Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
沉默王二
Jmx Java
提交
ee3f988d
J
Jmx Java
项目概览
沉默王二
/
Jmx Java
大约 1 年 前同步成功
通知
160
Star
18
Fork
2
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
Jmx Java
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
ee3f988d
编写于
8月 16, 2023
作者:
沉默王二
💬
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
ConcurrentHashMap
上级
1098f88c
变更
3
展开全部
隐藏空白更改
内联
并排
Showing
3 changed file
with
234 addition
and
280 deletion
+234
-280
README.md
README.md
+1
-1
docs/thread/ConcurrentHashMap.md
docs/thread/ConcurrentHashMap.md
+232
-187
docs/thread/map.md
docs/thread/map.md
+1
-92
未找到文件。
README.md
浏览文件 @
ee3f988d
...
...
@@ -262,7 +262,7 @@
-
[
协作类Condition
](
docs/thread/condition.md
)
-
[
线程阻塞唤醒类LockSupport
](
docs/thread/LockSupport.md
)
-
[
Java的并发容器
](
docs/thread/map.md
)
-
[
吊打Java并发面试官之
ConcurrentHashMap
](
docs/thread/ConcurrentHashMap.md
)
-
[
ConcurrentHashMap
](
docs/thread/ConcurrentHashMap.md
)
-
[
吊打Java并发面试官之ConcurrentLinkedQueue
](
docs/thread/ConcurrentLinkedQueue.md
)
-
[
吊打Java并发面试官之CopyOnWriteArrayList
](
docs/thread/CopyOnWriteArrayList.md
)
-
[
吊打Java并发面试官之ThreadLocal
](
docs/thread/ThreadLocal.md
)
...
...
docs/thread/ConcurrentHashMap.md
浏览文件 @
ee3f988d
此差异已折叠。
点击以展开。
docs/thread/map.md
浏览文件 @
ee3f988d
...
...
@@ -101,97 +101,6 @@ public interface ConcurrentMap<K, V> extends Map<K, V> {
ConcurrentHashMap 同
[
HashMap
](
https://javabetter.cn/collection/hashmap.html
)
一样,也是基于散列表的 map,但是它提供了一种与 Hashtable 完全不同的加锁策略,提供了更高效的并发性和伸缩性。
ConcurrentHashMap 在 JDK 1.7 和 JDK 1.8 中有一些区别。这里我们分开介绍一下。
**JDK 1.7**
ConcurrentHashMap 在 JDK 1.7 中,提供了一种粒度更细的加锁机制,这种机制叫分段锁「Lock Striping」。整个哈希表被分为多个段,每个段都独立锁定。读取操作不需要锁,写入操作仅锁定相关的段。这减小了锁冲突的几率,从而提高了并发性能。
这种机制的优点:在并发环境下将实现更高的吞吐量,而在单线程环境下只损失非常小的性能。
可以这样理解分段锁,就是
**将数据分段,对每一段数据分配一把锁**
。当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
有些方法需要跨段,比如
`size()`
、
`isEmpty()`
、
`containsValue()`
,它们可能需要锁定整个表而不仅仅是某个段,这需要按顺序锁定所有段,操作完后,再按顺序释放所有段的锁。如下图:
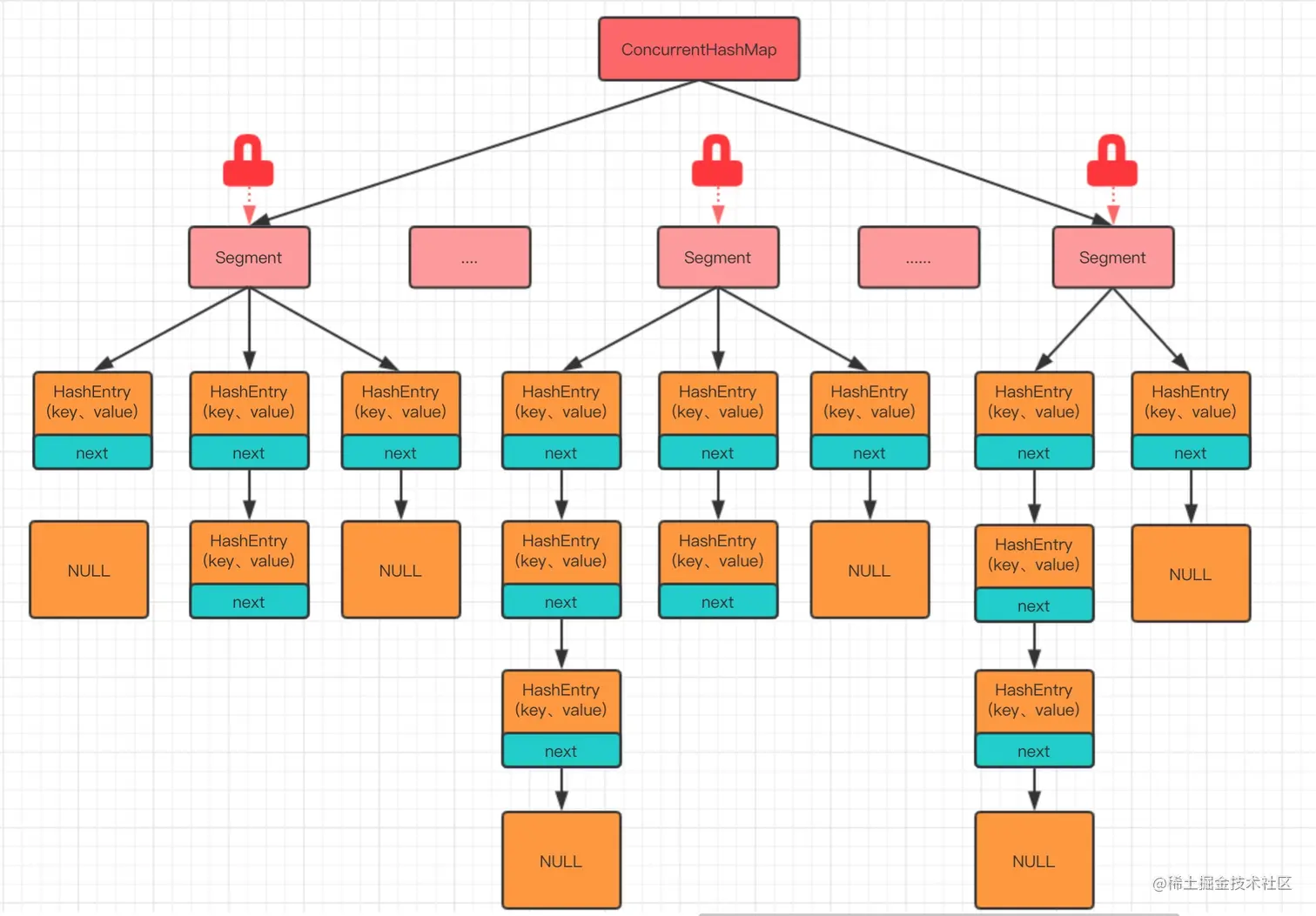
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组构成的。Segment 是一种可重入的锁
[
ReentrantLock
](
https://javabetter.cn/thread/reentrantLock.html
)
,HashEntry 则用于存储键值对数据。
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的结构和 HashMap 类似,是一种数组和链表结构, 一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素, 每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。
单一的 Segment 结构如下:
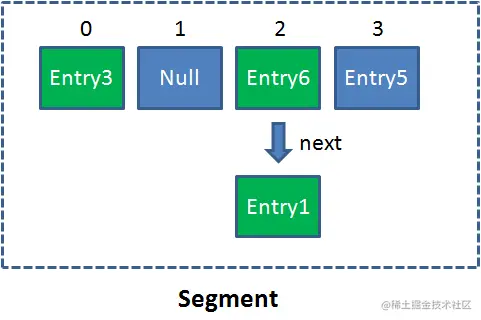
像这样的 Segment 对象,在 ConcurrentHashMap 集合中有多少个呢?有 2 的 N 次方个,共同保存在一个名为 segments 的数组当中。 因此整个 ConcurrentHashMap 的结构如下:
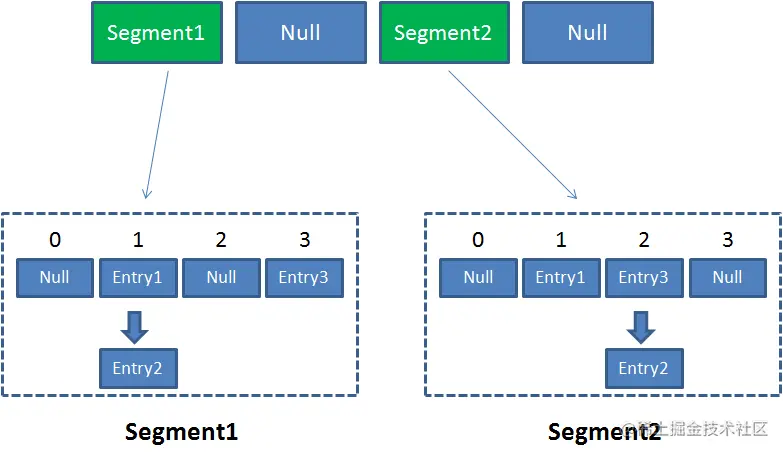
可以说,ConcurrentHashMap 是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
Case1:不同 Segment 的并发写入(可以并发执行)
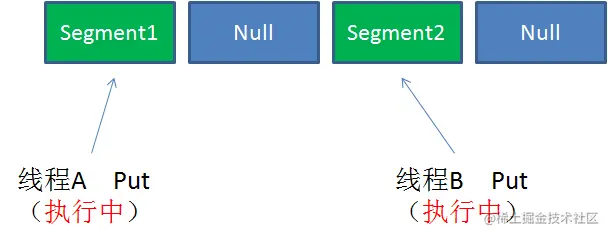
Case2:同一 Segment 的一写一读(可以并发执行)
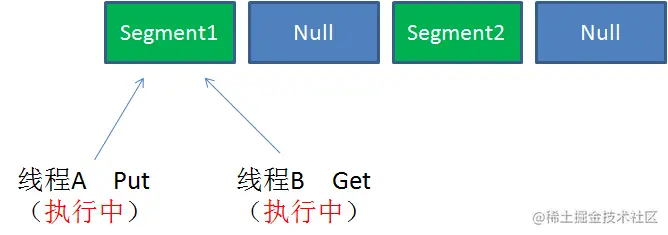
Case3:同一 Segment 的并发写入

Segment 的写入是需要上锁的,因此对同一 Segment 的并发写入会被阻塞。
由此可见,ConcurrentHashMap 中每个 Segment 各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
ConcurrentHashMap 读写过程如下:
get 方法
-
为输入的 Key 做 Hash 运算,得到 hash 值。
-
通过 hash 值,定位到对应的 Segment 对象
-
再次通过 hash 值,定位到 Segment 当中数组的具体位置。
put 方法
-
为输入的 Key 做 Hash 运算,得到 hash 值。
-
通过 hash 值,定位到对应的 Segment 对象
-
获取可重入锁
-
再次通过 hash 值,定位到 Segment 当中数组的具体位置。
-
插入或覆盖 HashEntry 对象。
-
释放锁。
**JDK 1.8**
而在 JDK 1.8 中,ConcurrentHashMap 主要做了两个优化:
-
同
[
HashMap
](
https://javabetter.cn/collection/hashmap.html
)
一样,链表也会在长度达到 8 的时候转化为红黑树,这样可以提升大量冲突时候的查询效率;
-
以某个位置的头结点(链表的头结点或红黑树的 root 结点)为锁,配合自旋+
[
CAS
](
https://javabetter.cn/thread/cas.html
)
避免不必要的锁开销,进一步提升并发性能。
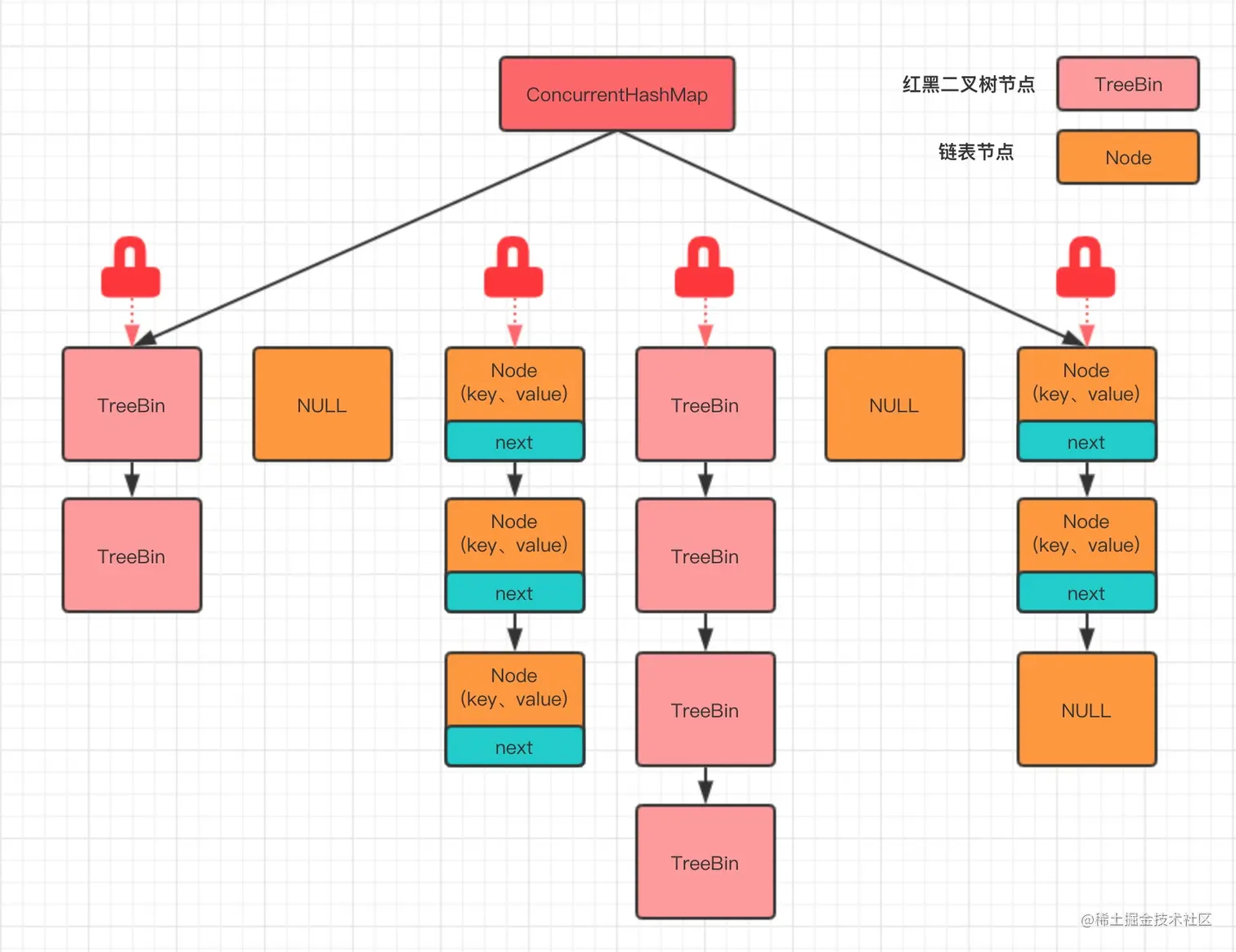
相比 JDK1.7 中的 ConcurrentHashMap,JDK1.8 中的 ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS + synchronized 来保证并发安全性,整个容器只分为一个 Segment,即 table 数组。
JDK1.8 中的 ConcurrentHashMap 对节点 Node 类中的共享变量,和 JDK1.7 一样,使用 volatile 关键字,保证多线程操作时,变量的可见性!
```
java
static
class
Node
<
K
,
V
>
implements
Map
.
Entry
<
K
,
V
>
{
final
int
hash
;
final
K
key
;
volatile
V
val
;
volatile
Node
<
K
,
V
>
next
;
Node
(
int
hash
,
K
key
,
V
val
,
Node
<
K
,
V
>
next
)
{
this
.
hash
=
hash
;
this
.
key
=
key
;
this
.
val
=
val
;
this
.
next
=
next
;
}
......
}
```
简单分析一下 JDK1.8 中的 ConcurrentHashMap 的 put 方法:
```
java
...
...
@@ -1109,7 +1018,7 @@ public class BlackListServiceImpl {
本文主要介绍了并发包中的三个重要的容器类,Map、阻塞队列和 CopyOnWrite 容器,Map 用于存储键值对,阻塞队列用于生产者-消费者模型,而 CopyOnWrite 容器用于“读多写少”的并发场景。
> 编辑:沉默王二,部分内容来源于朋友小七萤火虫开源的这个仓库:[深入浅出 Java 多线程](http://concurrent.redspider.group/),部分内容来自于这篇[初念初恋-ConcurrentHashMap](https://juejin.cn/post/7064061605185028110)
,图片画的特别漂亮
。
> 编辑:沉默王二,部分内容来源于朋友小七萤火虫开源的这个仓库:[深入浅出 Java 多线程](http://concurrent.redspider.group/),部分内容来自于这篇[初念初恋-ConcurrentHashMap](https://juejin.cn/post/7064061605185028110)。
---
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录