BERT predict_classifier.py脚本保存的inference_model需要怎么使用load使用
Created by: wwjjy
我想通过load_inference_model函数来加载模型参数,然后进行预测,代码如下: args = parser.parse_args() place = fluid.CPUPlace() exe = fluid.Executor(place) task_name = args.task_name.lower() processors = { 'xnli': reader.XnliProcessor, 'cola': reader.ColaProcessor, 'mrpc': reader.MrpcProcessor, 'mnli': reader.MnliProcessor, }
processor = processors[task_name](data_dir=args.data_dir, vocab_path=args.vocab_path, max_seq_len=args.max_seq_len, do_lower_case=args.do_lower_case, in_tokens=False) num_labels = len(processor.get_labels()) predict_pyreader = fluid.layers.py_reader( capacity=50, shapes=[[-1, args.max_seq_len, 1], [-1, args.max_seq_len, 1], [-1, args.max_seq_len, 1], [-1, args.max_seq_len, 1], [-1, 1]], dtypes=['int64', 'int64', 'int64', 'float32', 'int64'], lod_levels=[0, 0, 0, 0, 0], name='predict_reader', use_double_buffer=True) infer_program, feed_list, fetch_target = fluid.io.load_inference_model("infer_model/checkpoints_inference_model", exe) predict_pyreader.decorate_tensor_provider( processor.data_generator( batch_size=args.batch_size, phase='test', epoch=1, shuffle=False)) predict_pyreader.start() all_results = [] time_begin = time.time() while True: try: results = exe.run(infer_program, fetch_list=fetch_target) all_results.extend(results[0]) except fluid.core.EOFException: predict_pyreader.reset() break time_end = time.time()
np.set_printoptions(precision=4, suppress=True)
print("-------------- prediction results --------------")
print("example_id\t" + ' '.join(processor.get_labels()))
for index, result in enumerate(all_results):
print(str(index) + '\t{}'.format(result))
运行后错误信息如下:
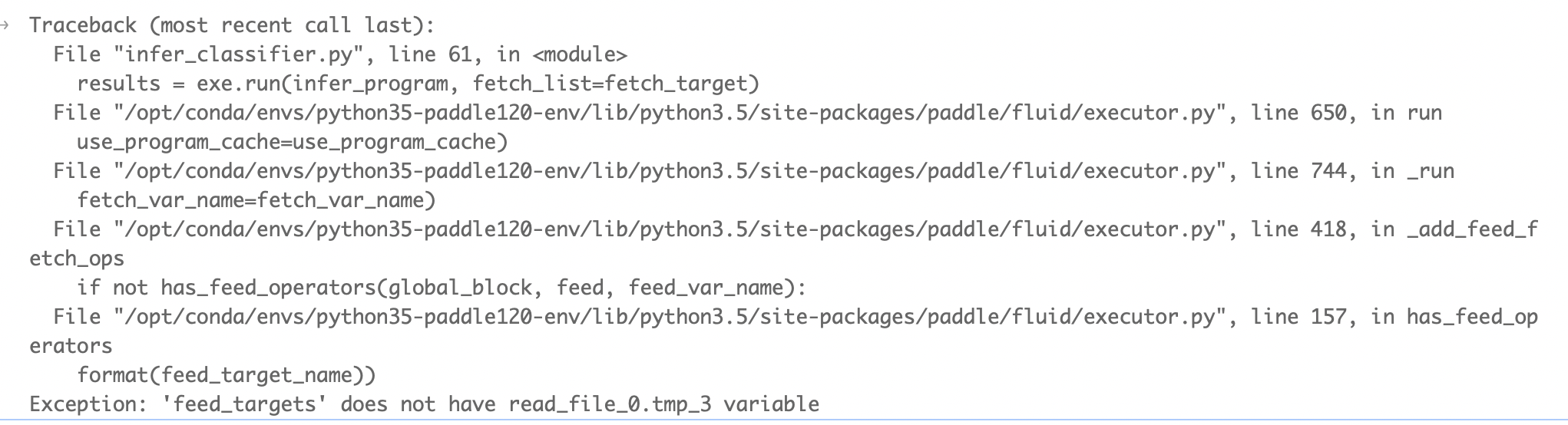 请问应该如何正确使用predict_classifier.py保存的固化模型
请问应该如何正确使用predict_classifier.py保存的固化模型