@@ -72,12 +72,14 @@ As an example for sequence-to-sequence learning, we take the machine translation
## 9. Image classification
For the example of image classification, we show you how to train AlexNet, VGG, GoogLeNet, ResNet and Inception-v4 models in PaddlePaddle. It also provides a model conversion tool that converts Caffe trained model files into PaddlePaddle model files.
For the example of image classification, we show you how to train AlexNet, VGG, GoogLeNet, ResNet, Inception-v4 and Inception-Resnet-V2 models in PaddlePaddle. It also provides model conversion tools that convert Caffe or TensorFlow trained model files into PaddlePaddle model files.
- 9.1 [convert Caffe model file to PaddlePaddle model file](https://github.com/PaddlePaddle/models/tree/develop/image_classification/caffe2paddle)
@@ -120,7 +120,7 @@ The model structure is as follows:
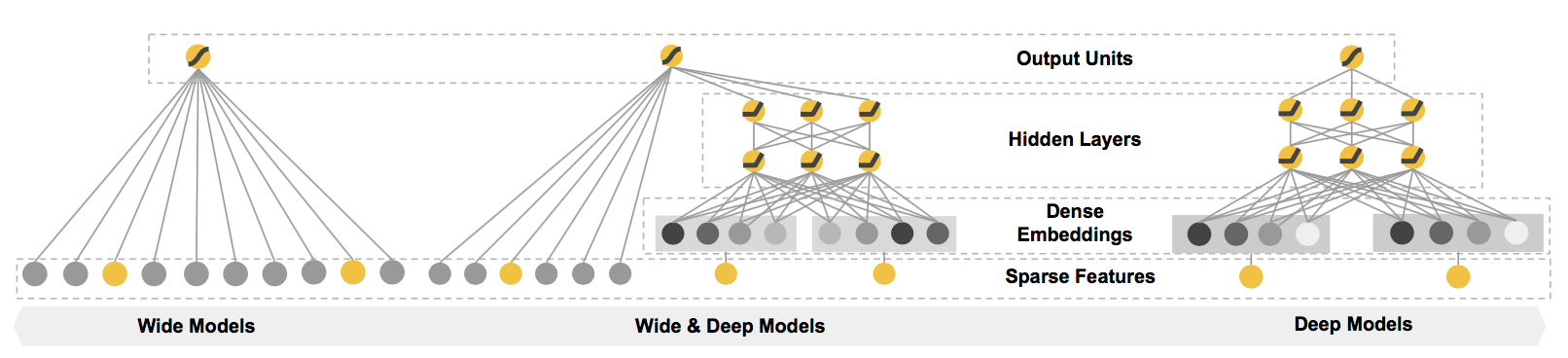
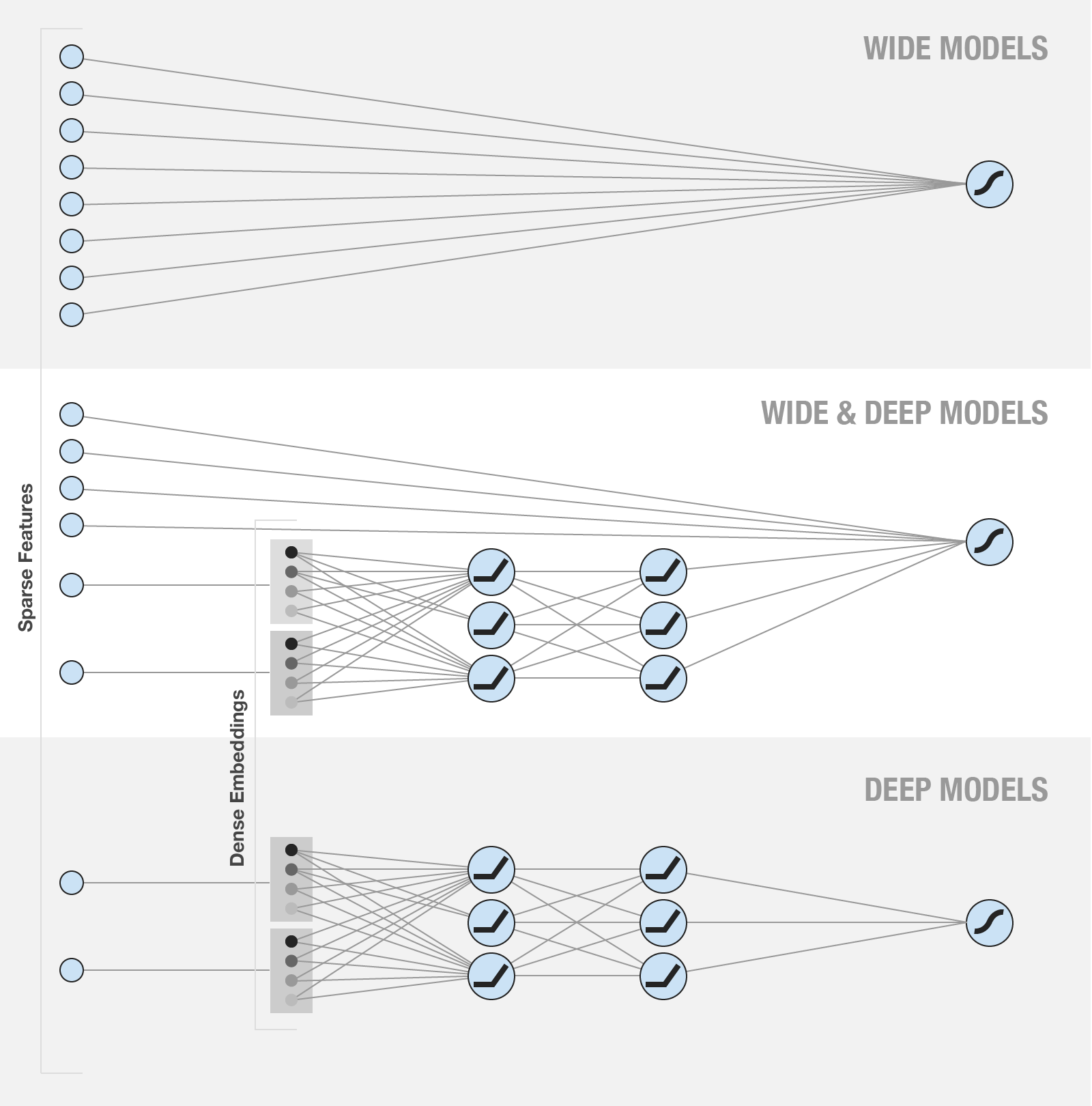
Figure 2. Wide & Deep Model
</p>
The wide part of the left side of the model can accommodate large-scale coefficient features and has some memory for some specific information (such as ID); and the Deep part of the right side of the model can learn the implicit relationship between features.
The wide part of the top side of the model can accommodate large-scale coefficient features and has some memory for some specific information (such as ID); and the Deep part of the bottom side of the model can learn the implicit relationship between features.
{kind=link}
{kind=link}