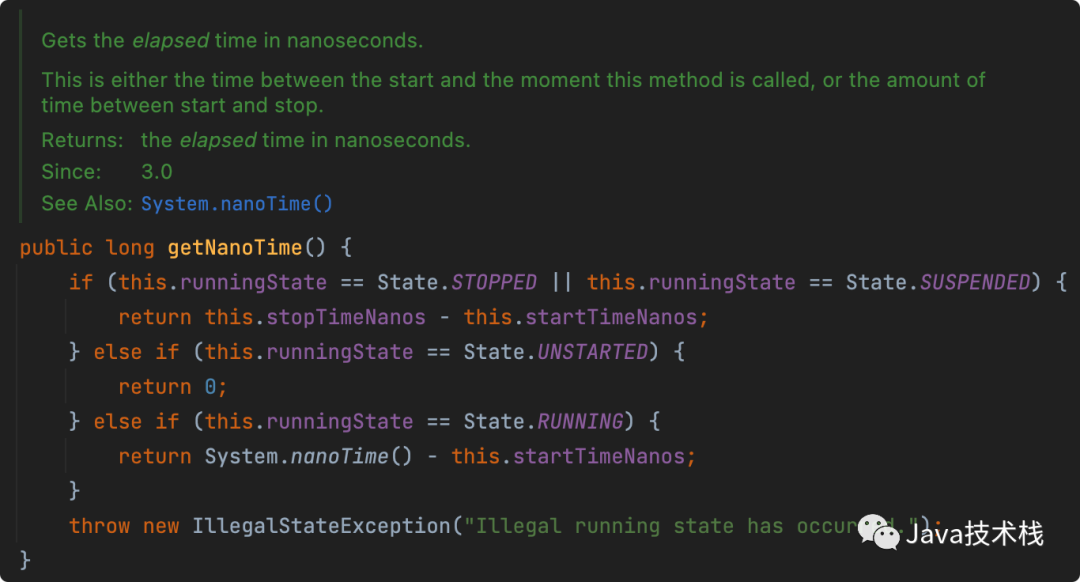
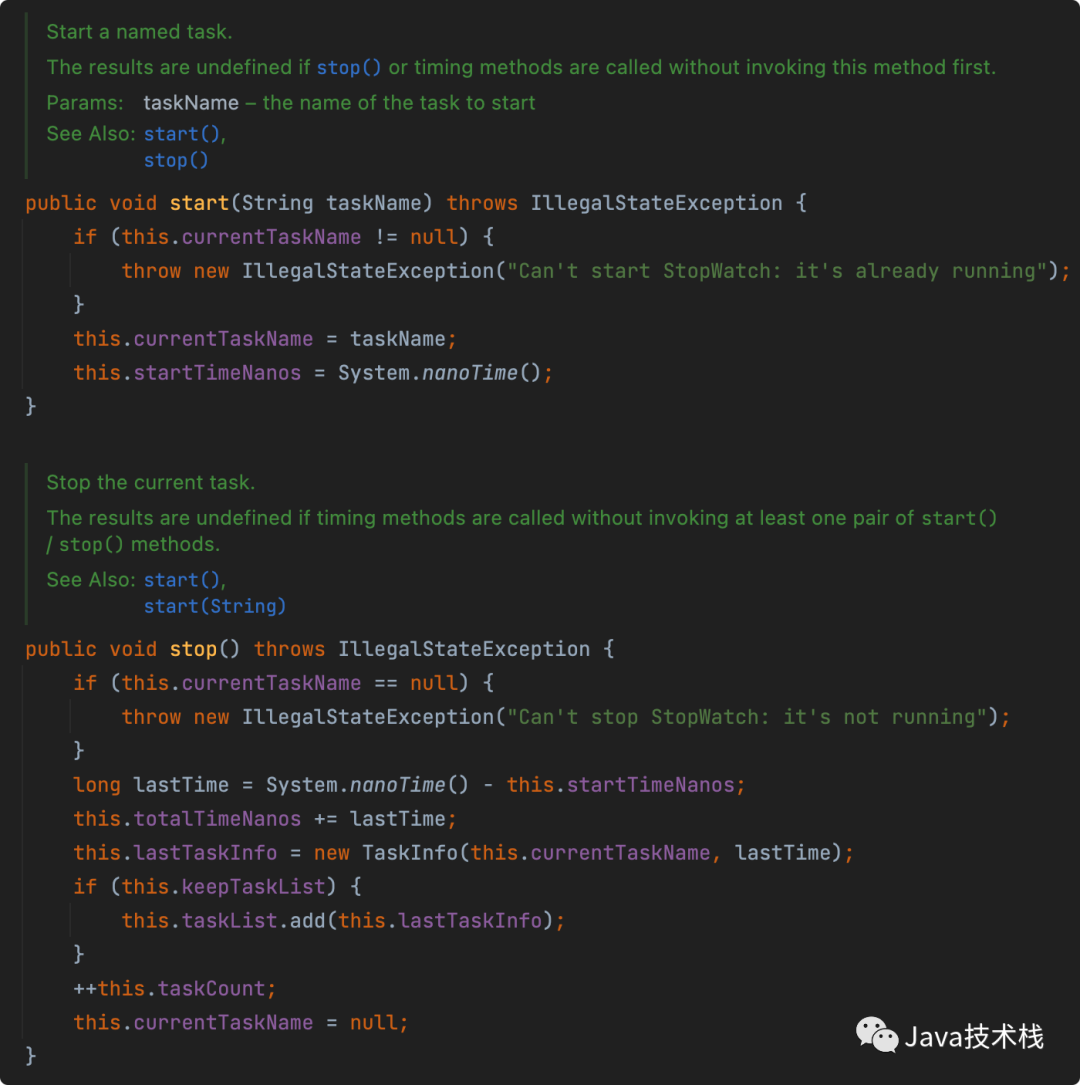
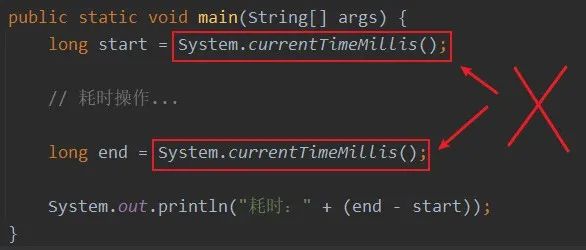
别再用 System.currentTimeMillis() 统计耗时了,太 Low,StopWatch 好用到爆!
Showing
{kind=link}
163.9 KB
{kind=link}
262.6 KB
{kind=link}

19.8 KB
{kind=link}
43.8 KB
{kind=link}
36.5 KB
{kind=link}

67.0 KB
{kind=link}
18.4 KB
{kind=link}
1.7 KB
{kind=link}
140.5 KB
{kind=link}
117.4 KB
{kind=link}
116.7 KB
{kind=link}

60.2 KB
{kind=link}

19.8 KB
{kind=link}
166.3 KB
{kind=link}
101.9 KB
{kind=link}

67.0 KB
{kind=link}
107.8 KB
{kind=link}
88.4 KB
{kind=link}
59.2 KB
{kind=link}

19.8 KB
{kind=link}

67.0 KB
{kind=link}
49.7 KB