2021年06月05日更新
Showing
docs/array/arrays.md
0 → 100644
docs/array/gailan.md
0 → 100644
docs/array/print.md
0 → 100644
docs/object-class/box.md
0 → 100644
docs/object-class/deep-copy.md
0 → 100644
docs/string/constant-pool.md
0 → 100644
docs/string/intern.md
0 → 100644
docs/string/source.md
0 → 100644
images/array/print-01.png
0 → 100644
{kind=link}

5.7 KB
images/array/print-02.png
0 → 100644
{kind=link}

31.7 KB
images/array/print-03.png
0 → 100644
{kind=link}

104.2 KB
{kind=link}
8.6 KB
{kind=link}
9.6 KB
{kind=link}
9.0 KB
{kind=link}
14.6 KB
{kind=link}
988 字节
images/object-class/box-01.png
0 → 100644
{kind=link}
34.9 KB
{kind=link}
122.9 KB
{kind=link}
250.9 KB
{kind=link}
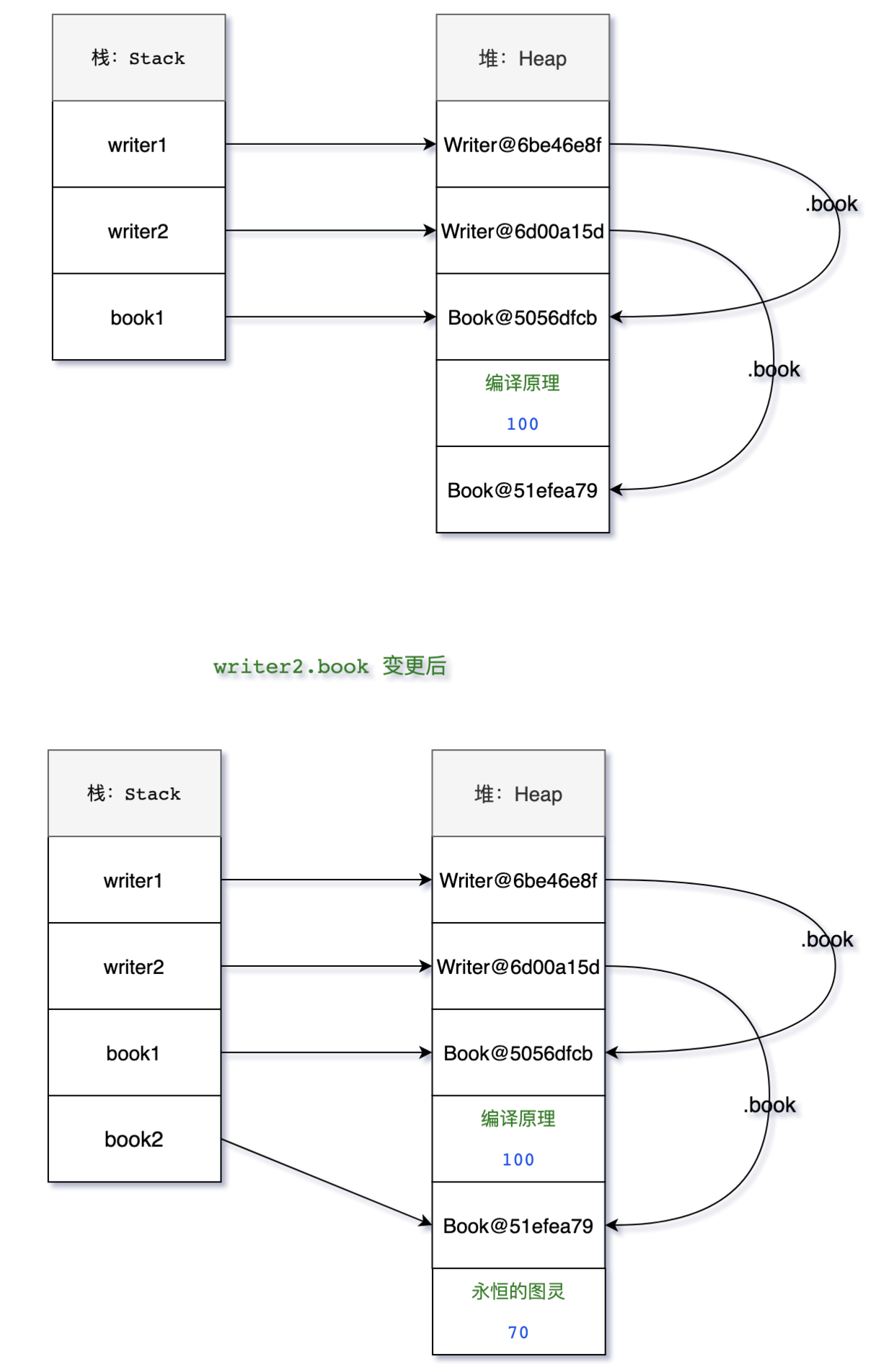
300.3 KB
{kind=link}

77.9 KB
{kind=link}

54.4 KB
{kind=link}
9.9 KB
{kind=link}
7.1 KB
{kind=link}

6.6 KB
{kind=link}
39.3 KB
{kind=link}
38.6 KB
{kind=link}
19.0 KB
{kind=link}
28.8 KB
{kind=link}
68.5 KB
{kind=link}
73.7 KB
{kind=link}
38.1 KB
{kind=link}
34.4 KB
images/string/intern-01.png
0 → 100644
{kind=link}
22.6 KB
images/string/intern-02.png
0 → 100644
{kind=link}
16.0 KB