Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
暴走的小小菜鸟
Paddle
提交
878e6f7c
P
Paddle
项目概览
暴走的小小菜鸟
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
878e6f7c
编写于
12月 19, 2017
作者:
Y
ying
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update the data organization part.
上级
1fb68e1e
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
134 addition
and
52 deletion
+134
-52
doc/howto/usage/capi/a_simple_example.md
doc/howto/usage/capi/a_simple_example.md
+4
-4
doc/howto/usage/capi/core_concepts.md
doc/howto/usage/capi/core_concepts.md
+0
-0
doc/howto/usage/capi/images/csr.png
doc/howto/usage/capi/images/csr.png
+0
-0
doc/howto/usage/capi/images/sequence_data.png
doc/howto/usage/capi/images/sequence_data.png
+0
-0
doc/howto/usage/capi/organization_of_the_inputs.md
doc/howto/usage/capi/organization_of_the_inputs.md
+129
-45
doc/howto/usage/capi/overview.md
doc/howto/usage/capi/overview.md
+1
-3
未找到文件。
doc/howto/usage/capi/a_simple_example.md
浏览文件 @
878e6f7c
...
...
@@ -115,15 +115,15 @@
-
`Argument`
并不真正“存储”数据,而是将输入/输出数据有机地组织在一起。
-
在
`Argument`
内部由:1.
`Matrix`
(二维矩阵,存储浮点类型输入/输出);2.
`IVector`
(一维数组,
**仅用于存储整型值**
,多用于自然语言处理任务)来实际存储数据。
*注:这篇文档使用的示例任务手写数字识别不涉及一维整型序列输入/输出,因此不讨论一维整型输入/输出数据相关的内容。更多信息请参考:[输入数据组织](organization_of_the_inputs.md)。*
*注:这篇文档使用的示例任务手写数字识别不涉及一维整型序列输入/输出,因此不讨论一维整型输入/输出数据相关的内容。更多信息请参考:[输入
/输出
数据组织](organization_of_the_inputs.md)。*
在这篇文档的后面部分,我们会使用
`argument`
来
**特指**
PaddlePaddle C-API中神经网的一个输入/输出,使用
`matrix`
**特指**
`argument`
中用于存储数据的
`Matrix`
类的对象,用
`ivector`
特指
`argument`
中用于存储数据的
`IVector
`
类的对象。
这篇文档的之后部分会使用
`argument`
来
**特指**
PaddlePaddle C-API中神经网的一个输入/输出,使用
`paddle_matrix`
**特指**
`argument`
中用于存储数据的
`Matrix
`
类的对象。
于是,在组织神经网络输入,获取输出时,需要思考完成以下工作:
1.
为每一个输入/输出创建
`argument`
;
1.
为每一个
`argument`
创建
`
matrix`
或者
`ivector
`
来存储数据;
1.
为每一个
`argument`
创建
`
paddle_matrix
`
来存储数据;
与输入不同的是,输出
`argument`
的
`
matrix`
变量并不需在使用C-API时为之要
分配存储空间。PaddlePaddle内部,神经网络进行前向计算时会自己分配/管理每个计算层的存储空间;这些细节C-API会代为处理,只需在概念上理解,并按照约定调用相关的 C-API 接口即可。
与输入不同的是,输出
`argument`
的
`
paddle_matrix`
变量并不需在使用C-API时为之
分配存储空间。PaddlePaddle内部,神经网络进行前向计算时会自己分配/管理每个计算层的存储空间;这些细节C-API会代为处理,只需在概念上理解,并按照约定调用相关的 C-API 接口即可。
下面是示例代码片段。在这段代码中,生成了一条随机输入数据作为测试样本。
```
c
...
...
doc/howto/usage/capi/core_concepts.md
已删除
100644 → 0
浏览文件 @
1fb68e1e
doc/howto/usage/capi/images/csr.png
查看替换文件 @
1fb68e1e
浏览文件 @
878e6f7c
170.3 KB
|
W:
|
H:
361.4 KB
|
W:
|
H:
2-up
Swipe
Onion skin
doc/howto/usage/capi/images/sequence_data.png
0 → 100644
浏览文件 @
878e6f7c
470.2 KB
doc/howto/usage/capi/organization_of_the_inputs.md
浏览文件 @
878e6f7c
...
...
@@ -13,40 +13,22 @@
1.
一维数组
**仅支持整型值**
;
-
常用于自然语言处理任务,例如:表示词语在词典中的序号;
-
分类任务中类别标签;
1.
逻辑上高于二维的数据(例如含有多个通道的图片,视频等)在程序实现中都会转化为二维矩阵,转化方法在相应的领域都有通用解决方案,需要使用者自己了解相关的转化表示方法;
1.
二维矩阵可以表示行向量和列向量,任何时候,如果需要浮点型数组(向量)时,都应使用C-API中的矩阵来表示,而不是C-API中的一维数组。
不论是一维整型数组还是二维浮点数矩阵,
**为它们附加上序列信息,将变成序列输入。PaddlePaddle 会通过判数据是否附带有序列信息来判断一个向量/矩阵是否是一个序列**
。关于什么是“序列信息”,下文会进行详细地介绍。
PaddlePaddle 支持两种序列类型:
1.
单层序列
-
序列中的每一个元素是非序列,是进行计算的基本单位,不可再进行拆分。
-
例如:自然语言中的句子是一个序列,序列中的元素是词语;
1.
双层序列
-
序列中的每一个元素又是一个序列。
-
例如:自然语言中的段落是一个双层序列;段落是有句子构成的序列;句子是由词语构成的序列。
-
双层序列在处理长序列的任务或是构建层级模型时会发挥作用。
1.
逻辑上高于二维的数据(例如含有多个通道的图片,视频等)在程序实现中都会转化为二维矩阵,转化方法在相应的领域都有通用解决方案,需要使用者自己了解并完成转化;
1.
二维矩阵可以表示行向量和列向量,任何时候如果需要浮点型数组(向量),都应使用C-API中的矩阵来表示,而不是C-API中的一维数组。
1.
不论是一维整型数组还是二维浮点数矩阵,
**为它们附加上序列信息将变成序列输入。PaddlePaddle 会通过判数据是否附带有序列信息来判断一个向量/矩阵是否是一个序列**
。当非序列输入时,无需关心和处理序列信息。关于什么是“序列信息”,下文会详细进行介绍。
### 基本使用概念
-
在PaddlePaddle内部,神经网络中一个计算层的输入/输出被组织为一个
`Argument`
结构体,如果神经网络有多个输入或者多个输入,每一个输入/输入都会对应有自己的
`Argument`
。
-
`Argument`
并不真正“存储”数据,而是将输入/输出信息有机地组织在一起。
-
在
`Argument`
内部由
`IVector`
(对应着上文提到的一维整型数组)和
`Matrix`
(对应着上文提到的二维浮点型矩阵)来实际存储数据;由
`
sequence start position`
(下文详细解释) 来记录
输入/输出的序列信息。
-
在
`Argument`
内部由
`IVector`
(对应着上文提到的一维整型数组)和
`Matrix`
(对应着上文提到的二维浮点型矩阵)来实际存储数据;由
`
Sequence Start Positions`
(下文详细解释) 来描述
输入/输出的序列信息。
**注意:这篇文档之后部分将会统一使用`argument`来特指PaddlePaddle中神经网络计算层一个输入/输出数据;使用`ivector`来特指PaddlePaddle中的一维整型数组;使用`matrix`来特指PaddlePaddle中的二维浮点型矩阵;使用`sequence_start_position`来特指PaddlePaddle中的序列信息。**
-
**注**
:
1.
这篇文档之后部分将会统一使用
`argument`
来特指PaddlePaddle中神经网络计算层一个输入/输出数据。
2.
使用
`paddle_ivector`
来特指PaddlePaddle中的一维整型数组。
3.
使用
`paddle_matrix`
来特指PaddlePaddle中的二维浮点型矩阵。
于是,在组织神经网络输入时,需要思考完成以下工作:
1.
为每一个输入/输出创建
`argument`
。
-
C-API 中操作
`argument`
的接口请查看
[
argument.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h
)
。
1.
为每一个
`argument`
创建
`matrix`
或者
`ivector`
来存储数据。
-
C-API 中操作
`ivector`
的接口请查看
[
vector.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/vector.h
)
。
-
C-API 中操作
`matrix`
的接口请查看
[
matrix.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/matrix.h
)
。
1.
如果输入是序列数据,需要创建并填写
`sequence_start_position`
信息。
-
通过调用
[
`paddle_arguments_set_sequence_start_pos`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h#L137
)
来为一个
`argument`
添加序列信息;
-
通过调用
[
`paddle_arguments_get_sequence_start_pos`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h#L150
)
来读取一个
`argument`
添加序列信息;
-
接口说明请查看
[
argument.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h
)
文件。
### 组织非序列数据
### 组织输入数据
-
一维整型数组
概念上可以将`paddle_ivector`理解为一个一维的整型数组,通常用于表示离散的类别标签,或是在自然语言处理任务中表示词语在字典中的序号。下面的代码片段创建了含有三个元素`1`、`2`、`3`的`paddle_ivector`。
...
...
@@ -56,6 +38,7 @@ PaddlePaddle 支持两种序列类型:
paddle_ivector_create(ids, sizeof(ids) / sizeof(int), false, false);
CHECK(paddle_arguments_set_ids(in_args, 0, ids_array));
```
-
**稠密矩阵**
-
一个$m×n$的稠密矩阵是一个由$m$行$n$列元素排列成的矩形阵列,矩阵里的元素是浮点数。对神经网络来说,矩阵的高度$m$是一次预测接受的样本数目,宽度$n$是神经网络定义时,
`paddle.layer.data`
的
`size`
。
-
下面的代码片段创建了一个高度为1,宽度为
`layer_size`
的稠密矩阵,矩阵中每个元素的值随机生成。
...
...
@@ -83,17 +66,20 @@ PaddlePaddle 支持两种序列类型:
-
**稀疏矩阵**
PaddlePaddle C-API 中 稀疏矩阵使用
[
CSR(Compressed Sparse Row Format)
](
https://en.wikipedia.org/wiki/Sparse_matrix#Compressed_sparse_row_(CSR,_CRS_or_Yale_format
)
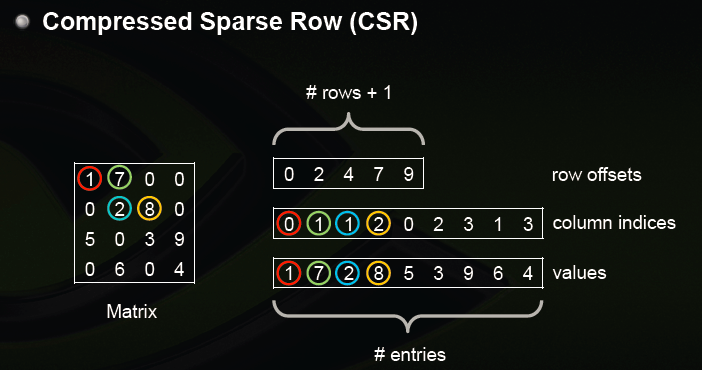
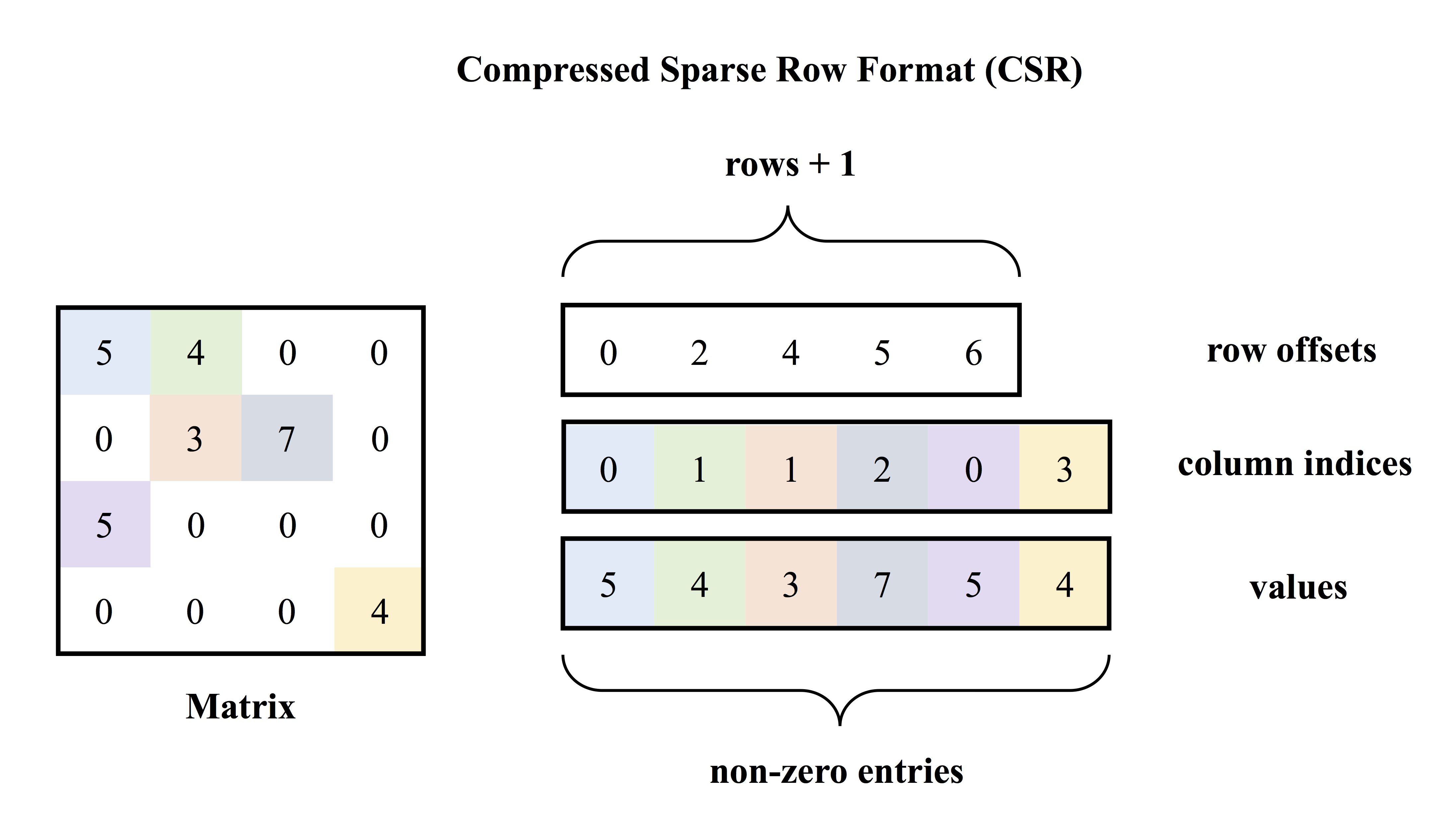
)格式存储。下图是CSR存储稀疏矩阵的示意图
,在CSR表示方式中,通过(1)行偏移;(2)列号;(3)值;来决定矩阵的内容
。
PaddlePaddle C-API 中 稀疏矩阵使用
[
CSR(Compressed Sparse Row Format)
](
https://en.wikipedia.org/wiki/Sparse_matrix#Compressed_sparse_row_(CSR,_CRS_or_Yale_format
)
)格式存储。下图是CSR存储稀疏矩阵的示意图。
<p
align=
"center"
>
<img
src=
"images/csr.png"
width=
7
5
%
></br>
图1. CSR存储示意图.
<img
src=
"images/csr.png"
width=
7
0
%
></br>
图1. CSR存储示意图.
</p>
在PaddlePaddle C-API中通过以下接口创建稀疏矩阵:
CSR存储格式通过:(1)非零元素的值(上图中的
`values`
);(2)行偏移(上图中的
`row offsets`
):每一行元素在
`values`
中的起始偏移,
`row offsets`
中元素个数总是等于行数 + 1;(3)非零元素的列号(上图中的
`column indices`
)来确定稀疏矩阵的内容。
在PaddlePaddle C-API中,通过调用以下接口创建稀疏矩阵:
```
cpp
PD_API
paddle_matrix
paddle_matrix_create_sparse
(
uint64_t
height
,
uint64_t
width
,
uint64_t
nnz
,
bool
isBinary
,
bool
useGpu
);
```
1.
创建稀疏矩阵时需要显示地指定矩阵的(1)高度(
`height`
,在神经网络中等于一次预测处理的样本数)(2)宽度(
`width`
,
`paddle.layer.data`
的
`size`
)以及(3)非零元个数(
`nnz`
)。
1.
当上述接口第4个参数
`isBinary`
指定为
`true`
时,
**只需要设置行偏移(`row_offset`)和列号(`colum indices`),不需要提供元素值(`values`)**
,这时行偏移和列号指定的元素默认其值为1。
...
...
@@ -129,26 +115,124 @@ PaddlePaddle 支持两种序列类型:
sizeof
(
values
)
/
sizeof
(
float
)));
```
### 组织序列数据
-
注意事项:
1.
移动端预测
**不支持**
稀疏矩阵及相关的接口。
### 组织序列信息
多个排成一列的元素(可以是整型、浮点数、浮点数向量等)构成一个序列,元素之间的顺序是序列所携带的重要信息。不同序列可能会含有不同数目个元素。在 PaddlePaddle 中,序列输入/输出数据是在上文介绍的
**数据输入(一维整型数组,二维浮点数矩阵)基础上,附加上序列信息**
。下面详细解释什么是“序列信息”。
### Python 端数据类型说明
我们将神经网络一次计算接受的所有输入样本称之为一个
`batch`
(可以含有一条或多条样本),每一个序列在整个
`batch`
中的偏移,就是PaddlePaddle中所指的
**序列信息**
,称之为“sequence start positions”。PaddlePaddle 支持两种序列类型:
下表列出了Python端训练接口暴露的数据类型(
`paddle.layer.data`
函数
`type`
字段的取值)对应于调用C-API时需要创建的数据类型:
1.
单层序列
-
序列中的每一个元素是非序列,是进行计算的基本单位,不可再进行拆分。
-
例如:自然语言中的句子是一个序列,序列中的元素是词语;
1.
双层序列
-
序列中的每一个元素又是一个序列。
-
例如:自然语言中的段落是一个双层序列;段落是由句子构成的序列;句子是由词语构成的序列。
-
双层序列在处理长序列的任务或是构建层级模型时会发挥作用。
这篇文档之后部分会统一使用
`sequence_start_positions`
来特指:PaddlePaddle中神经网络计算层输入/输出所携带的序列信息。
对双层序列来讲,不仅要提供每一个外层序列在整个
`batch`
中的偏移,每一个外层序列又含有若干个内层序列,需要同时提供每一个内层序列在整个
`batch`
中的偏移。也就是说:
**双层序列需要设置分别为外层序列和内层序列分别设置`sequence_start_positions`信息**
。
**注:**
1.
不论序列中的元素在内存中占用多少实际存储空间,
`sequence_start_positions`
表示的偏移是以“序列中的一个元素”作为统计的基本单位,而不是相对
`batch`
起始存储地址以数据的存储大小为单位的偏移。
2.
非序列输入不携带
`sequence_start_positions`
,非序列输入无需构造
`sequence_start_positions`
。
3.
**不论是单层序列还是双层序列的序列信息,都使用`paddle_ivector`(也就是PaddlePaddle中的一维整型数组)来存储。**
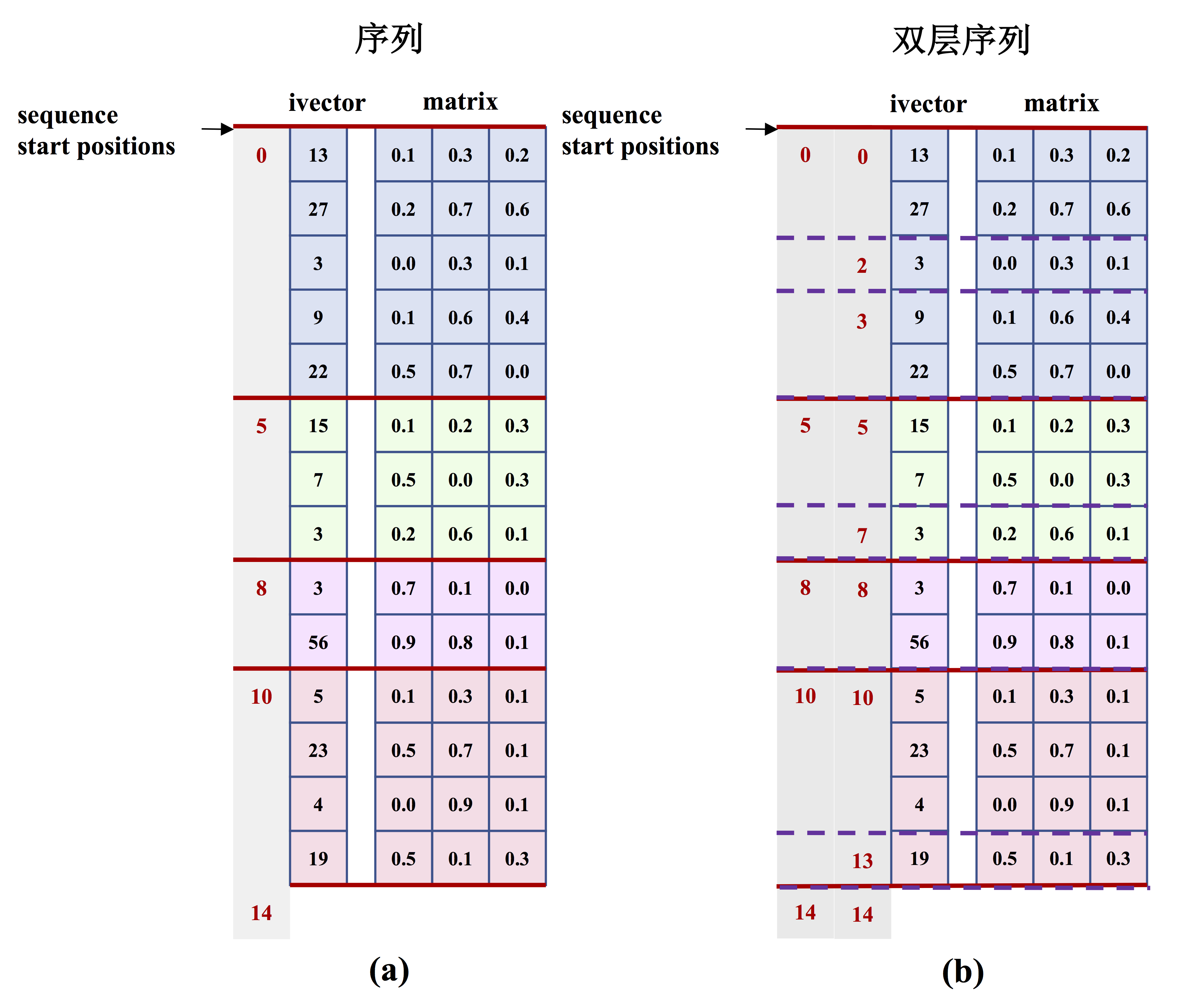
图2 是PaddlePaddle中单层序列和双层序列存储示意图。
<p
align=
"center"
>
<img
src=
"images/sequence_data.png"
width=
80%
></br>
图2. 序列输入示意图.
</p>
-
单层序列
图2 (a) 展示了一个含有4个序列的`batch`输入:
1. 4个序列的长度分别为:5、3、2、4;
2. 这时的`sequence_start_positions`为:`[0, 5, 8, 10, 14]`;
3. 不论数据域是`paddle_ivector`类型还是`paddle_matrix`类型,都可以通过调用下面的接口为原有的数据输入附加上序列信息,使之变为一个单层序列输入,代码片段如下:
```cpp
int seq_pos_array[] = {0, 5, 8, 10, 14};
paddle_ivector seq_pos = paddle_ivector_create(
seq_pos_array, sizeof(seq_pos_array) / sizeof(int), false, false);
// Suppose the network only has one input data layer.
CHECK(paddle_arguments_set_sequence_start_pos(in_args, 0, 0, seq_pos));
```
-
双层序列
图2 (b) 展示了一个含有4个序列的`batch`输入;
1. 4个序列的长度分别为:5、3、2、4;这四个序列又分别含有3、2、1、2个子序列;
1. 这时的需要同时提供:
- 1. 外层序列在`batch`中的起始偏移`:[0, 5, 8, 10, 14]`;
- 2. 内层序列在`batch`中的起始偏移:`[0, 2, 3, 5, 7, 8, 10, 13, 14]`;
1. 不论数据域是`paddle_ivector`类型还是`paddle_matrix`类型,这时需要调用创建序列信息和为`argument`设置序列信息的接口**两次**,分别为数据输入添加外层序列和内层序列的序列信息,使之变为一个双层序列输入,代码片段如下:
```cpp
// set the sequence start positions for the outter sequences.
int outter_seq_pos_array[] = {0, 5, 8, 10, 14};
paddle_ivector seq_pos =
paddle_ivector_create(outter_seq_pos_array,
sizeof(outter_pos_array) / sizeof(int),
false,
false);
// The third parameter of this API indicates the sequence level.
// 0 for the outter sequence. 1 for the inner sequence.
// If the input is a sequence not the nested sequence, the third parameter is
// fixed to be 0.
CHECK(paddle_arguments_set_sequence_start_pos(in_args, 0, 0, seq_pos));
// set the sequence start positions for the outter sequences.
int inner_seq_pos_array[] = {0, 2, 3, 5, 7, 8, 10, 13, 14};
paddle_ivector seq_pos = paddle_ivector_create(
inner_pos_array, sizeof(inner_pos_array) / sizeof(int), false, false);
// The third parameter of this API indicates the sequence level.
// 0 for the outter sequence. 1 for the inner sequence.
CHECK(paddle_arguments_set_sequence_start_pos(in_args, 0, 1, seq_pos));
```
-
注意事项:
1.
当一个
`batch`
中含有多个序列,
**不支持序列长度为`0`的序列(也就是空输入)**
作为输入。不同计算层对空输入的处理策略有可能不同,潜在会引起未定义行为,或者引起行时错误,请在输入时进行合法性检查。
### Python 端数据类型说明
下表列出了Python端训练接口暴露的数据类型(
`paddle.layer.data`
函数
`type`
字段的取值)对应于调用C-API需要创建的数据类型:
Python 端数据类型 | C-API 输入数据类型|
:-------------: | :-------------:
`paddle.data_type.integer_value`
|一维整型数组,无需附加序列信息|
`paddle.data_type.dense_vector`
|二维浮点型稠密矩阵,无需附加序列信息|
`paddle.data_type.sparse_binary_vector`
|二维浮点型稀疏矩阵,无需提供非零元的值,默认为1,无需附加序列信息|
`paddle.data_type.sparse_vector`
|二维浮点型稀疏矩阵,需提供非零元的值,无需附加序列信息|
`paddle.data_type.integer_value_sequence`
|一维整型数组,需附加序列信息|
`paddle.data_type.dense_vector_sequence`
|二维浮点型稠密矩阵,需附加序列信息|
`paddle.data_type.sparse_binary_vector_sequence`
|二维浮点型稀疏矩阵,无需提供非零元的值,默认为1,需附加序列信息|
`paddle.data_type.sparse_vector_sequence`
|二维浮点型稀疏矩阵,需提供非零元的值,需附加序列信息|
`paddle.data_type.integer_value_sub_sequence`
|一维整型数组,需附加双层序列信息|
`paddle.data_type.dense_vector_sub_sequence`
|二维浮点型稠密矩阵,需附加双层序列信息|
`paddle.data_type.sparse_binary_vector_sub_sequence`
|二维浮点型稀疏矩阵,无需提供非零元的值,默认为1,需附加双层序列信息|
`paddle.data_type.sparse_vector_sub_sequence`
|二维浮点型稀疏矩阵,需提供非零元的值,需附加双层序列信息|
`paddle.data_type.integer_value`
|整型数组,无需附加序列信息|
`paddle.data_type.dense_vector`
|浮点型稠密矩阵,无需附加序列信息|
`paddle.data_type.sparse_binary_vector`
|浮点型稀疏矩阵,无需提供非零元的值,默认为1,无需附加序列信息|
`paddle.data_type.sparse_vector`
|浮点型稀疏矩阵,需提供非零元的值,无需附加序列信息|
`paddle.data_type.integer_value_sequence`
|整型数组,需附加序列信息|
`paddle.data_type.dense_vector_sequence`
|浮点型稠密矩阵,需附加序列信息|
`paddle.data_type.sparse_binary_vector_sequence`
|浮点型稀疏矩阵,无需提供非零元的值,默认为1,需附加序列信息|
`paddle.data_type.sparse_vector_sequence`
|浮点型稀疏矩阵,需提供非零元的值,需附加序列信息|
`paddle.data_type.integer_value_sub_sequence`
|整型数组,需附加双层序列信息|
`paddle.data_type.dense_vector_sub_sequence`
|浮点型稠密矩阵,需附加双层序列信息|
`paddle.data_type.sparse_binary_vector_sub_sequence`
|浮点型稀疏矩阵,无需提供非零元的值,默认为1,需附加双层序列信息|
`paddle.data_type.sparse_vector_sub_sequence`
|浮点型稀疏矩阵,需提供非零元的值,需附加双层序列信息|
### 输出数据
PaddlePaddle中一个计算层的输出数据组织方式和输入数据组织方式完全相同。一个输出数据同样被组织为一个
`argument`
,
`argument`
通过
`paddle_matrix`
或
`paddle_ivector`
存数数据,如果输出是一个序列,那么会携带有
`sequence_start_positions`
信息。调用C-API相关接口,读取需要的结果即可。
### 总结
-
在PaddlePaddle内部,神经网络中一个计算层的输入/输出被组织为
`argument`
。
-
`argument`
并不真正“存储”数据,而是将输入/输出信息有机地组织在一起。
-
在
`argument`
内部由
`paddle_ivector`
(一维整型数组)和
`paddle_matrix`
(二维浮点型矩阵)来实际存储数据。
如果是一个序列输入/输出由
`sequence start positions`
来记录输入/输出的序列信息。
于是,在组织神经网络输入时,需要思考完成以下工作:
1.
为每一个输入/输出创建
`argument`
。
-
C-API 中操作
`argument`
的接口请查看
[
argument.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h
)
。
1.
为每一个
`argument`
创建
`paddle_matrix`
或者
`paddle_ivector`
来存储数据。
-
C-API 中操作
`paddle_ivector`
的接口请查看
[
vector.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/vector.h
)
。
-
C-API 中操作
`paddle_matrix`
的接口请查看
[
matrix.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/matrix.h
)
。
1.
如果输入是序列数据,需要创建并填写
`sequence_start_positions`
信息。
-
通过调用
[
`paddle_arguments_set_sequence_start_pos`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h#L137
)
来为一个
`argument`
添加序列信息。
-
通过调用
[
`paddle_arguments_get_sequence_start_pos`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h#L150
)
来读取一个
`argument`
添加序列信息。
-
接口说明请查看
[
argument.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h
)
文件。
doc/howto/usage/capi/overview.md
浏览文件 @
878e6f7c
-
[
编译 PaddlePaddle 链接库
](
compile_paddle_lib.md
)
-
[
输入/输出数据组织
](
organization_of_the_inputs.md
)
-
[
C-API 使用示例
](
a_simple_example.md
)
-
[
输入数据组织
](
organize_input_data.md
)
-
[
核心概念介绍
](
core_concepts.md
)
-
[
F&Q
](
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}