Merge learning rate decay
Showing
fluid/face_detection/data_util.py
0 → 100644
fluid/face_detection/profile.py
0 → 100644
fluid/icnet/README.md
0 → 100644
fluid/icnet/cityscape.py
0 → 100644
fluid/icnet/eval.py
0 → 100644
fluid/icnet/icnet.py
0 → 100644
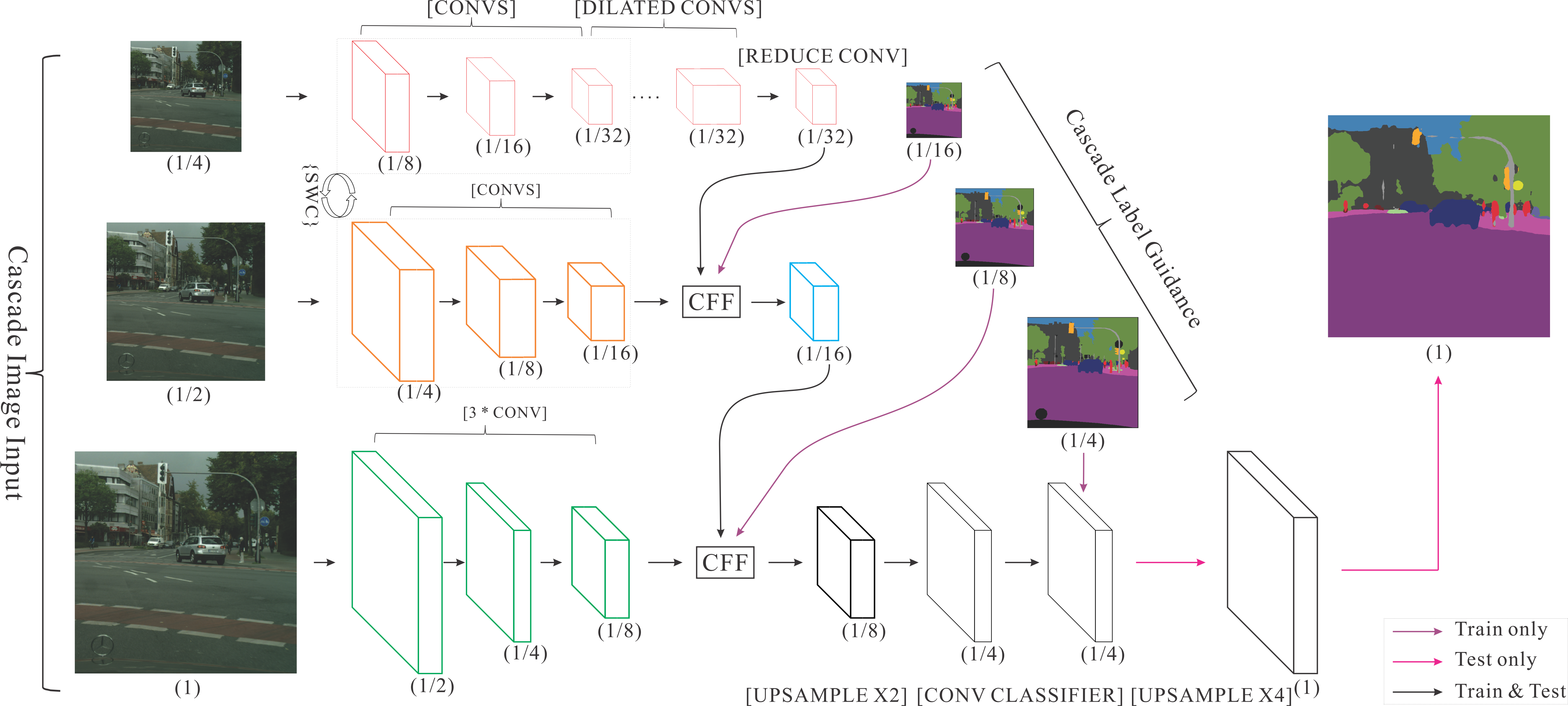
fluid/icnet/images/icnet.png
0 → 100644
{kind=link}
2.0 MB
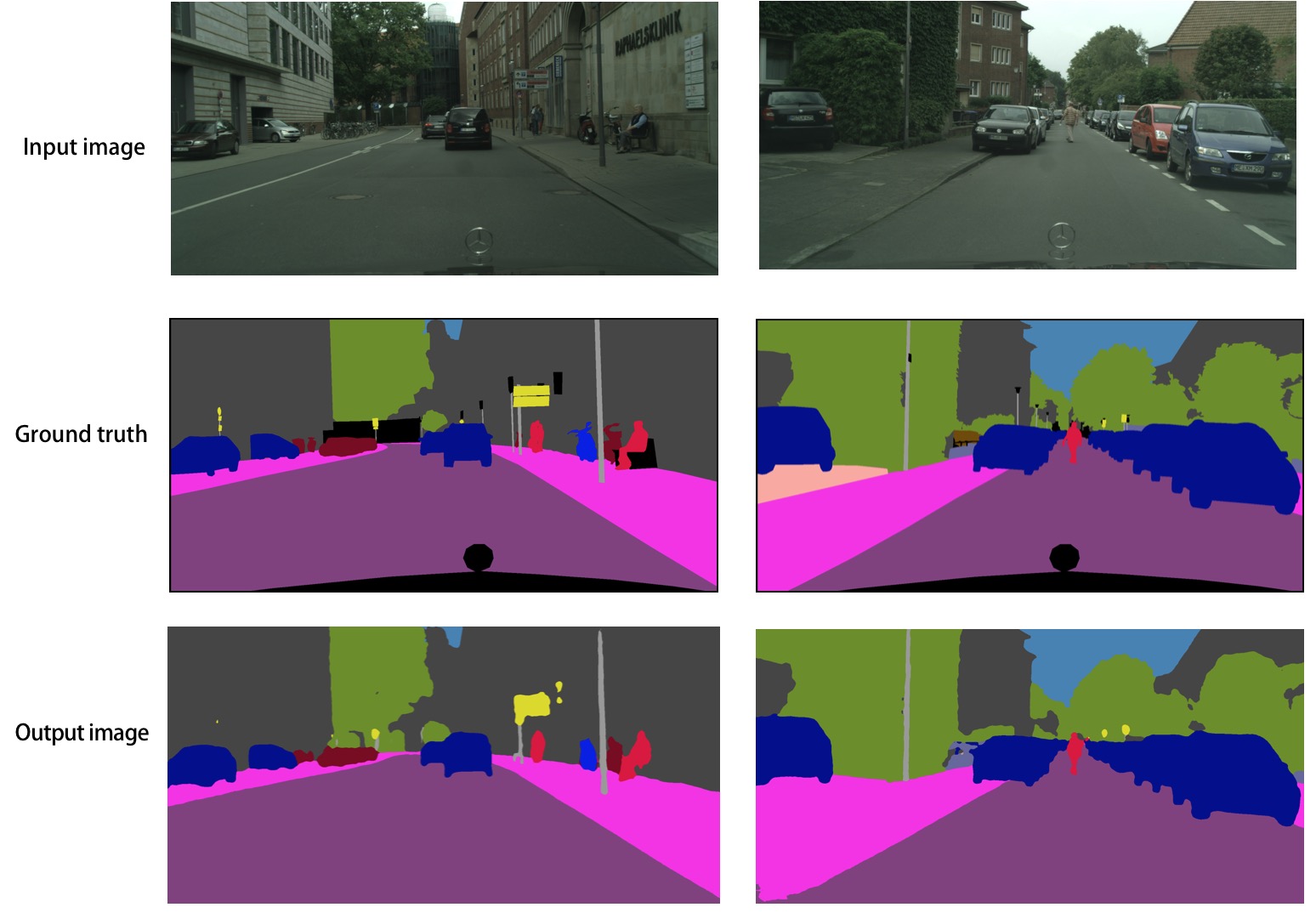
fluid/icnet/images/result.png
0 → 100644
{kind=link}
207.7 KB
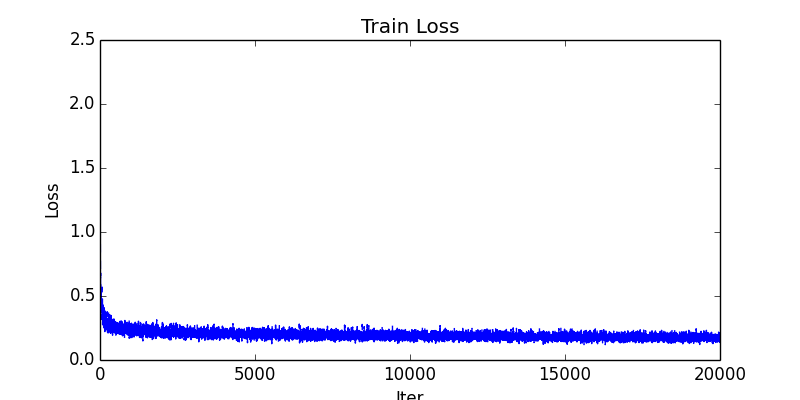
fluid/icnet/images/train_loss.png
0 → 100644
{kind=link}
19.4 KB
fluid/icnet/infer.py
0 → 100644
fluid/icnet/train.py
0 → 100644
fluid/icnet/utils.py
0 → 100644
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H: