2.0 KB
{kind=link}
10.5 KB
{kind=link}

3.6 KB
{kind=link}
6.0 KB
{kind=link}
8.0 KB
{kind=link}
12.7 KB
{kind=link}
3.4 KB
{kind=link}
11.5 KB
{kind=link}
4.6 KB
{kind=link}

12.8 KB
{kind=link}
7.8 KB
{kind=link}
12.0 KB
{kind=link}
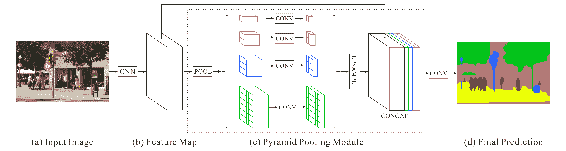
4.0 KB
{kind=link}

43.2 KB
{kind=link}

4.4 KB
{kind=link}

51.3 KB
{kind=link}
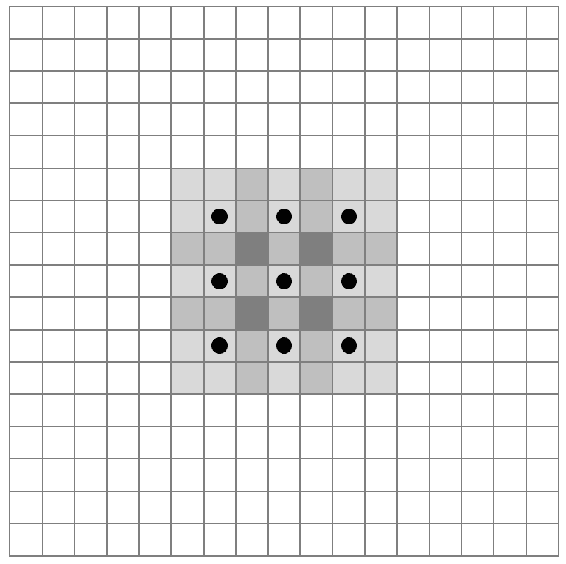
1.3 KB
{kind=link}
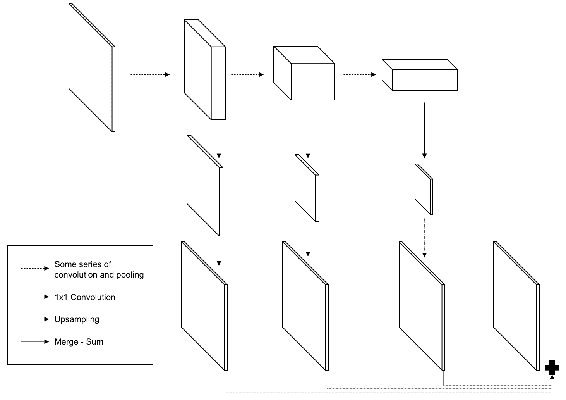
4.1 KB
{kind=link}
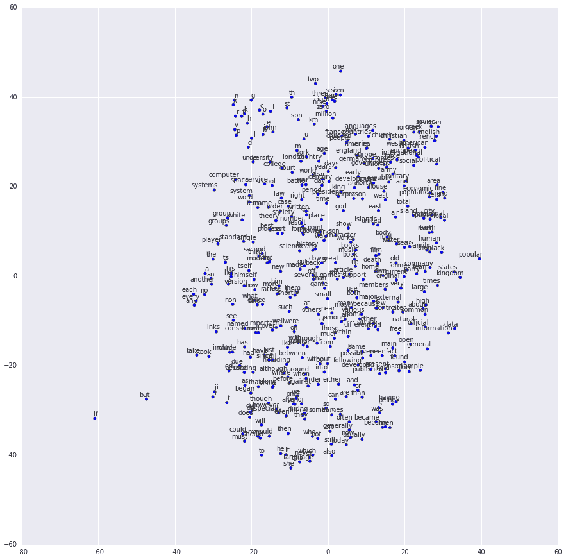
14.2 KB
{kind=link}
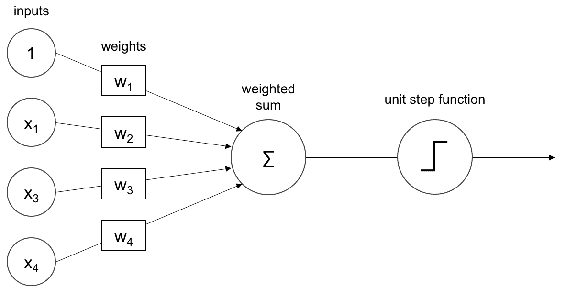
3.8 KB
{kind=link}
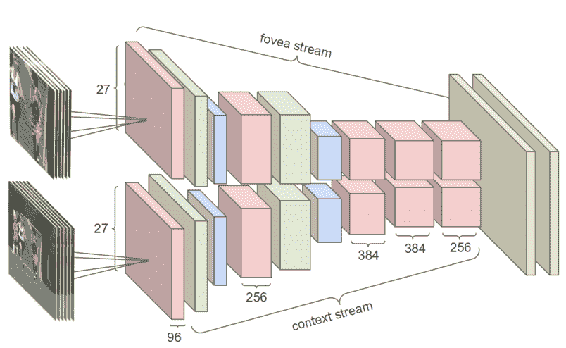
12.8 KB
{kind=link}

31.1 KB
{kind=link}
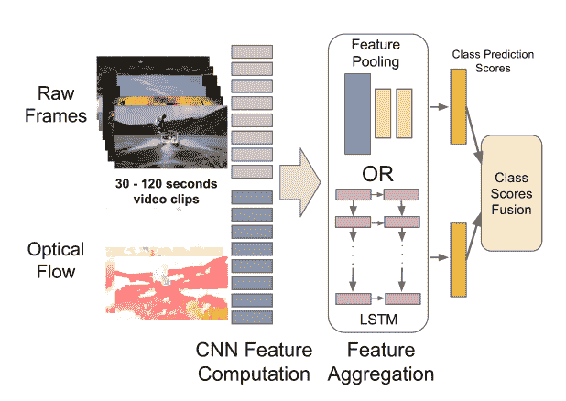
12.3 KB
{kind=link}

13.0 KB
{kind=link}
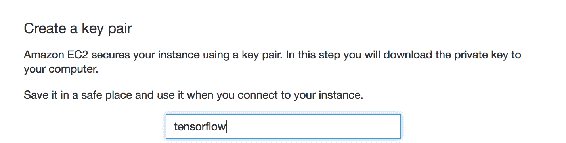
2.7 KB
{kind=link}

14.1 KB
{kind=link}

8.2 KB
{kind=link}
9.2 KB
{kind=link}
49.1 KB
{kind=link}

19.4 KB
{kind=link}
20.9 KB
{kind=link}
4.1 KB
{kind=link}
4.5 KB
{kind=link}
3.1 KB
{kind=link}
13.2 KB
{kind=link}
3.8 KB
{kind=link}
4.4 KB
{kind=link}
11.0 KB
{kind=link}
7.0 KB
{kind=link}
10.5 KB
{kind=link}
3.7 KB
{kind=link}
5.1 KB
{kind=link}
10.5 KB
{kind=link}

31.0 KB
{kind=link}
7.3 KB
{kind=link}

2.9 KB
{kind=link}

1.5 KB
{kind=link}
3.9 KB
{kind=link}
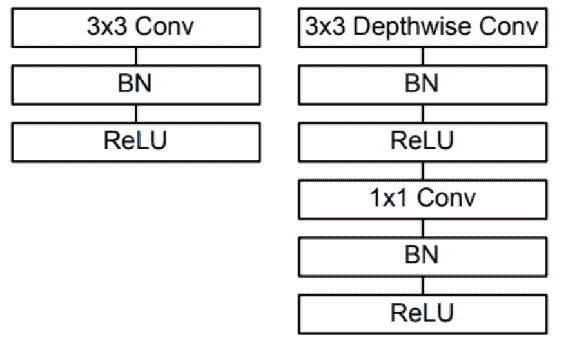
4.8 KB
{kind=link}
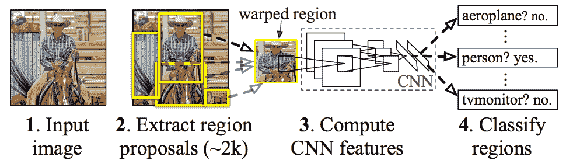
11.1 KB
{kind=link}

40.7 KB
{kind=link}
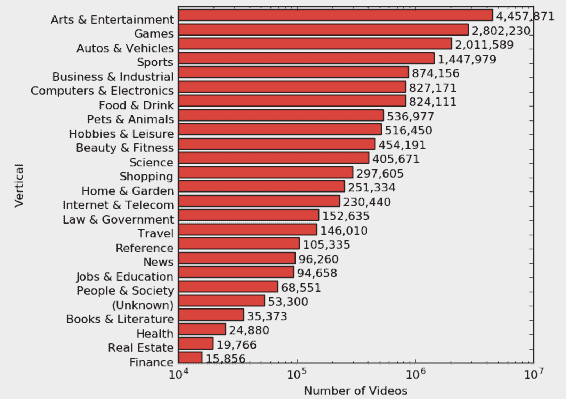
10.4 KB
{kind=link}
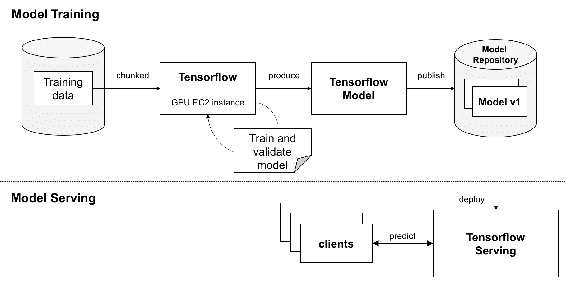
4.4 KB
{kind=link}
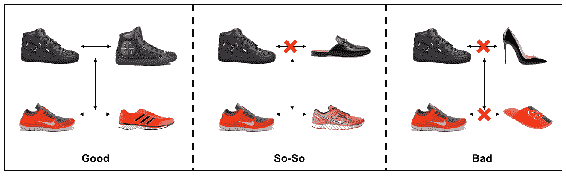
4.7 KB
{kind=link}

14.4 KB
{kind=link}
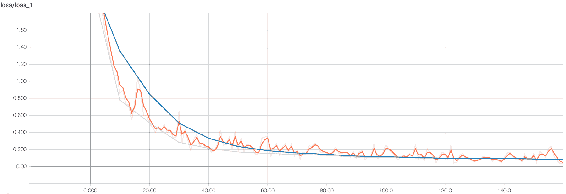
3.0 KB
{kind=link}
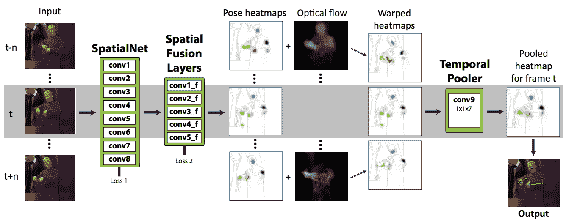
8.8 KB
{kind=link}
7.7 KB
{kind=link}

12.6 KB
{kind=link}

12.3 KB
{kind=link}
18.5 KB
{kind=link}
4.0 KB
{kind=link}
9.4 KB
{kind=link}
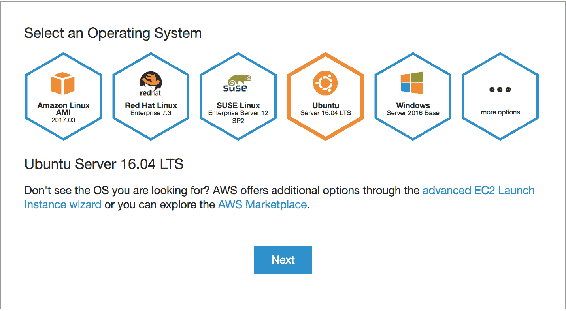
5.8 KB
{kind=link}
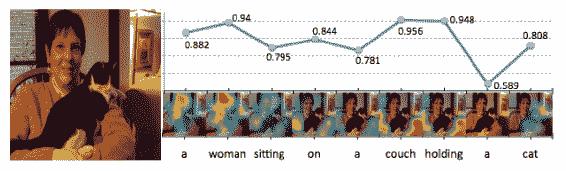
11.6 KB
{kind=link}

44.7 KB
{kind=link}
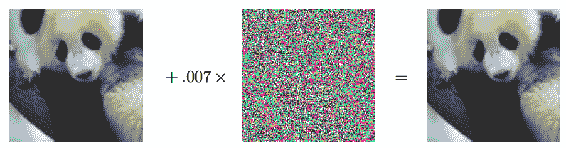
13.8 KB
{kind=link}
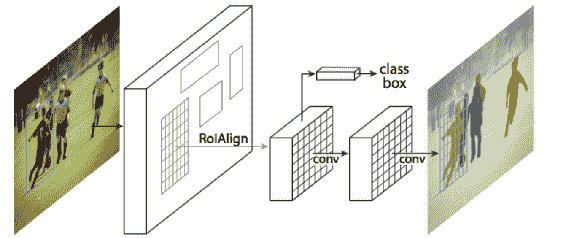
12.9 KB
{kind=link}
6.1 KB
{kind=link}
10.7 KB
{kind=link}
2.3 KB
{kind=link}
3.7 KB
{kind=link}
13.4 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。