paddle训练反向传播报错 IndexError: _Map_base::at
Created by: linan142857
`
# define network
inputs, labels = init_inputs(args, pad_num)
# conv feature
block_feats = get_base_features(inputs['node_images'])
# node feats
roi_feats = get_roi_features(block_feats, inputs['node_roi'])
# node mask
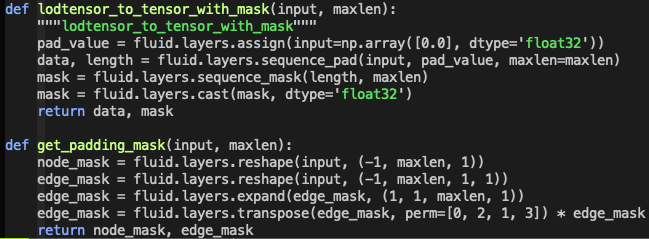
roi_feats, mask = lodtensor_to_tensor_with_mask(roi_feats, pad_num)
node_mask, edge_mask = get_padding_mask(mask, pad_num)
# relation loss
feats = get_graph_features(roi_feats,
inputs['node_shape'], inputs['edge_shape'],
node_mask, edge_mask, pad_num)
node_out, edge_out = graph_net(feats['node_feats'], feats['edge_feats'],
feats['edge_shape_feats'], node_mask, edge_mask, pad_num)
node_label = fluid.layers.cast(x=labels['node_label'], dtype='int64')
node_loss = fluid.layers.softmax_with_cross_entropy(node_out, node_label)
node_loss = fluid.layers.reduce_sum(node_loss * node_mask)
edge_label = fluid.layers.unsqueeze(labels['edge_label'], axes=[3])
fg_num = fluid.layers.reduce_sum(edge_label, dim=[1, 2, 3])
edge_label = fluid.layers.cast(x=edge_label, dtype='float32')
edge_loss = fluid.layers.sigmoid_focal_loss(edge_out, edge_label, fg_num, gamma=2.0, alpha=0.25)
edge_loss = fluid.layers.reduce_sum(edge_loss * edge_mask)
cost = node_loss + edge_loss * args.lamb
# evaluate
node_index = fluid.layers.argmax(node_out, axis=2)
node_index = fluid.layers.cast(node_index, dtype='int32')
edge_score = fluid.layers.sigmoid(edge_out)
fetch_vars = [node_loss, edge_loss, node_index,
edge_score, node_mask, edge_mask]
inference_program = fluid.default_main_program().clone(for_test=True)
if args.learning_rate_decay == "piecewise_decay":
learning_rate = fluid.layers.piecewise_decay([
args.total_step // 4, args.total_step // 4 * 3
], [args.lr, args.lr * 0.1, args.lr * 0.01])
else:
learning_rate = lr
optimizer = fluid.optimizer.Adam(learning_rate=learning_rate)
_, params_grads = optimizer.minimize(cost)`实现了一个lod_tensor加padding转成tensor的函数如下:
报错
Traceback (most recent call last): File "model/train.py", line 262, in main() File "model/train.py", line 258, in main train(args) File "model/train.py", line 119, in train _, params_grads = optimizer.minimize(cost) File "</home/liyulin/anaconda2/lib/python2.7/site-packages/decorator.pyc:decorator-gen-20>", line 2, in minimize File "/home/liyulin/anaconda2/lib/python2.7/site-packages/paddle/fluid/wrapped_decorator.py", line 25, in impl return wrapped_func(*args, **kwargs) File "/home/liyulin/anaconda2/lib/python2.7/site-packages/paddle/fluid/dygraph/base.py", line 87, in impl return func(*args, **kwargs) File "/home/liyulin/anaconda2/lib/python2.7/site-packages/paddle/fluid/optimizer.py", line 609, in minimize no_grad_set=no_grad_set) File "/home/liyulin/anaconda2/lib/python2.7/site-packages/paddle/fluid/optimizer.py", line 494, in backward no_grad_set, callbacks) File "/home/liyulin/anaconda2/lib/python2.7/site-packages/paddle/fluid/backward.py", line 706, in append_backward append_backward_vars(root_block, fwd_op_num, grad_to_var, grad_info_map) File "/home/liyulin/anaconda2/lib/python2.7/site-packages/paddle/fluid/backward.py", line 518, in append_backward_vars op_desc.infer_shape(block.desc) IndexError: _Map_base::at