docs: Updates to Superset Site for 1.0 (#12626)
* incorporating precommit logic * add 1.0 page * fixed annoying docz config issue 2 * tweaked indentation * added asf link 2 * changed Dockerhub link * reverted frontend package lock json: precommit
{kind=link}
90.0 KB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

78.7 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

140.4 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
151.4 KB
{kind=link}

307.5 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
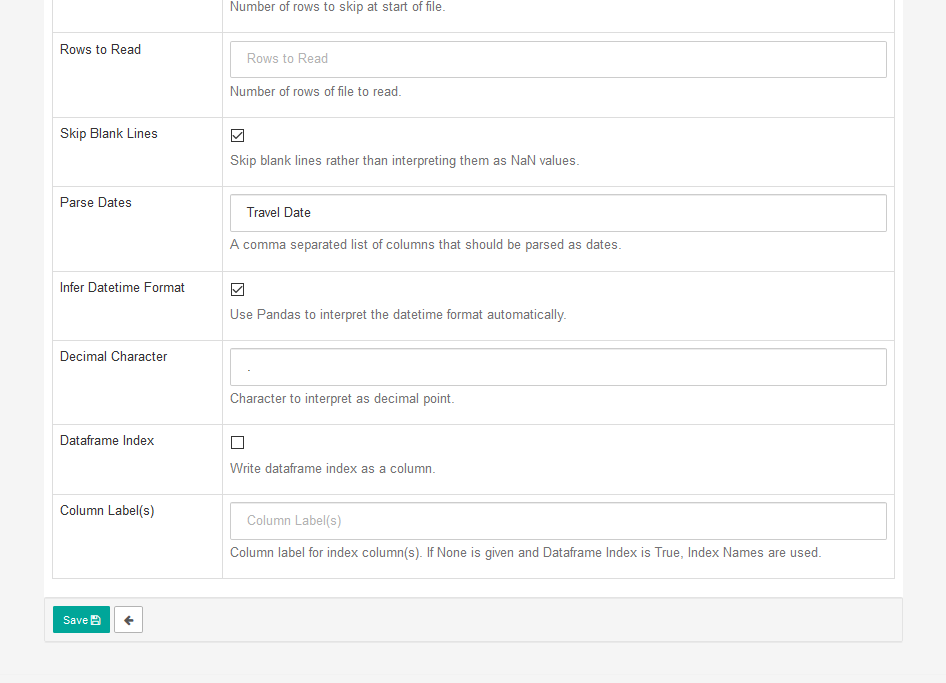
| W: | H:
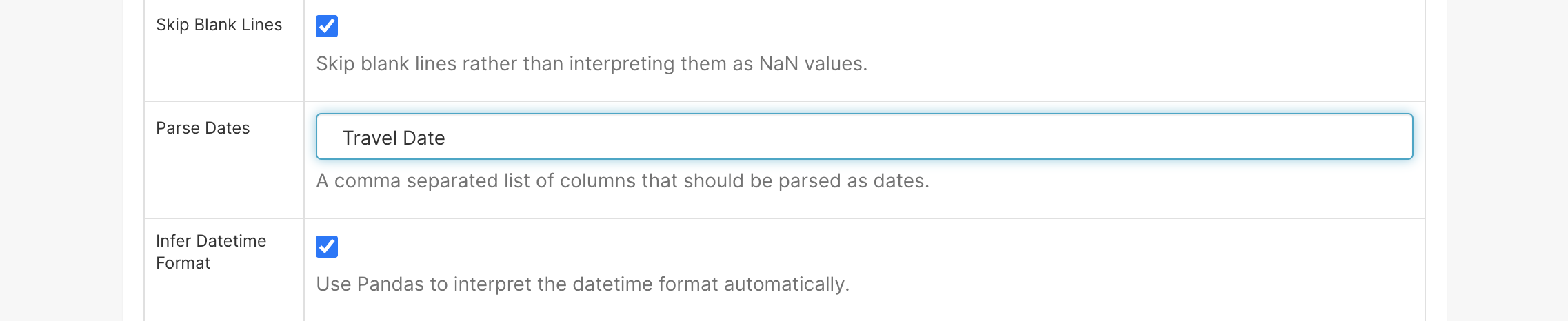
| W: | H:
{kind=link}
{kind=link}
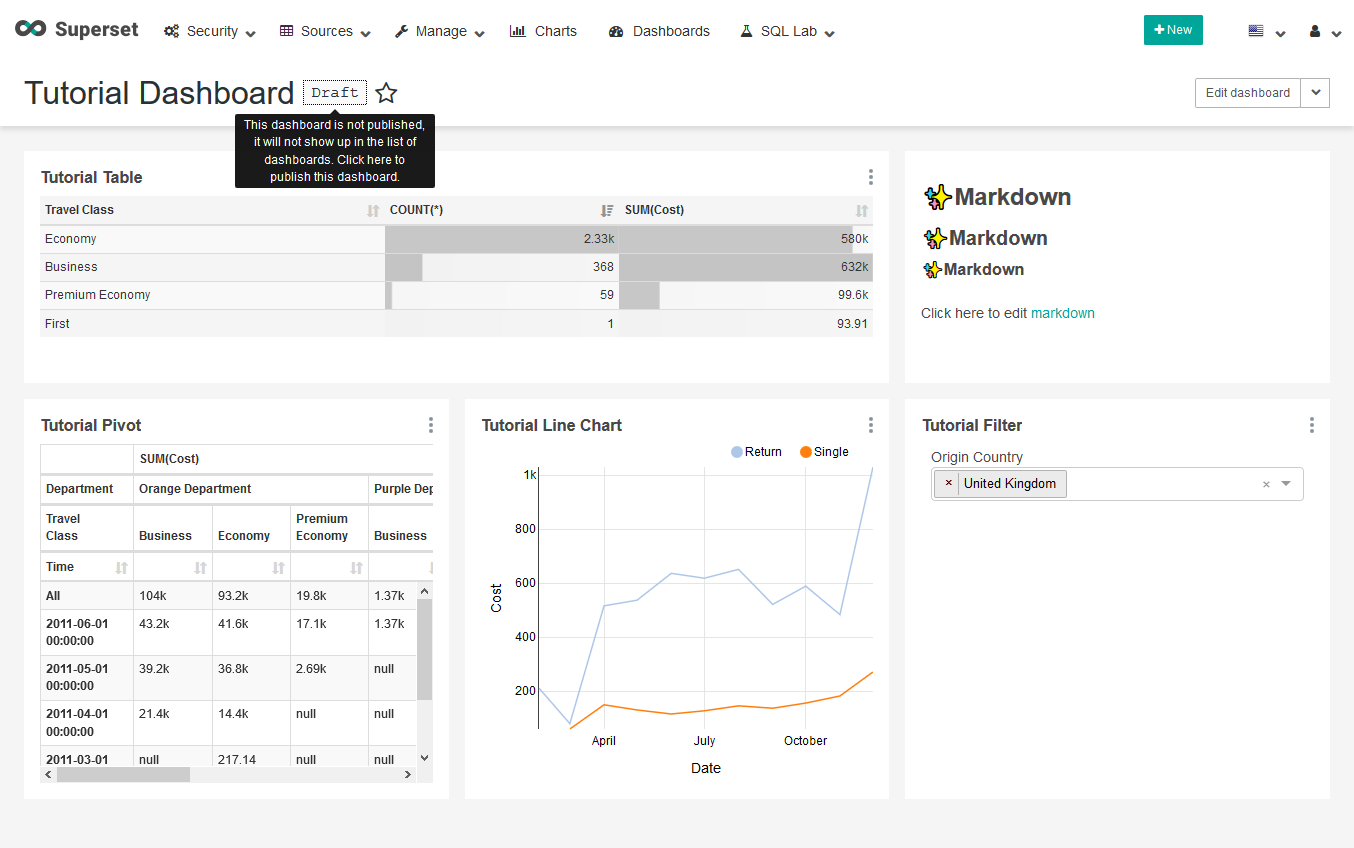
| W: | H:
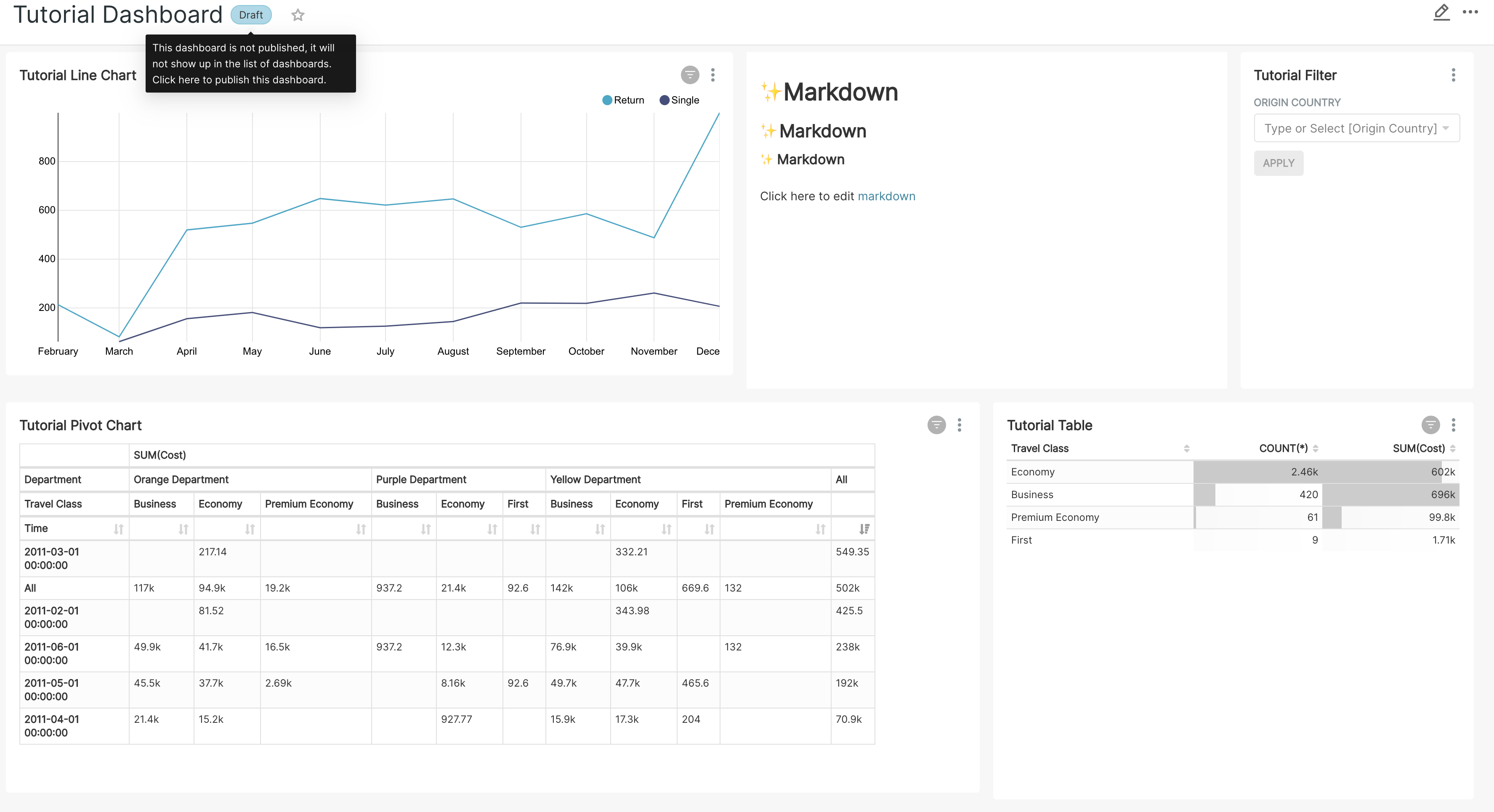
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

337.4 KB
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:
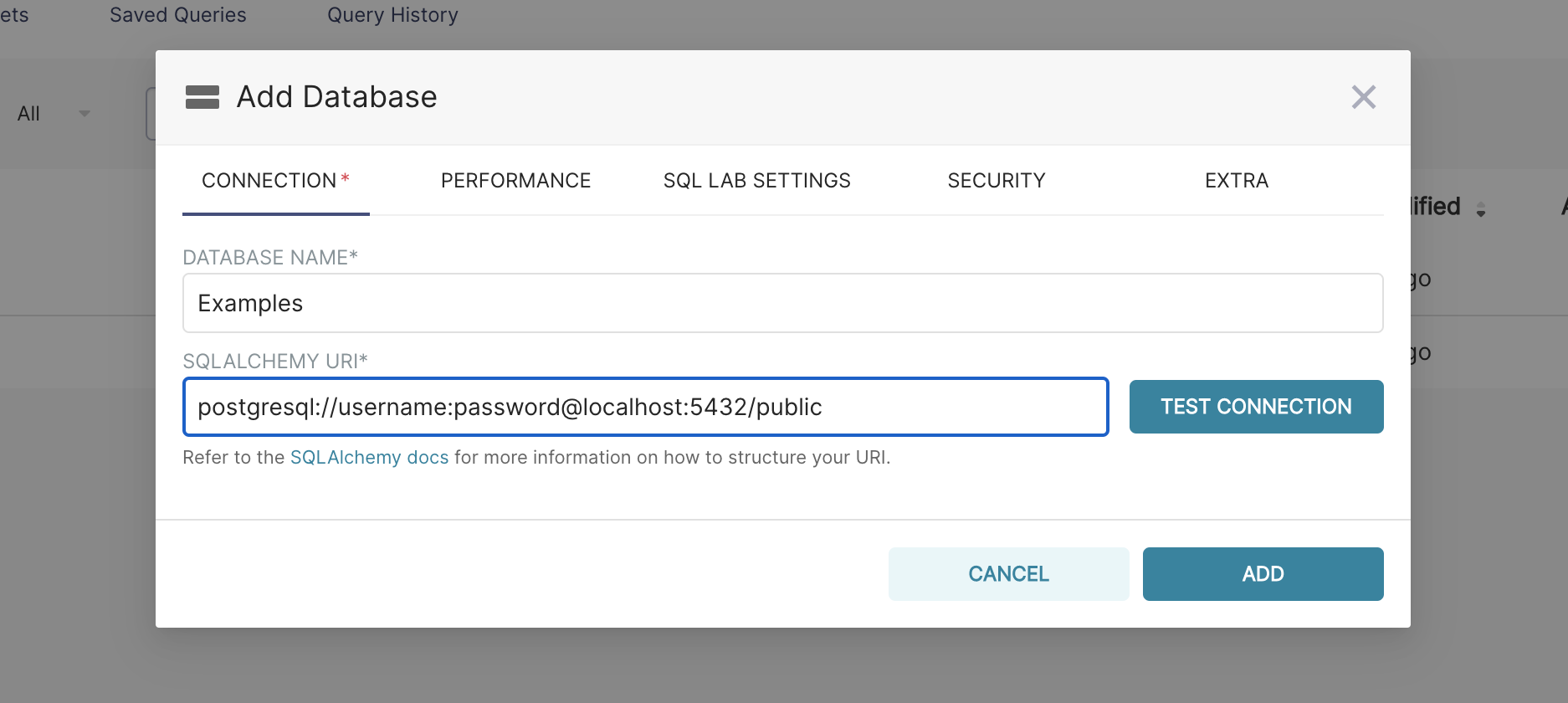
| W: | H:
{kind=link}
42.8 KB
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

273.5 KB
{kind=link}
154.3 KB
{kind=link}
371.9 KB
{kind=link}
359.4 KB
{kind=link}
377.6 KB
{kind=link}
147.4 KB
{kind=link}

92.3 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

17.7 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
141.1 KB
{kind=link}

311.2 KB
{kind=link}
{kind=link}
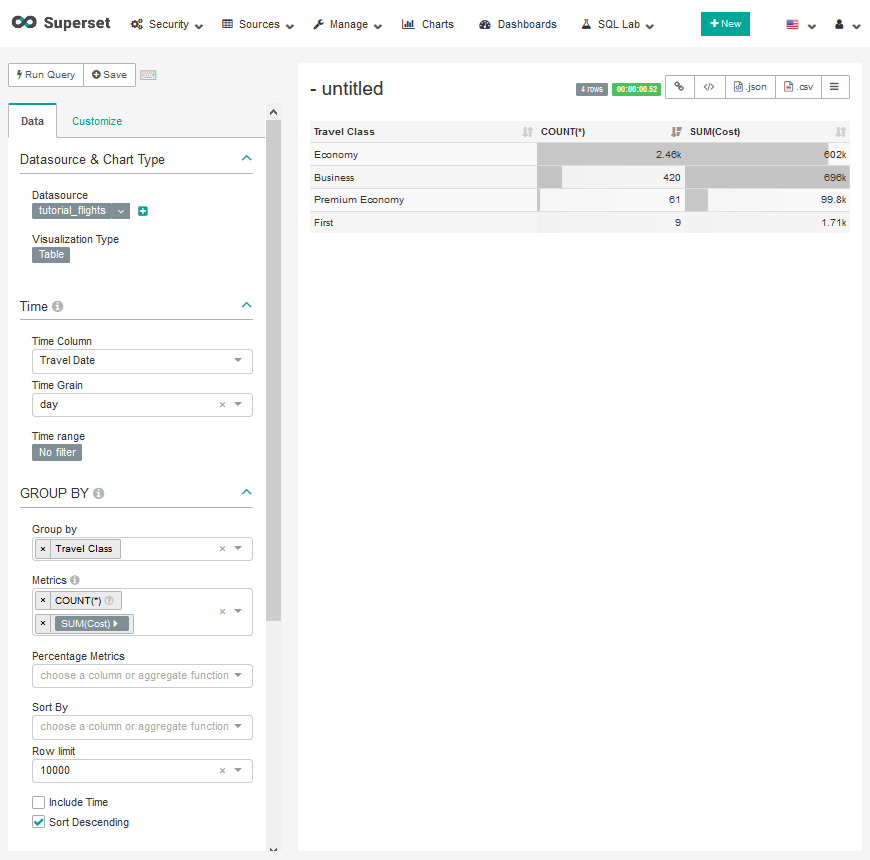
| W: | H:
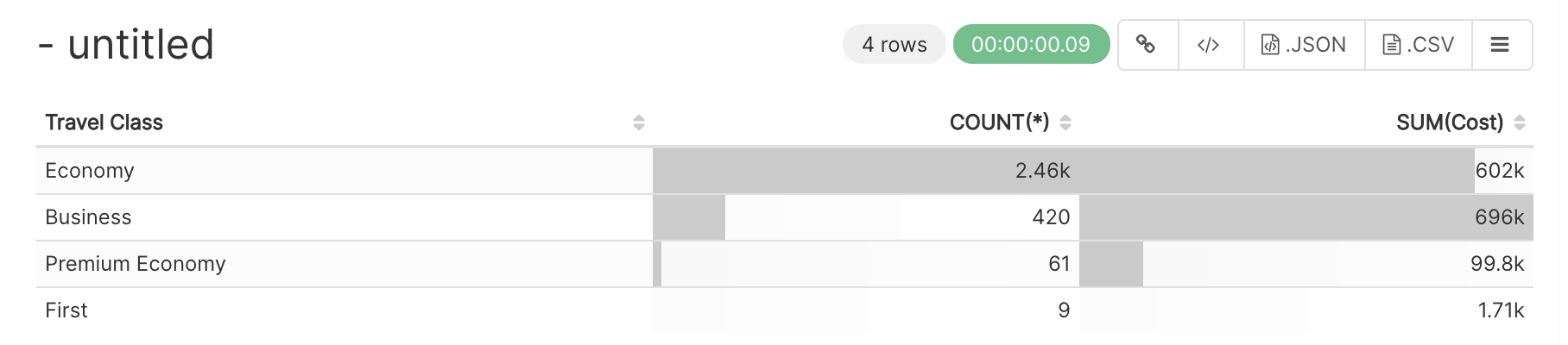
| W: | H:
{kind=link}
{kind=link}
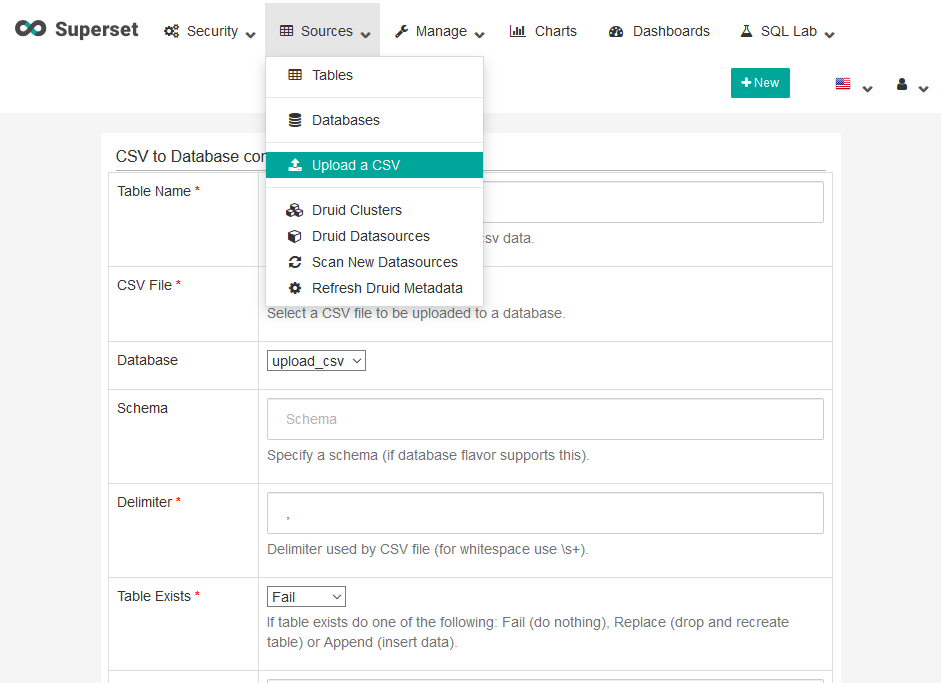
| W: | H:
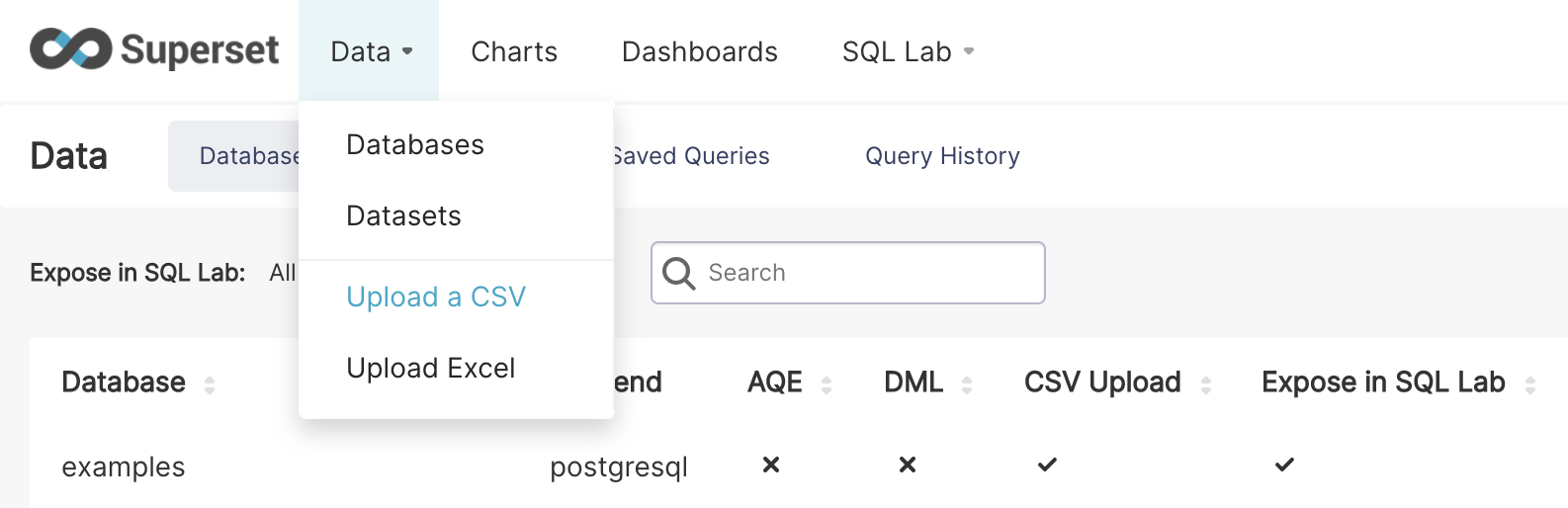
| W: | H: