微信公众号文章摘录
Showing
此差异已折叠。
此差异已折叠。
{kind=link}
216.9 KB
{kind=link}
34.2 KB
{kind=link}
79.5 KB
{kind=link}
216.9 KB
{kind=link}

17.6 KB
{kind=link}
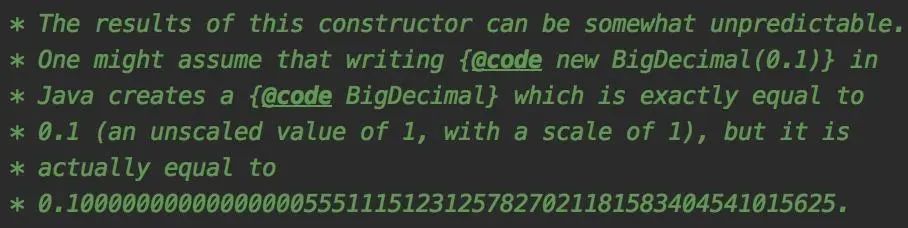
32.7 KB
{kind=link}

21.9 KB
{kind=link}
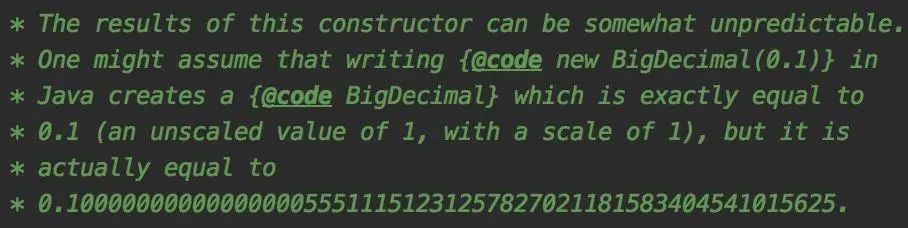
32.7 KB
{kind=link}
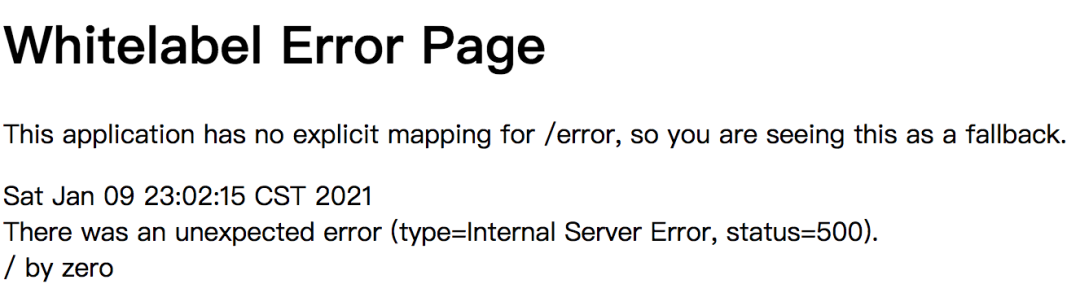
88.6 KB
{kind=link}

67.0 KB
{kind=link}
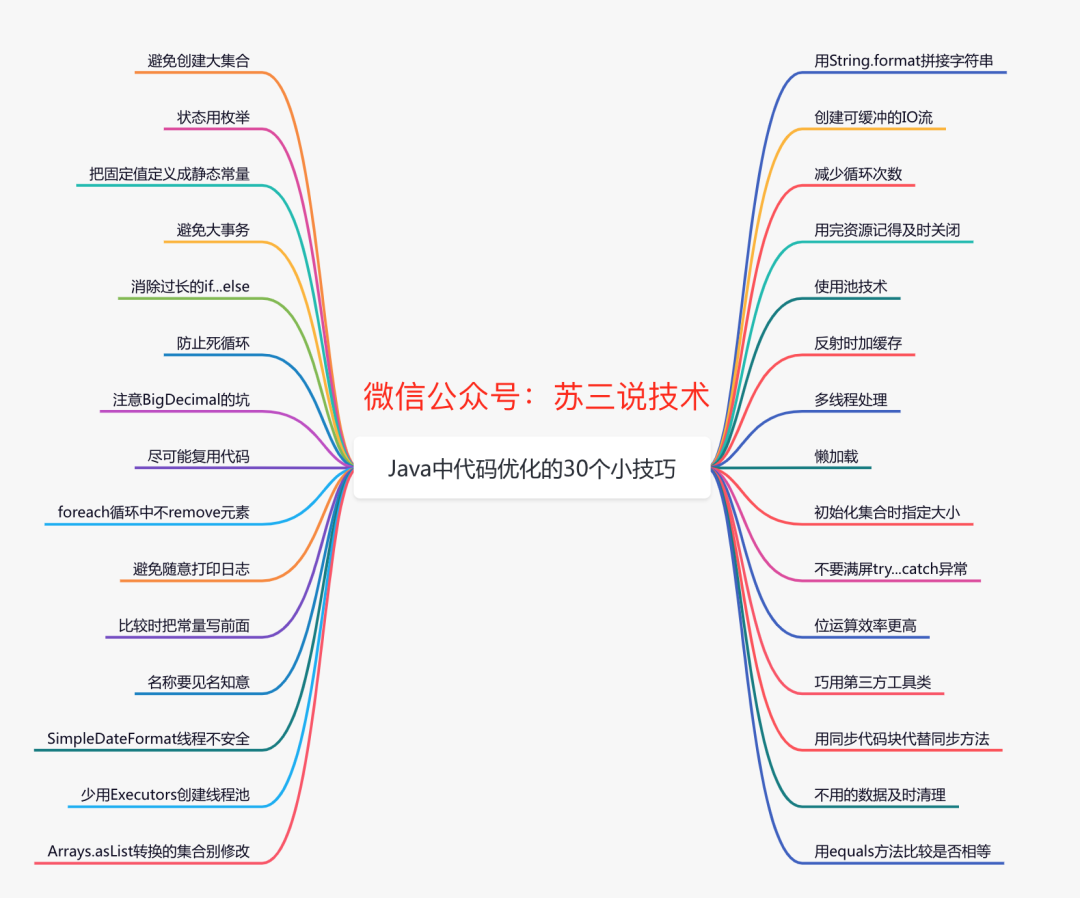
253.2 KB
{kind=link}
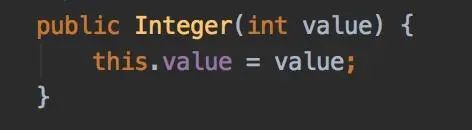
6.2 KB
{kind=link}
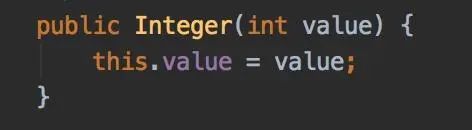
6.2 KB
{kind=link}

67.0 KB
{kind=link}
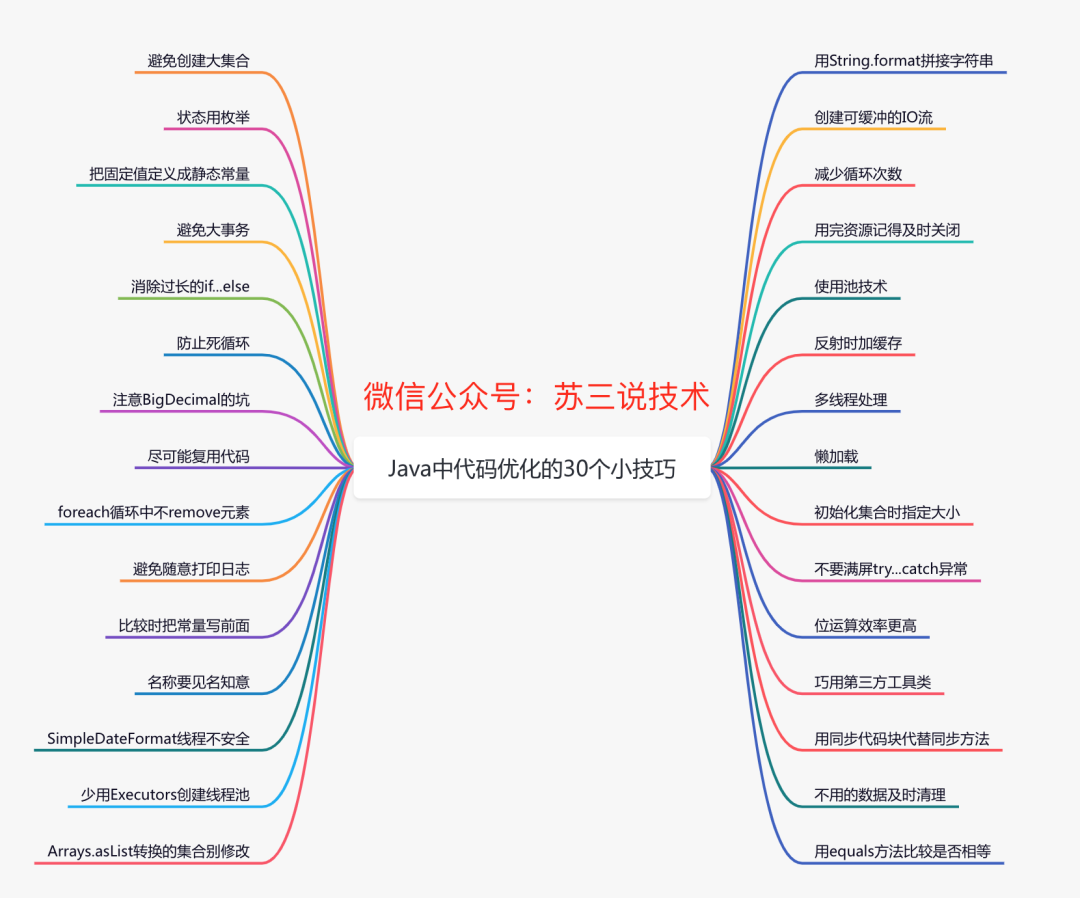
253.2 KB
{kind=link}

21.9 KB
{kind=link}
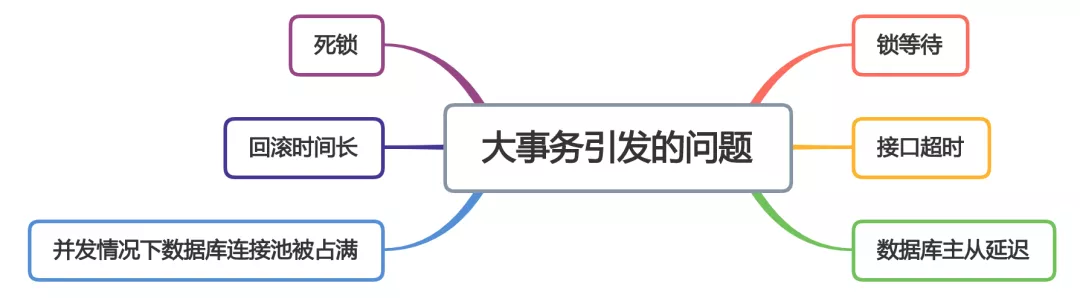
102.0 KB
{kind=link}

29.9 KB
{kind=link}
88.6 KB
{kind=link}
19.7 KB
{kind=link}
102.0 KB
{kind=link}
19.7 KB
{kind=link}
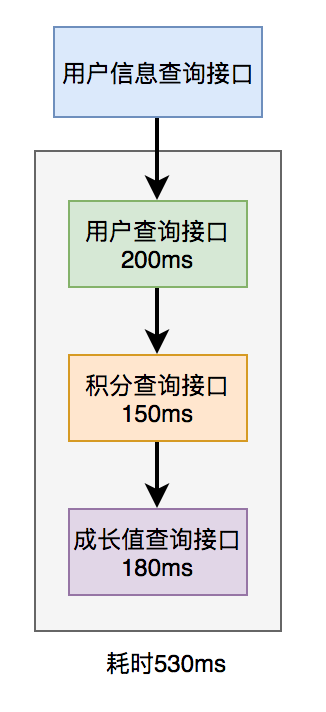
29.9 KB
{kind=link}
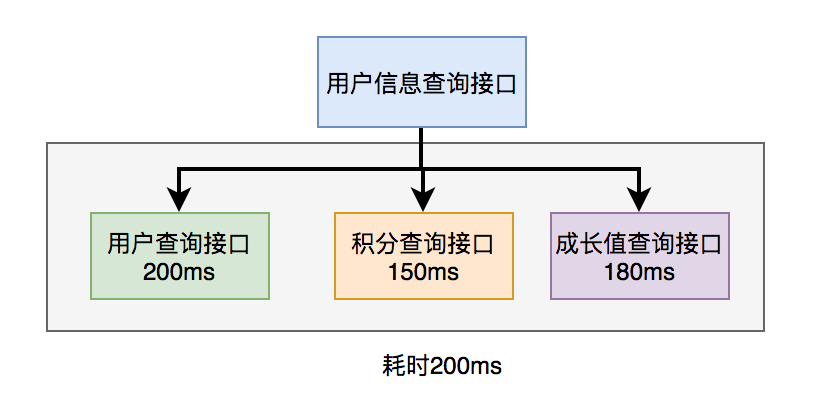
29.9 KB
{kind=link}
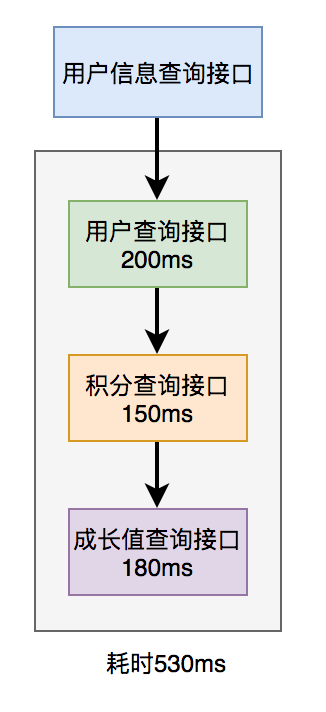
29.9 KB
{kind=link}
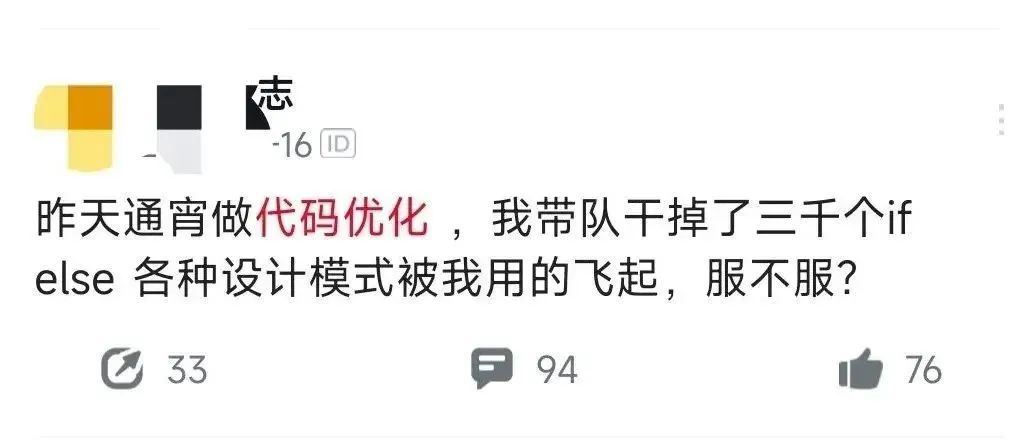
35.5 KB
{kind=link}
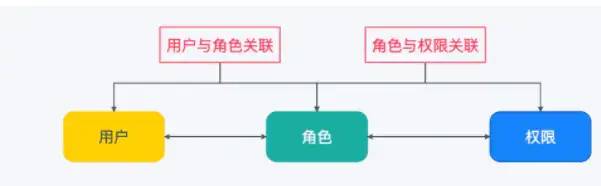
7.3 KB
{kind=link}

67.0 KB
{kind=link}

19.8 KB
{kind=link}
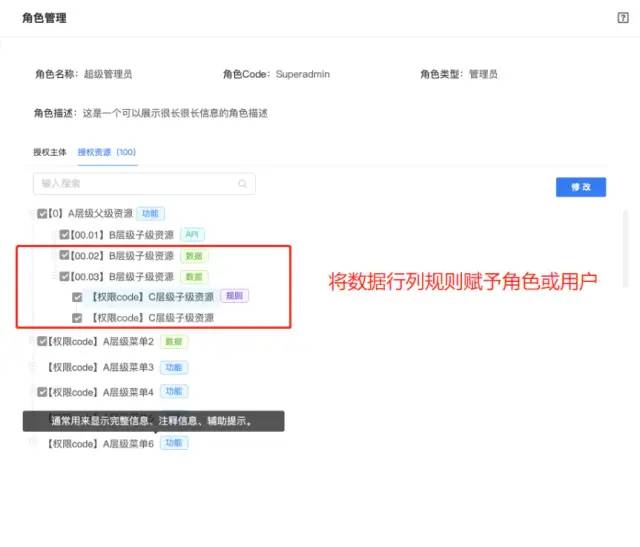
20.6 KB
{kind=link}
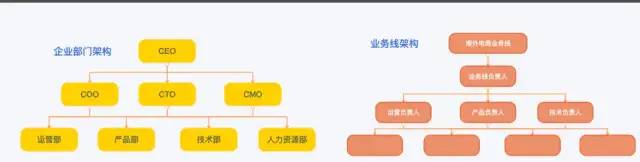
9.6 KB
{kind=link}
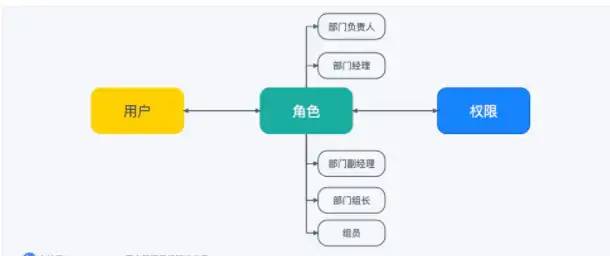
7.6 KB
{kind=link}
6.5 KB
{kind=link}
14.3 KB
{kind=link}
14.0 KB
{kind=link}
17.2 KB
{kind=link}
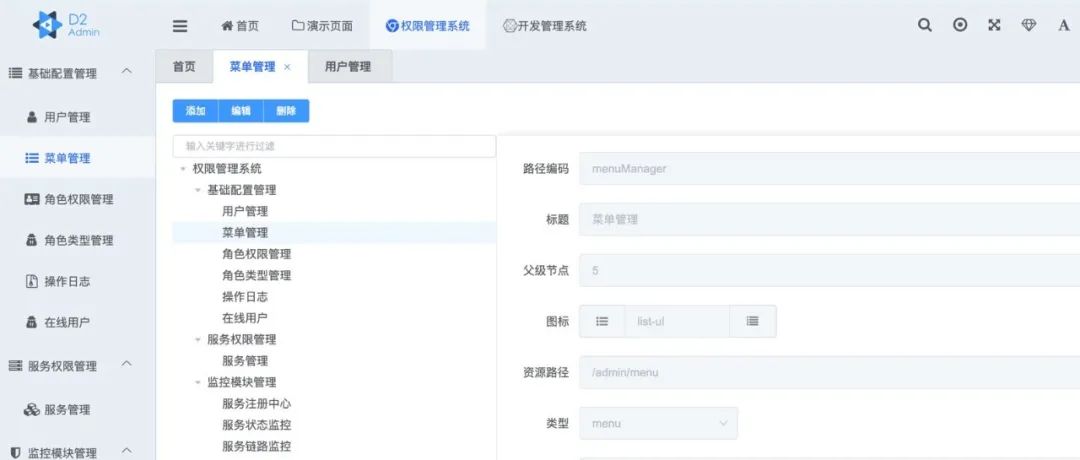
32.2 KB
{kind=link}
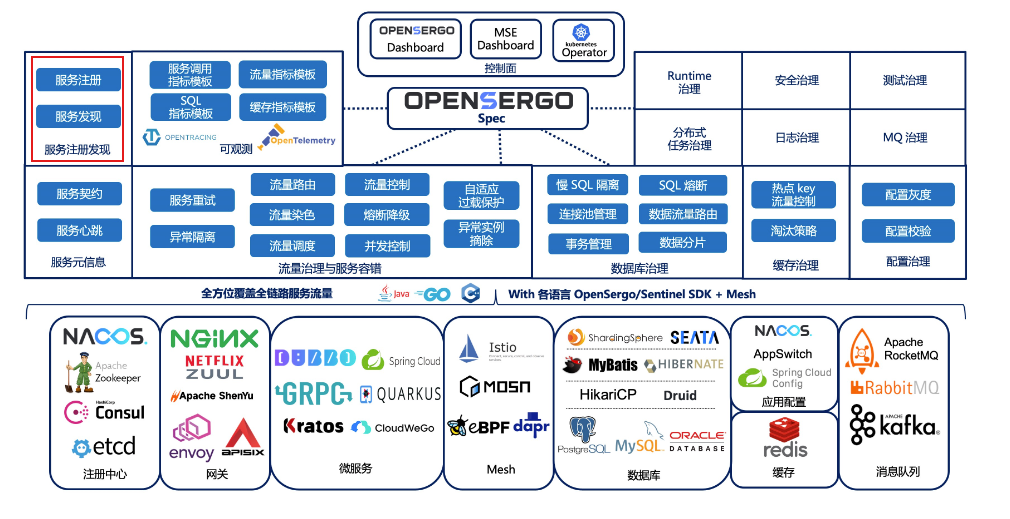
322.8 KB
{kind=link}
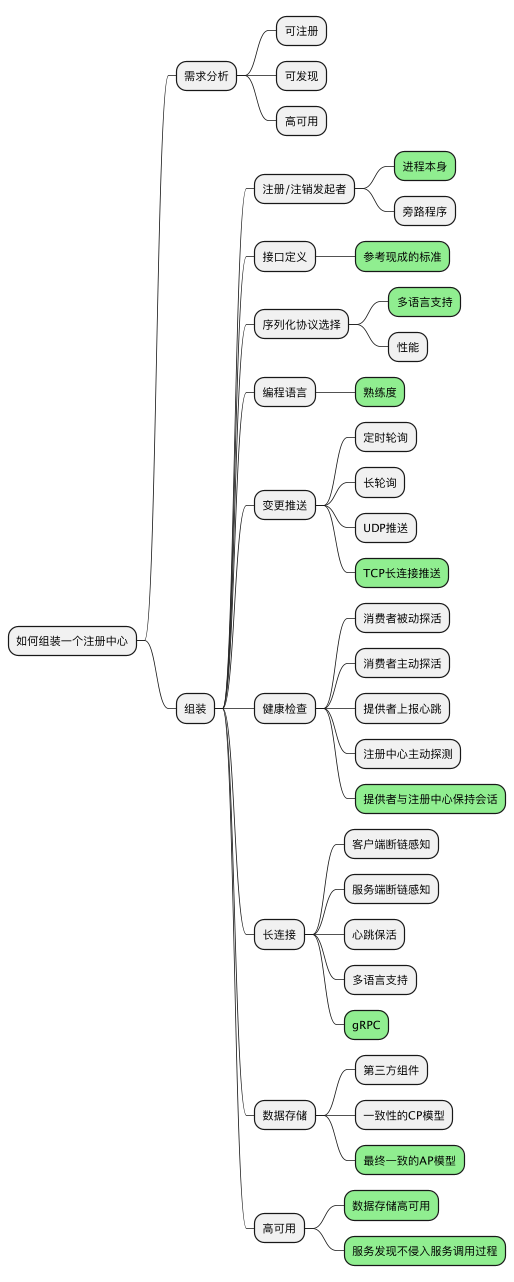
122.8 KB
{kind=link}
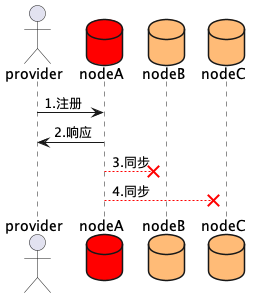
14.3 KB
{kind=link}
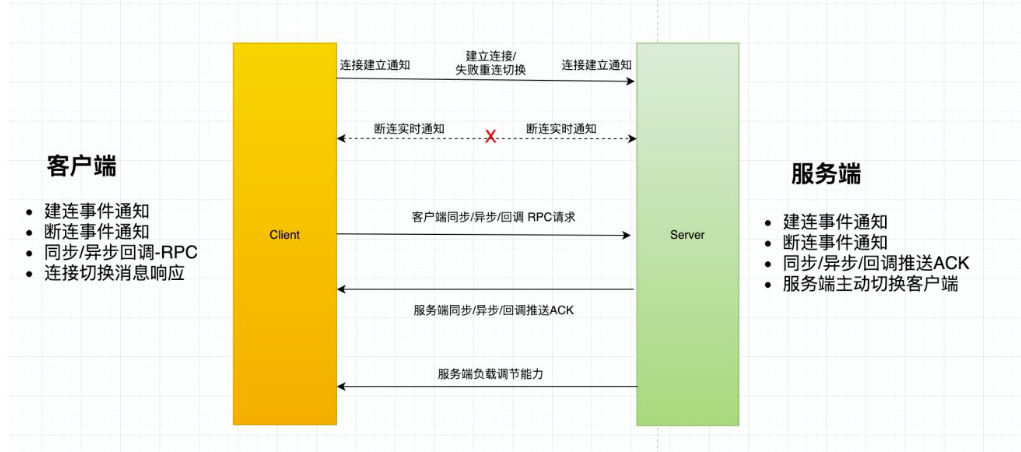
348.3 KB
{kind=link}

107.3 KB
{kind=link}

62.9 KB
{kind=link}

88.7 KB
{kind=link}
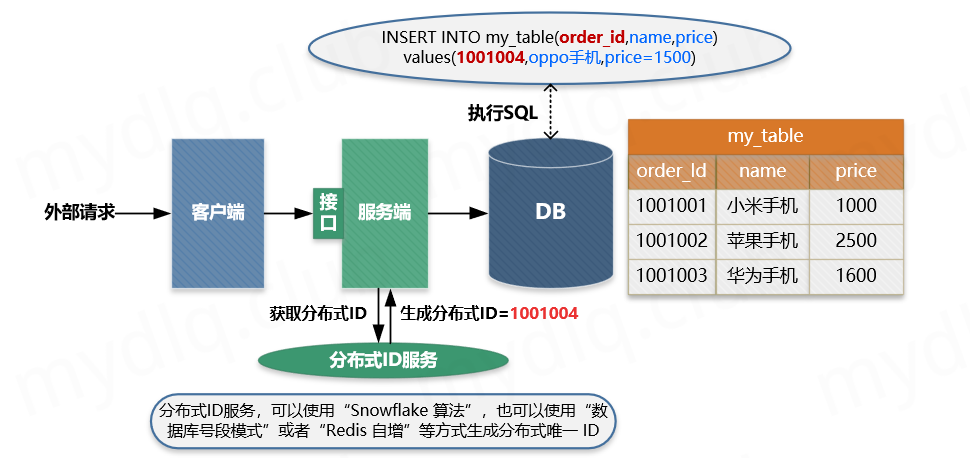
93.8 KB
{kind=link}
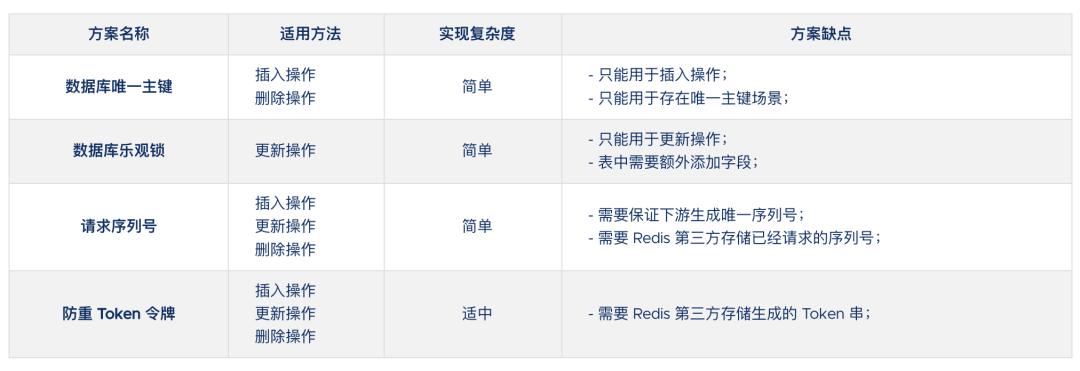
97.7 KB
{kind=link}
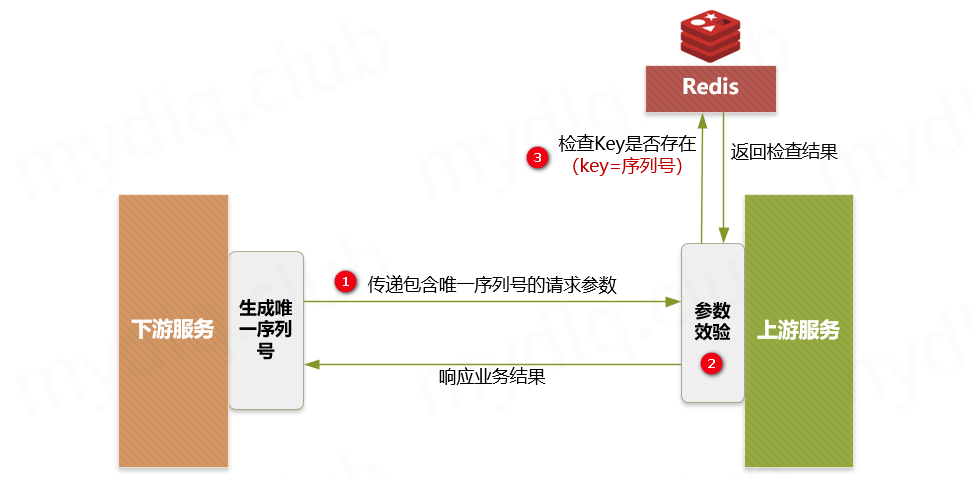
67.5 KB
{kind=link}
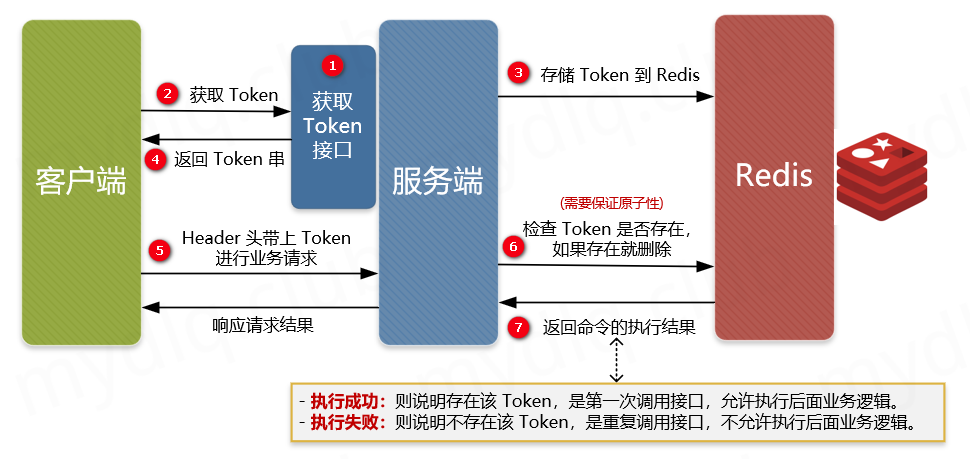
91.2 KB
{kind=link}

10.7 KB