when using rankloss, learning performance of DSSM model is terrible.
Created by: lcy-seso
- DSSM 模型命令行指定
model_type=rank时,训练结果非常糟糕,我觉得可能存在以下问题:
-
DSSM 指定
model_type=rank时,实际上就是经典的Pairwise RankNet。 -
在RankNet中,神经网络对一个输入的”对“进行打分,学习一个标量分值作为输出。
-
以下是 RankLoss 计算的部分公式: $$P_{ij}=\frac{e^{o_{ij}}}{1+e^{o_{ij}}}$$ $$o_{ij} = o_i - o_j$$
-
在上面的公式中,网络对左右一对输入进行打分,分值相减得到 $o_{ij}$,$o_{ij}$ 通过指数公式转化为概率,最终的损失函数为基于概率的交叉熵。
-
ranknet的优化目标是希望推开左右两部分网络的得分,使他们之间差异尽可能大以提高泛化能力,一般不对$o_{i,j}$做值域的限制;一些含有指数项的激活函数,也可能会影响梯度的回传;
-
目前 Paddle 的dssm 模型使用 fc + cosine 的方式得到一维得分 $o_{i,j}$ ,cosine 的值域受限,落在 [-1,1]之内,于是会出现下图的情况,下图是[-1, 1] 区间上,$o_{ij}$ 和 $P_{ij}$ 变化曲线:
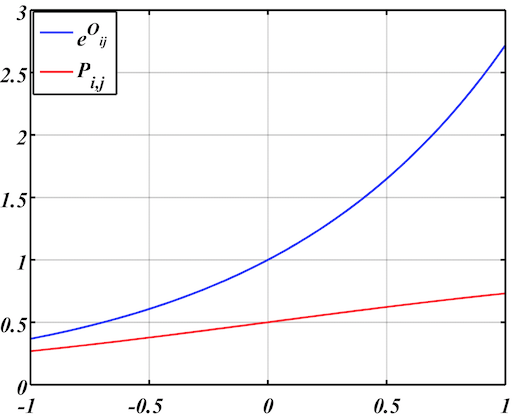
可以看出来,即使落在了$P_{ij}$的两个极端,对相关和不相关的区分力也是非常弱的。
我认为DSSM模型使用rankloss时,目前配置部分有问题,不应该使用cosine 得到一维分值,而是使用全连接映射到一维,并且不使用任何非线性激活。
ltr 目录下的 ranknet,配置更为合理: https://github.com/PaddlePaddle/models/blob/develop/ltr/ranknet.py#L32