请教:gru训练语言模型,多GPU速度和单GPU速度基本一致,这是什么原因啊?
Created by: Melonzhou
训练代码:https://github.com/PaddlePaddle/models/blob/develop/PaddleNLP/language_model/gru/train.py
使用的上面给代码,稍微做了一些小修改,修改内容如下。
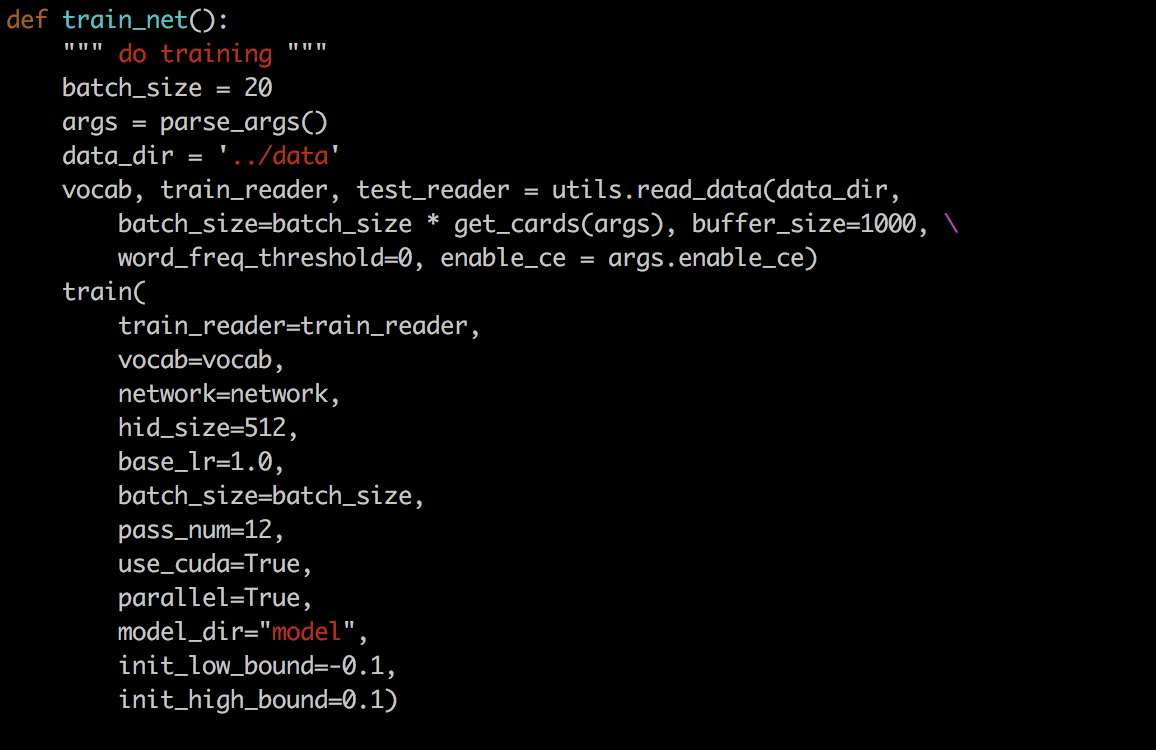
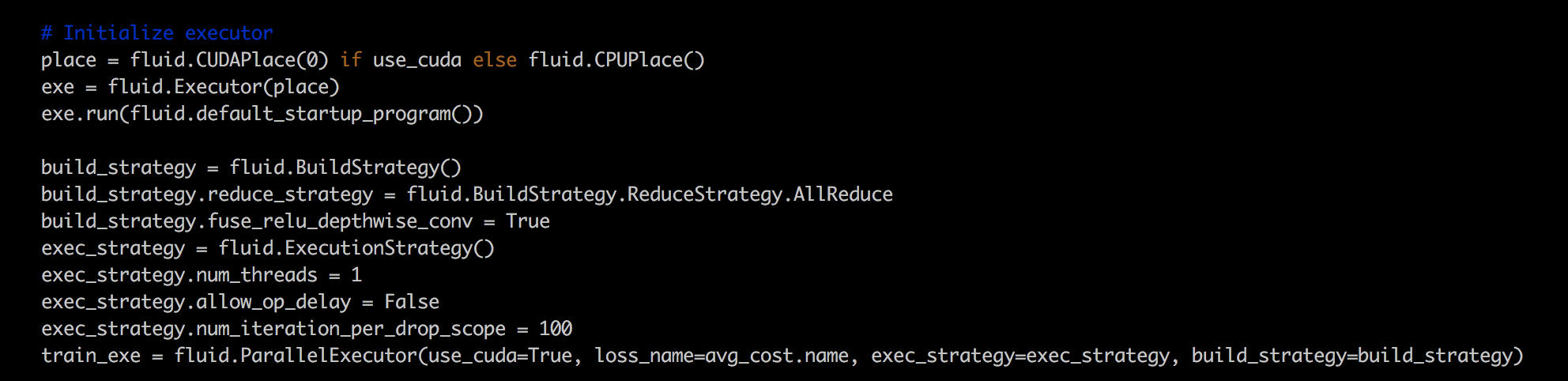
运行脚本:
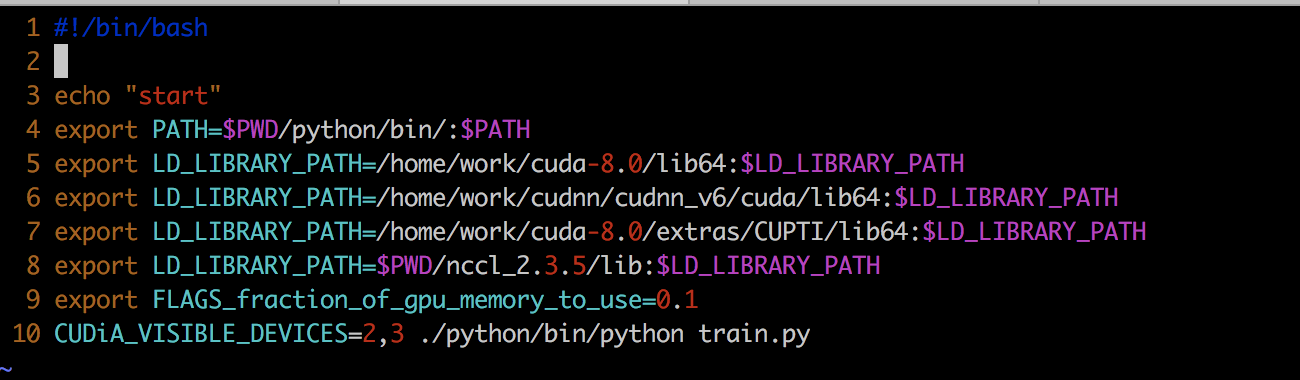 训练数据:github提供的ptb数据
训练数据:github提供的ptb数据
paddle版本paddlepaddle-gpu 1.3.0.post85 。
训练速度:Tesla K40,单卡(GPU)一个epoch约100s,2个卡一个epoch约100s,时间几乎一致。