Train ds2 on THCHS30 (WIP)
Created by: pkuyym
I am trying to train ds2 on THCHS30 which is a mandarin dataset. A phenomenon is that we encounter error explosion easily when batch_size is big liking 64, 128 or 256. I try to clip the error to 1000 when inf appears. The clipping operation is very tricky, I catch inf and clip in paddle/v2/trainer.py as following:
cost_sum = out_args.sum()
import math
if (math.isinf(cost_sum)): cost_sum = 1000.0
cost = cost_sum / len(data_batch)We can train ds2 normally after adding the clipping operation. I have tried to train the model using batch_shuffle_clipped provider and instance_shuffle provider. The learning curves are as following:
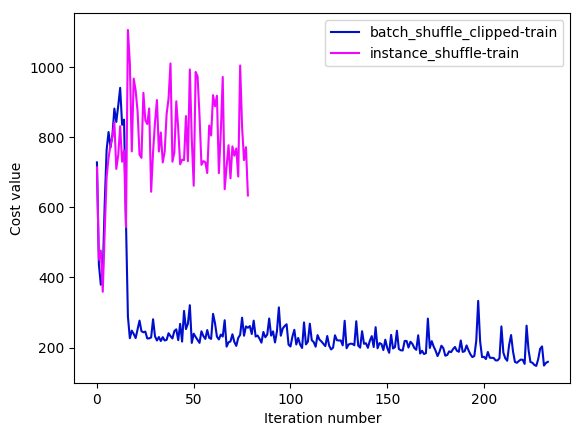 As we can see,
As we can see, instance_shuffle converges badly and I abandon this configuration after training several iterations. The batch_shuffle_clipped configuration looks like converging very slowly when the training cost goes down to 170~. The key settings of above experiments are:
| setting | value |
|---|---|
| batch_size | 64 |
| trainer_count | 4 |
| num_conv_layers | 2 |
| adam_learning_rate | 0.0005 |
I also product another experiment on a tiny dataset which only contains 128 samples (first 128). Training data and validation data both use the tiny dataset. Training settings are same with above. Following are the learning curves:

From the figure above we can learn that the convergence is very unstable and slow. There exists a unreasonable gap between training curve and validation curve. Since the training data and validation data are same, the difference of two curves should be minor. Will figure out the reason of the anomalies.