Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
qiwoaidiannao
Python专题
提交
5d204fc9
Python专题
项目概览
qiwoaidiannao
/
Python专题
与 Fork 源项目一致
Fork自
GitCode官方 / Python专题
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
Python专题
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
5d204fc9
编写于
7月 21, 2021
作者:
M
MaoXianxin
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
basic regression fuel efficiency
上级
a01373b0
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
108 addition
and
0 deletion
+108
-0
汽车燃料效率预测.md
汽车燃料效率预测.md
+108
-0
未找到文件。
汽车燃料效率预测.md
0 → 100644
浏览文件 @
5d204fc9
本教程的目的是要预测汽车的燃料效率,相比于之前的分类,这是一个回归问题,回归是针对连续变量的,分类是针对离散变量的
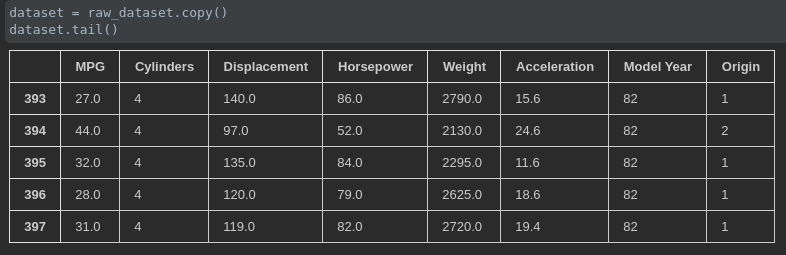
用的数据集是 Auto MPG ,包含有 MPG、Cylinders、Displacement、Horsepower、Weight、Acceleration、Model Year、Origin 这么 8 个特征,我们的目的是根据其它 7 个特征去预测 MPG ,数据如下图所示
由于本教程篇幅过长,我们这里就不粘贴过多代码了,如果需要查看代码,文末有提供链接地址
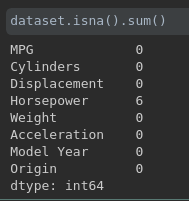
第一步我们需要加载数据,然后对数据进行清理,把一些 unknown values 去除,如下图所示,我们可以发现 Horsepower 这一列有 6 个需要清除的值
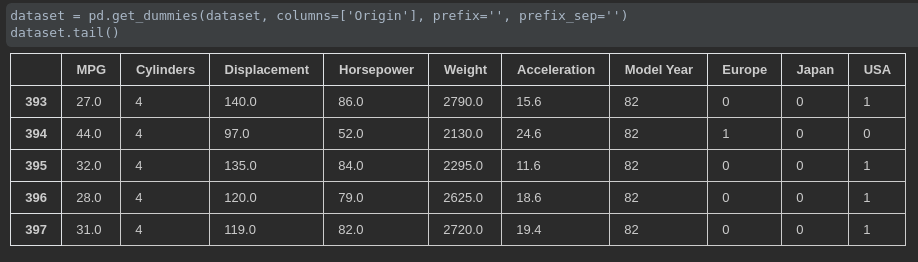
我们仔细观察下数据可以发现,Origin 这一列的值,其实是类别,不是数值,所以需要转化成 one-hot ,处理结果如下图所示
接下来我们需要进行数据集的划分,执行如下代码
```
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
```
我们再来查看下各个特征的一些统计结果
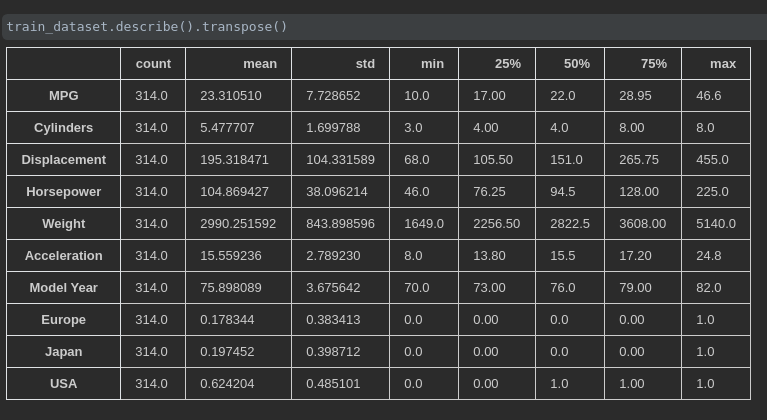
我们可以发现一些特征的数值特别大,比如 Weight ,一些特征的数值特别小,比如 Cylinders ,所以我们需要对数据进行标准化
## Linear Regression
### 用一个变量预测 MPG
```
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = preprocessing.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
```
上面是核心代码,其中输入的一个变量指 Horsepower ,预测的目标是 MPG
### 用多个变量预测 MPG
```
normalizer = preprocessing.Normalization(axis=-1)
normalizer.adapt(np.array(train_features))
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
```
上面是核心代码,其中输入的多个变量指 Cylinders、Displacement、Horsepower、Weight、Acceleration、Model Year、Origin 这么 7 个特征,预测的目标是MPG
## DNN regression
```
def
build_and_compile_model
(
norm
):
model
=
keras
.
Sequential
([
norm
,
layers
.
Dense
(
64
,
activation
=
'relu'
),
layers
.
Dense
(
64
,
activation
=
'relu'
),
layers
.
Dense
(
1
)
])
model
.
compile
(
loss
=
'mean_absolute_error'
,
optimizer
=
tf
.
keras
.
optimizers
.
Adam
(
0.001
))
return
model
```
上面是 DNN 的模型搭建代码
```
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
```
上面是用一个变量去预测 MPG

上图是 dnn_horsepower_model.summary() 的结果
```
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
```
上面是用所有特征去预测 MPG
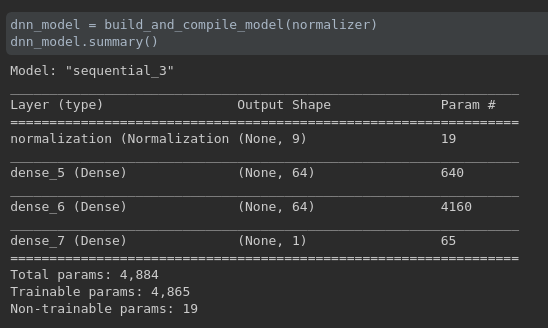
上图是 dnn_model.summary() 的结果

针对 4 个方案,我们可以进行对比,如上图所示,我们发现 dnn_model 的 MAE 最低,也就是该模型效果最好
代码地址: https://codechina.csdn.net/csdn_codechina/enterprise_technology/-/blob/master/basic_regression_fuel_efficiency.ipynb
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录