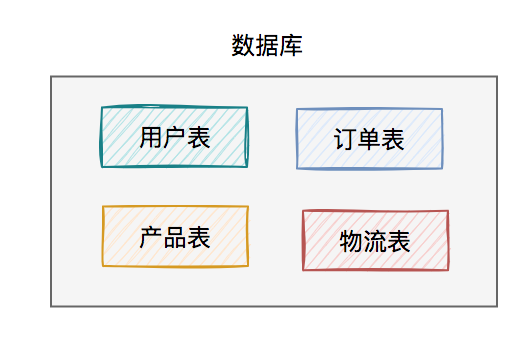
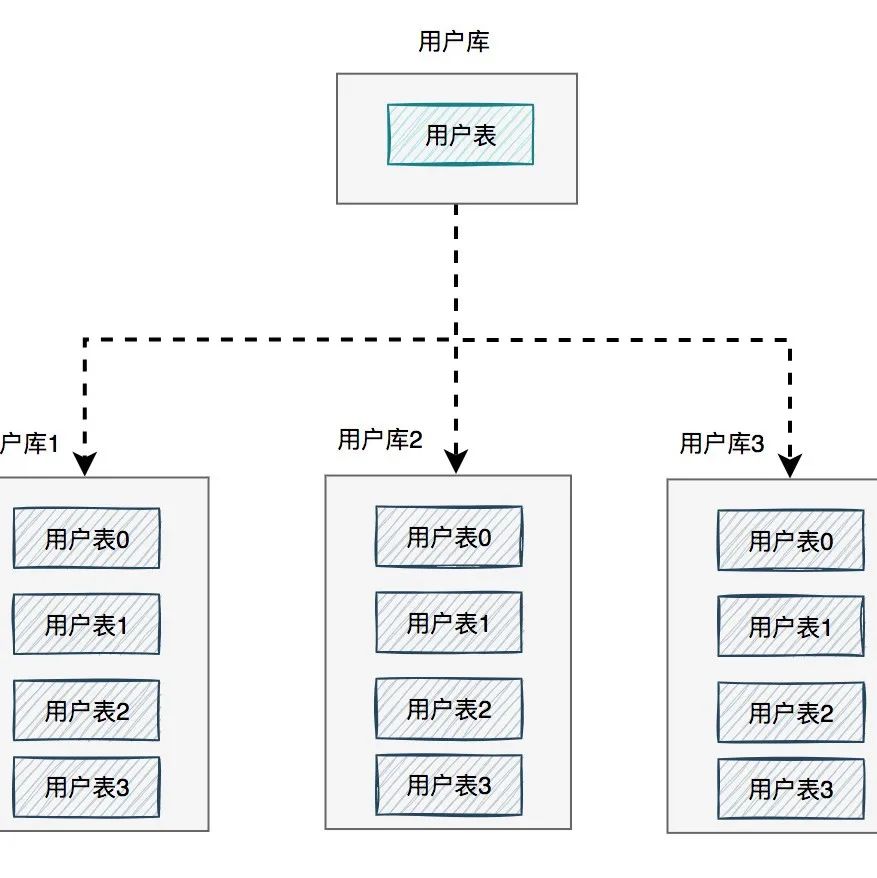
分库分表
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
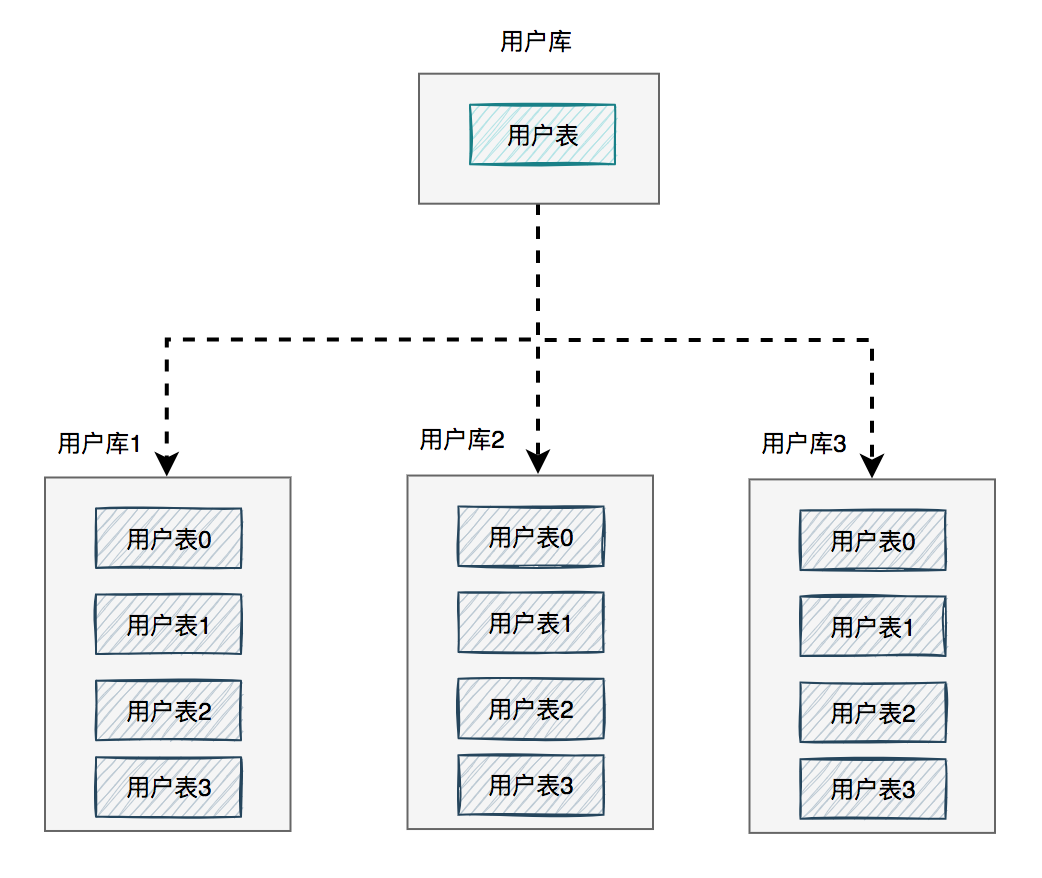
171.6 KB
{kind=link}
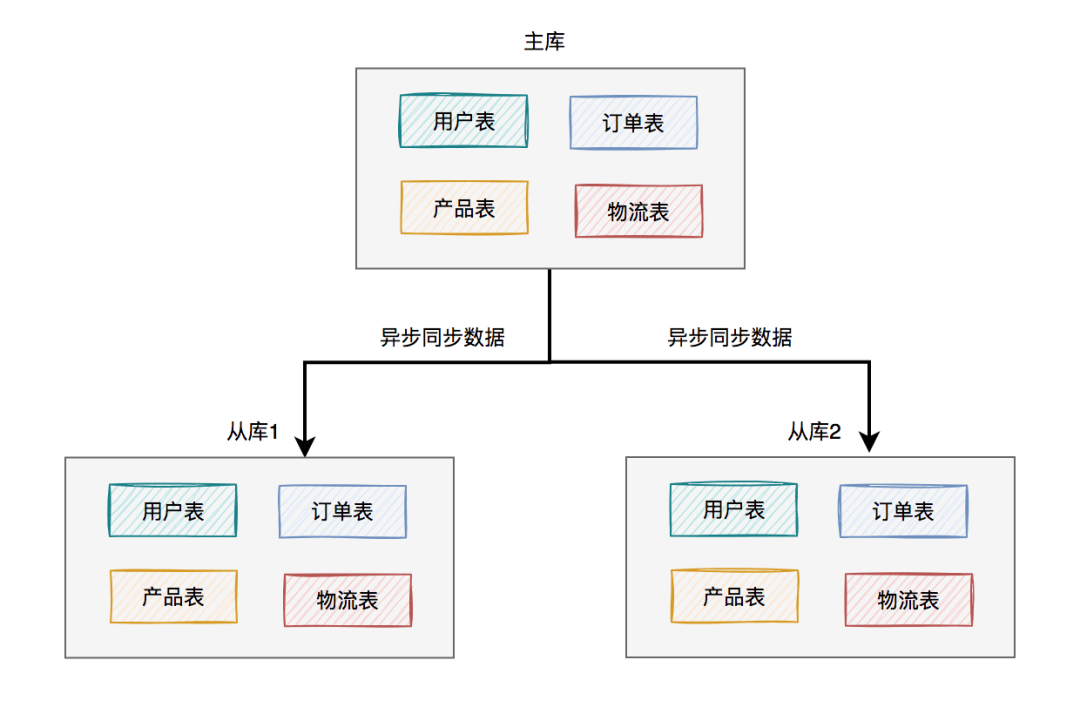
161.3 KB
{kind=link}
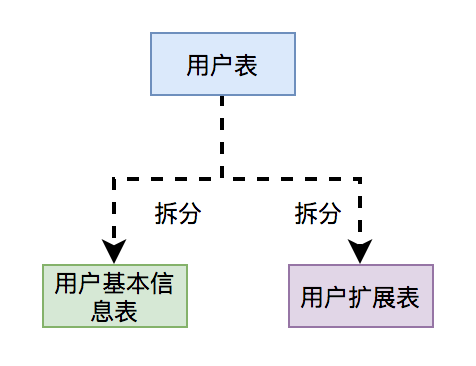
14.0 KB
{kind=link}
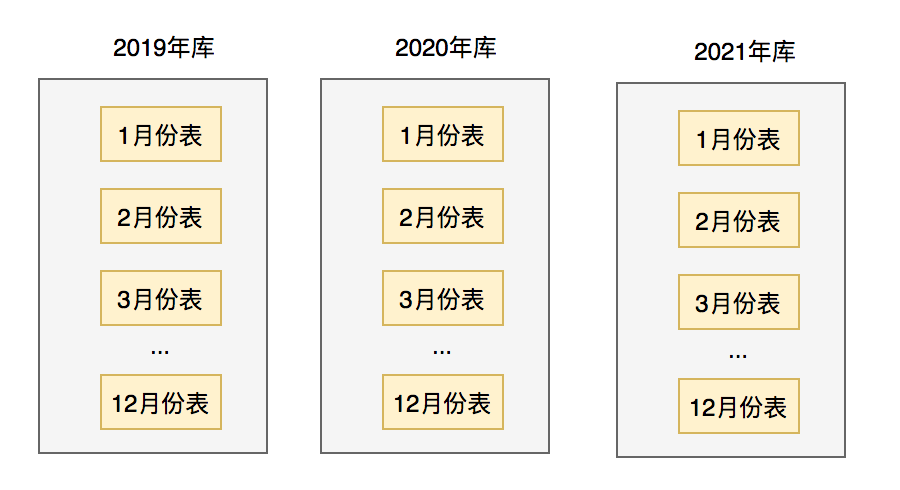
20.9 KB
{kind=link}
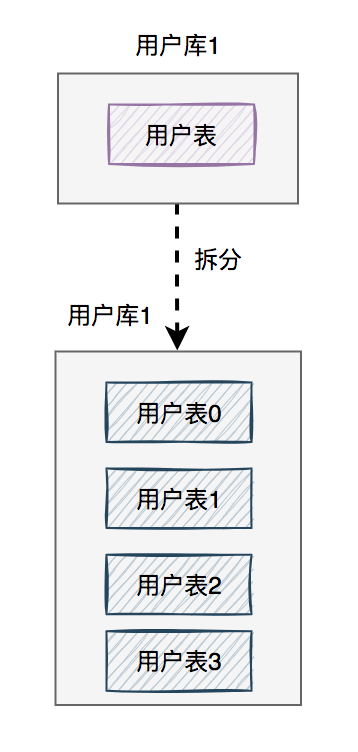
70.2 KB
{kind=link}
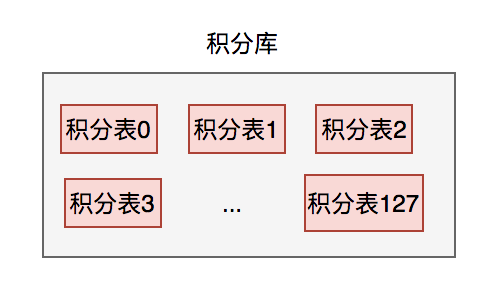
14.0 KB
{kind=link}
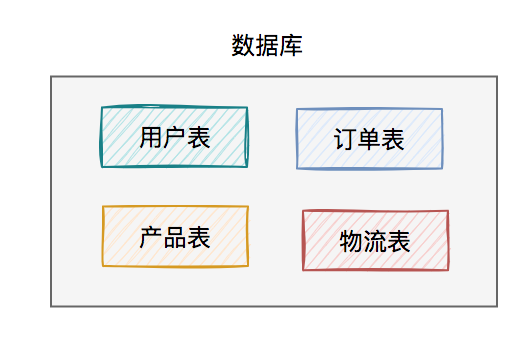
49.2 KB
{kind=link}
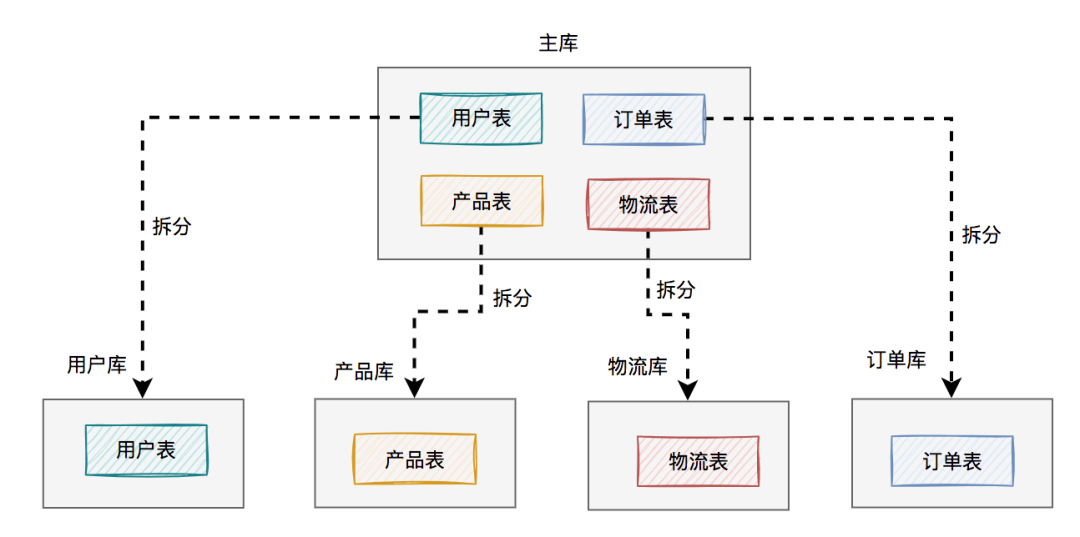
122.0 KB
{kind=link}

104.8 KB
{kind=link}
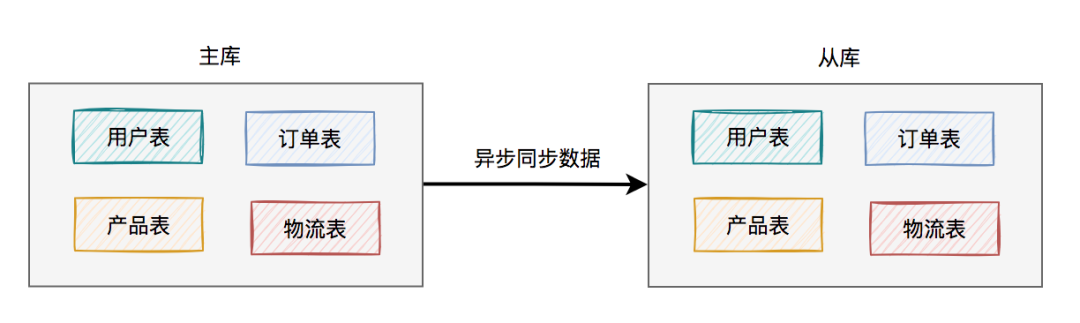
103.1 KB
{kind=link}
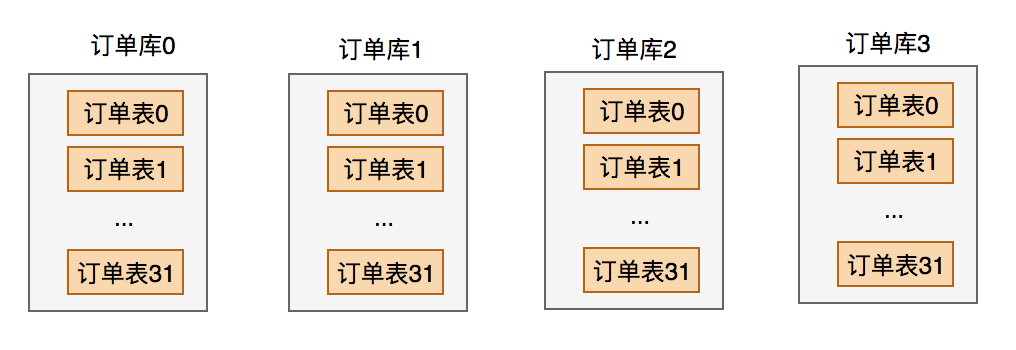
16.1 KB
{kind=link}
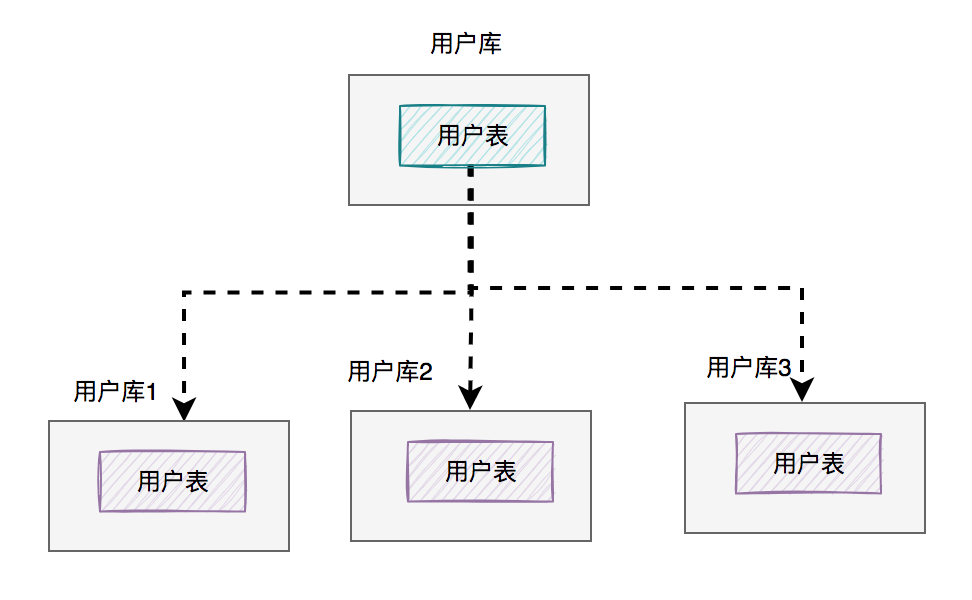
58.5 KB
{kind=link}
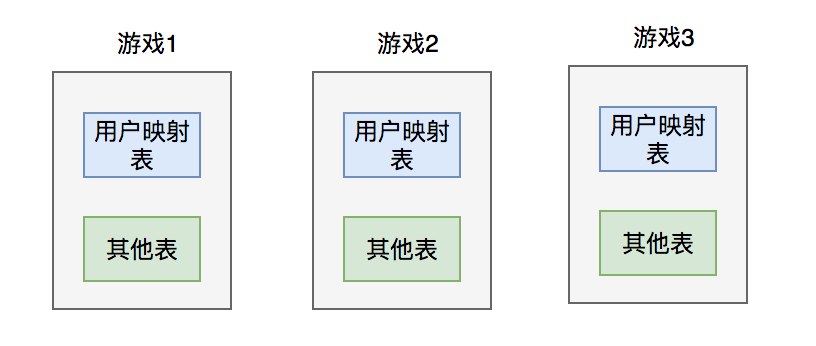
13.7 KB
{kind=link}
49.2 KB
{kind=link}
70.1 KB
171.6 KB
161.3 KB
14.0 KB
20.9 KB
70.2 KB
14.0 KB
49.2 KB
122.0 KB
104.8 KB
103.1 KB
16.1 KB
58.5 KB
13.7 KB
49.2 KB
70.1 KB