Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
不正经的廖老师
Python-100-Days
提交
a259a6ab
P
Python-100-Days
项目概览
不正经的廖老师
/
Python-100-Days
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python-100-Days
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
a259a6ab
编写于
1月 11, 2022
作者:
骆昊的技术专栏
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新了日志
上级
e13f27be
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
439 addition
and
0 deletion
+439
-0
Day66-80/09.Pandas的应用-5.md
Day66-80/09.Pandas的应用-5.md
+433
-0
res/ABF827024EA535099DC0E6A66A336C51.png
res/ABF827024EA535099DC0E6A66A336C51.png
+0
-0
更新日志.md
更新日志.md
+6
-0
未找到文件。
Day66-80/09.Pandas的应用-5.md
0 → 100644
浏览文件 @
a259a6ab
## Pandas的应用-5
### DataFrame的应用
#### 窗口计算
`DataFrame`
对象的
`rolling`
方法允许我们将数据置于窗口中,然后就可以使用函数对窗口中的数据进行运算和处理。例如,我们获取了某只股票近期的数据,想制作5日均线和10日均线,那么就需要先设置窗口再进行运算。我们可以使用三方库
`pandas-datareader`
来获取指定的股票在某个时间段内的数据,具体的操作如下所示。
安装
`pandas-datareader`
三方库。
```
Bash
pip install pandas-datareader
```
通过
`pandas-datareader`
提供的
`get_data_stooq`
从 Stooq 网站获取百度(股票代码:BIDU)近期股票数据。
```
Python
import pandas_datareader as pdr
baidu_df = pdr.get_data_stooq('BIDU', start='2021-11-22', end='2021-12-7')
baidu_df.sort_index(inplace=True)
baidu_df
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208205710.png"
style=
"zoom:38%;"
>
上面的
`DataFrame`
有
`Open`
、
`High`
、
`Low`
、
`Close`
、
`Volume`
五个列,分别代表股票的开盘价、最高价、最低价、收盘价和成交量,接下来我们对百度的股票数据进行窗口计算。
```
Python
baidu_df.rolling(5).mean()
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208205932.png"
style=
"zoom:38%;"
>
上面的
`Close`
列的数据就是我们需要的5日均线,当然,我们也可以用下面的方法,直接在
`Close`
列对应的
`Series`
对象上计算5日均线。
```
Python
baidu_df.Close.rolling(5).mean()
```
输出:
```
Date
2021-11-22 NaN
2021-11-23 NaN
2021-11-24 NaN
2021-11-26 NaN
2021-11-29 150.608
2021-11-30 151.014
2021-12-01 150.682
2021-12-02 150.196
2021-12-03 147.062
2021-12-06 146.534
2021-12-07 146.544
Name: Close, dtype: float64
```
#### 相关性判定
在统计学中,我们通常使用协方差(covariance)来衡量两个随机变量的联合变化程度。如果变量 $X$ 的较大值主要与另一个变量 $Y$ 的较大值相对应,而两者较小值也相对应,那么两个变量倾向于表现出相似的行为,协方差为正。如果一个变量的较大值主要对应于另一个变量的较小值,则两个变量倾向于表现出相反的行为,协方差为负。简单的说,协方差的正负号显示着两个变量的相关性。方差是协方差的一种特殊情况,即变量与自身的协方差。
$$
cov(X,Y) = E((X -
\m
u)(Y -
\u
psilon)) = E(X
\c
dot Y) -
\m
u
\u
psilon
$$
如果 $X$ 和 $Y$ 是统计独立的,那么二者的协方差为0,这是因为在 $X$ 和 $Y$ 独立的情况下:
$$
E(X
\c
dot Y) = E(X)
\c
dot E(Y) =
\m
u
\u
psilon
$$
协方差的数值大小取决于变量的大小,通常是不容易解释的,但是正态形式的协方差可以显示两变量线性关系的强弱。在统计学中,皮尔逊积矩相关系数就是正态形式的协方差,它用于度量两个变量 $X$ 和 $Y$ 之间的相关程度(线性相关),其值介于
`-1`
到
`1`
之间。
$$
\r
ho{X,Y} =
\f
rac {cov(X, Y)} {
\s
igma_{X}
\s
igma_{Y}}
$$
估算样本的协方差和标准差,可以得到样本皮尔逊系数,通常用希腊字母 $
\r
ho$ 表示。
$$
\r
ho =
\f
rac {
\s
um_{i=1}^{n}(X_i -
\b
ar{X})(Y_i -
\b
ar{Y})} {
\s
qrt{
\s
um_{i=1}^{n}(X_i -
\b
ar{X})^2}
\s
qrt{
\s
um_{i=1}^{n}(Y_i -
\b
ar{Y})^2}}
$$
我们用 $
\r
ho$ 值判断指标的相关性时遵循以下两个步骤。
1.
判断指标间是正相关、负相关,还是不相关。
-
当 $
\r
ho
\g
t 0 $,认为变量之间是正相关,也就是两者的趋势一致。
-
当 $
\r
ho
\l
t 0 $,认为变量之间是负相关,也就是两者的趋势相反。
-
当 $
\r
ho = 0 $,认为变量之间是不相关的,但并不代表两个指标是统计独立的。
2.
判断指标间的相关程度。
-
当 $
\r
ho $ 的绝对值在 $ [0.6,1] $ 之间,认为变量之间是强相关的。
-
当 $
\r
ho $ 的绝对值在 $
[
0.1,0.6) $ 之间,认为变量之间是弱相关的。
- 当 $ \rho $ 的绝对值在 $ [0,0.1) $ 之间,认为变量之间没有相关性。
皮尔逊相关系数适用于:
1. 两个变量之间是线性关系,都是连续数据。
2. 两个变量的总体是正态分布,或接近正态的单峰分布。
3. 两个变量的观测值是成对的,每对观测值之间相互独立。
`DataFrame`对象的`cov`方法和`corr`方法分别用于计算协方差和相关系数,`corr`方法的第一个参数`method`的默认值是`pearson`,表示计算皮尔逊相关系数;除此之外,还可以指定`kendall`或`spearman`来获得肯德尔系数或斯皮尔曼等级相关系数。
接下来,我们从名为`boston_house_price.csv`的文件中获取著名的[波士顿房价数据集
](
https://www.heywhale.com/mw/dataset/590bd595812ede32b73f55f2
)
来创建一个
`DataFrame`
,我们通过
`corr`
方法计算可能影响房价的
`13`
个因素中,哪些跟房价是正相关或负相关的,代码如下所示。
```
Python
boston_df = pd.read_csv('data/csv/boston_house_price.csv')
boston_df.corr()
```
> **说明**:如果需要上面例子中的 CSV 文件,可以通过下面的百度云盘地址进行获取,数据在《从零开始学数据分析》目录中。链接:<https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g>,提取码:e7b4。
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208213325.png"
>
斯皮尔曼相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。我们通过下面的方式来计算斯皮尔曼相关系数。
```
Python
boston_df.corr('spearman')
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208213518.png"
>
在 Notebook 或 JupyterLab 中,我们可以为
`PRICE`
列添加渐变色,用颜色直观的展示出跟房价负相关、正相关、不相关的列,
`DataFrame`
对象
`style`
属性的
`background_gradient`
方法可以完成这个操作,代码如下所示。
```
Python
boston_df.corr('spearman').style.background_gradient('RdYlBu', subset=['PRICE'])
```
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208215228.png"
>
上面代码中的
`RdYlBu`
代表的颜色如下所示,相关系数的数据值越接近
`1`
,颜色越接近红色;数据值越接近
`1`
,颜色越接近蓝色;数据值在
`0`
附件则是黄色。
```
Python
plt.get_cmap('RdYlBu')
```
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208215057.png"
>
### Index的应用
我们再来看看
`Index`
类型,它为
`Series`
和
`DataFrame`
对象提供了索引服务,常用的
`Index`
有以下几种,我们直接上代码。
1.
范围索引(
`RangeIndex`
)
代码:
```
Python
sales_data = np.random.randint(400, 1000, 12)
month_index = pd.RangeIndex(1, 13, name='月份')
ser = pd.Series(data=sales_data, index=month_index)
ser
```
输出:
```
月份
1 703
2 705
3 557
4 943
5 961
6 615
7 788
8 985
9 921
10 951
11 874
12 609
dtype: int64
```
2.
分类索引(
`CategoricalIndex`
)
代码:
```
Python
cate_index = pd.CategoricalIndex(
['苹果', '香蕉', '苹果', '苹果', '桃子', '香蕉'],
ordered=True,
categories=['苹果', '香蕉', '桃子']
)
ser = pd.Series(data=amount, index=cate_index)
ser
```
输出:
```
苹果 6
香蕉 6
苹果 7
苹果 6
桃子 8
香蕉 6
dtype: int64
```
基于索引分组数据,然后使用
`sum`
进行求和。
```
Python
ser.groupby(level=0).sum()
```
输出:
```
苹果 19
香蕉 12
桃子 8
dtype: int64
```
3.
多级索引(
`MultiIndex`
)
代码:
```
Python
ids = np.arange(1001, 1006)
sms = ['期中', '期末']
index = pd.MultiIndex.from_product((ids, sms), names=['学号', '学期'])
courses = ['语文', '数学', '英语']
scores = np.random.randint(60, 101, (10, 3))
df = pd.DataFrame(data=scores, columns=courses, index=index)
df
```
> **说明**:上面的代码使用了`MultiIndex`的类方法`from_product`,该方法通过`ids`和`sms`两组数据的笛卡尔积构造了多级索引。
输出:
```
语文 数学 英语
学号 学期
1001 期中 93 77 60
期末 93 98 84
1002 期中 64 78 71
期末 70 71 97
1003 期中 72 88 97
期末 99 100 63
1004 期中 80 71 61
期末 91 62 72
1005 期中 82 95 67
期末 84 78 86
```
根据第一级索引分组数据,按照期中成绩占
`25%`
,期末成绩占
`75%`
的方式计算每个学生每门课的成绩。
```
Python
# 计算每个学生的成绩,期中占25%,期末占75%
df.groupby(level=0).agg(lambda x: x.values[0] * 0.25 + x.values[1] * 0.75)
```
输出:
```
语文 数学 英语
学号
1001 93.00 92.75 78.00
1002 68.50 72.75 90.50
1003 92.25 97.00 71.50
1004 88.25 64.25 69.25
1005 83.50 82.25 81.25
```
4.
日期时间索引(
`DatetimeIndex`
)
通过
`date_range()`
函数,我们可以创建日期时间索引,代码如下所示。
代码:
```
Python
pd.date_range('2021-1-1', '2021-6-1', periods=10)
```
输出:
```
DatetimeIndex(['2021-01-01 00:00:00', '2021-01-17 18:40:00',
'2021-02-03 13:20:00', '2021-02-20 08:00:00',
'2021-03-09 02:40:00', '2021-03-25 21:20:00',
'2021-04-11 16:00:00', '2021-04-28 10:40:00',
'2021-05-15 05:20:00', '2021-06-01 00:00:00'],
dtype='datetime64[ns]', freq=None)
```
代码:
```
Python
pd.date_range('2021-1-1', '2021-6-1', freq='W')
```
输出:
```
DatetimeIndex(['2021-01-03', '2021-01-10', '2021-01-17', '2021-01-24',
'2021-01-31', '2021-02-07', '2021-02-14', '2021-02-21',
'2021-02-28', '2021-03-07', '2021-03-14', '2021-03-21',
'2021-03-28', '2021-04-04', '2021-04-11', '2021-04-18',
'2021-04-25', '2021-05-02', '2021-05-09', '2021-05-16',
'2021-05-23', '2021-05-30'],
dtype='datetime64[ns]', freq='W-SUN')
```
通过
`DateOffset`
类型,我们可以设置时间差并和
`DatetimeIndex`
进行运算,具体的操作如下所示。
代码:
```
Python
index = pd.date_range('2021-1-1', '2021-6-1', freq='W')
index - pd.DateOffset(days=2)
```
输出:
```
DatetimeIndex(['2021-01-01', '2021-01-08', '2021-01-15', '2021-01-22',
'2021-01-29', '2021-02-05', '2021-02-12', '2021-02-19',
'2021-02-26', '2021-03-05', '2021-03-12', '2021-03-19',
'2021-03-26', '2021-04-02', '2021-04-09', '2021-04-16',
'2021-04-23', '2021-04-30', '2021-05-07', '2021-05-14',
'2021-05-21', '2021-05-28'],
dtype='datetime64[ns]', freq=None)
```
代码:
```
Python
index + pd.DateOffset(days=2)
```
输出:
```
DatetimeIndex(['2021-01-05', '2021-01-12', '2021-01-19', '2021-01-26',
'2021-02-02', '2021-02-09', '2021-02-16', '2021-02-23',
'2021-03-02', '2021-03-09', '2021-03-16', '2021-03-23',
'2021-03-30', '2021-04-06', '2021-04-13', '2021-04-20',
'2021-04-27', '2021-05-04', '2021-05-11', '2021-05-18',
'2021-05-25', '2021-06-01'],
dtype='datetime64[ns]', freq=None)
```
可以使用
`DatatimeIndex`
类型的相关方法来处理数据,例如
`shift()`
方法可以通过时间前移或后移数据。我们仍然以上面百度股票数据为例,来演示
`shift()`
方法的使用,代码如下所示。
代码:
```
Python
baidu_df.shift(3, fill_value=0)
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208220551.png"
style=
"zoom:150%;"
>
代码:
```
Python
baidu_df.shift(-1, fill_value=0)
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208220713.png"
style=
"zoom:150%;"
>
通过
`asfreq()`
方法,我们可以指定一个时间频率抽取对应的数据,代码如下所示。
代码:
```
Python
baidu_df.asfreq('5D')
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208221202.png"
>
代码:
```
Python
baidu_df.asfreq('5D', method='ffill')
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208221249.png"
style=
"zoom:150%;"
>
通过
`resample()`
方法,我们可以基于时间对数据进行重采样,相当于根据时间周期对数据进行了分组操作,代码如下所示。
代码:
```
Python
baidu_df.resample('1M').mean()
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208221429.png"
>
> **说明**:上面的代码中,`W`表示一周,`5D`表示`5`天,`1M`表示`1`个月。
如果要实现日期时间的时区转换,我们首先用
`tz_localize()`
方法将日期时间本地化,代码如下所示。
代码:
```
Python
baidu_df = baidu_df.tz_localize('Asia/Chongqing')
baidu_df
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208221947.png"
>
在对时间本地化以后,我们使用
`tz_convert()`
方法就可以实现转换时区,代码如下所示。
代码:
```
Python
baidu_df.tz_convert('America/New_York')
```
输出:
<img
src=
"https://gitee.com/jackfrued/mypic/raw/master/20211208222404.png"
>
res/ABF827024EA535099DC0E6A66A336C51.png
0 → 100644
浏览文件 @
a259a6ab
1.5 MB
更新日志.md
浏览文件 @
a259a6ab
## 更新日志
### 2022年1月11日
1.
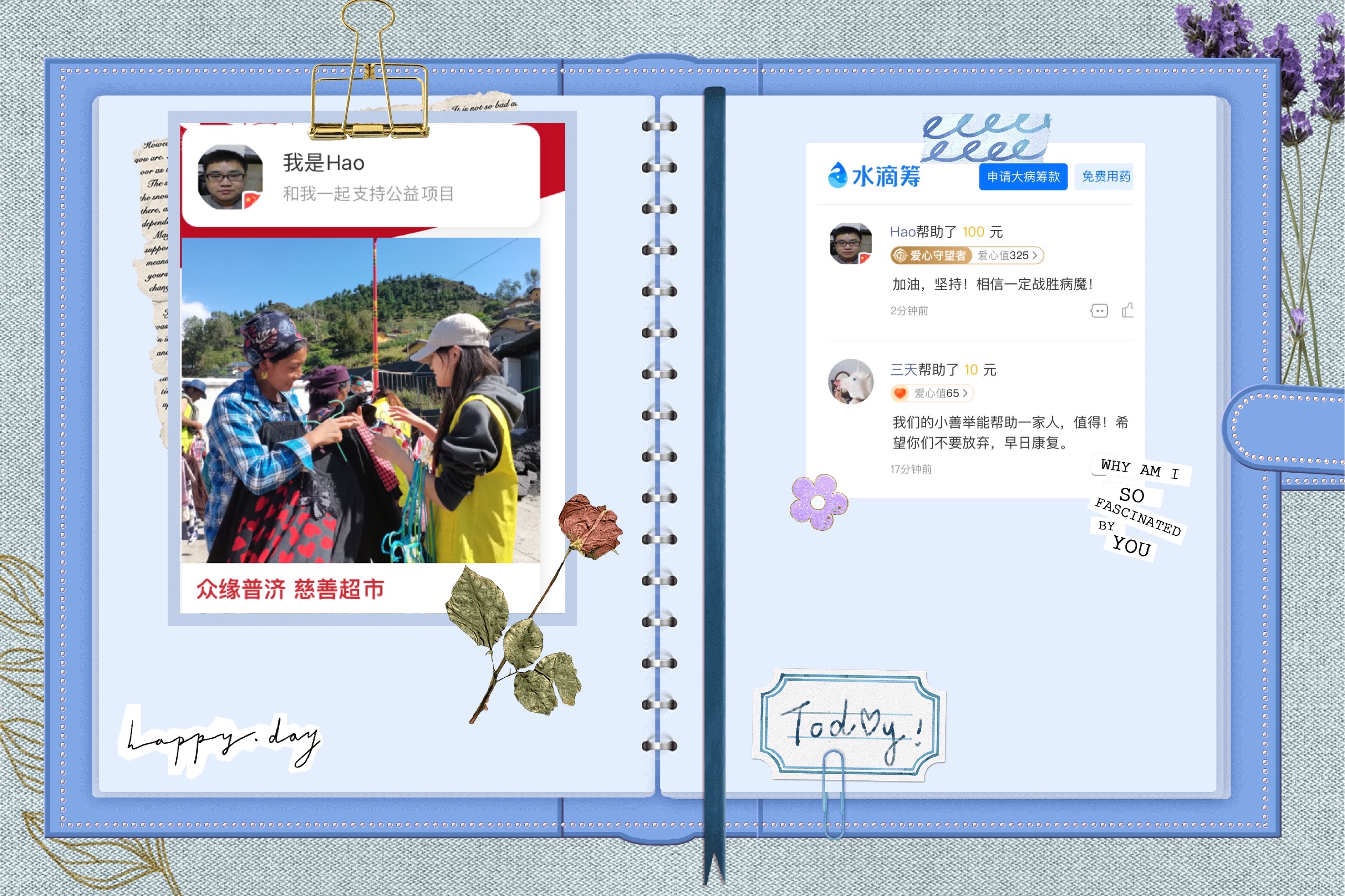
将近期收到的打赏通过水滴筹和众缘普济公益慈善促进会捐赠给有需要的人。

### 2021年11月22日
1.
更新了数据库部分的文档和代码。
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}