DNN与CNN模型之间最大的区别在于:CNN是一种序列模型,能够提取一个局部区域之内的特征,能够处理变长的序列输入。而DNN大多使用基本的全连接结构,不是一种序列模型,只能接受固定维度的特征向量作为输入。举例来说,情感分类是一项常见的文本分类任务,在情感分类中,我们希望训练一个模型来判断句子中表现出的情感是正向还是负向。例如,"The apple is not bad",其中的"not bad"是决定这个句子情感的关键。对于DNN模型来说,只能知道句子中有一个"not"和一个"bad",并且在输入时“not”和“bad”之间的顺序关系已经丢失,网络不再有机会学习到序列之间蕴含的特征;而CNN模型接受文本序列作为输入,保留了"not bad"之间的顺序信息。因此,在大多数文本分类任务上,CNN模型的表现要好于DNN。
DNN与CNN模型之间最大的区别在于:
- DNN不属于序列模型,大多使用基本的全连接结构,只能接受固定维度的特征向量作为输入。
- CNN属于序列模型,能够提取一个局部区域之内的特征,能够处理变长的序列输入。
举例来说,情感分类是一项常见的文本分类任务,在情感分类中,我们希望训练一个模型来判断句子中表现出的情感是正向还是负向。例如,"The apple is not bad",其中的"not bad"是决定这个句子情感的关键。
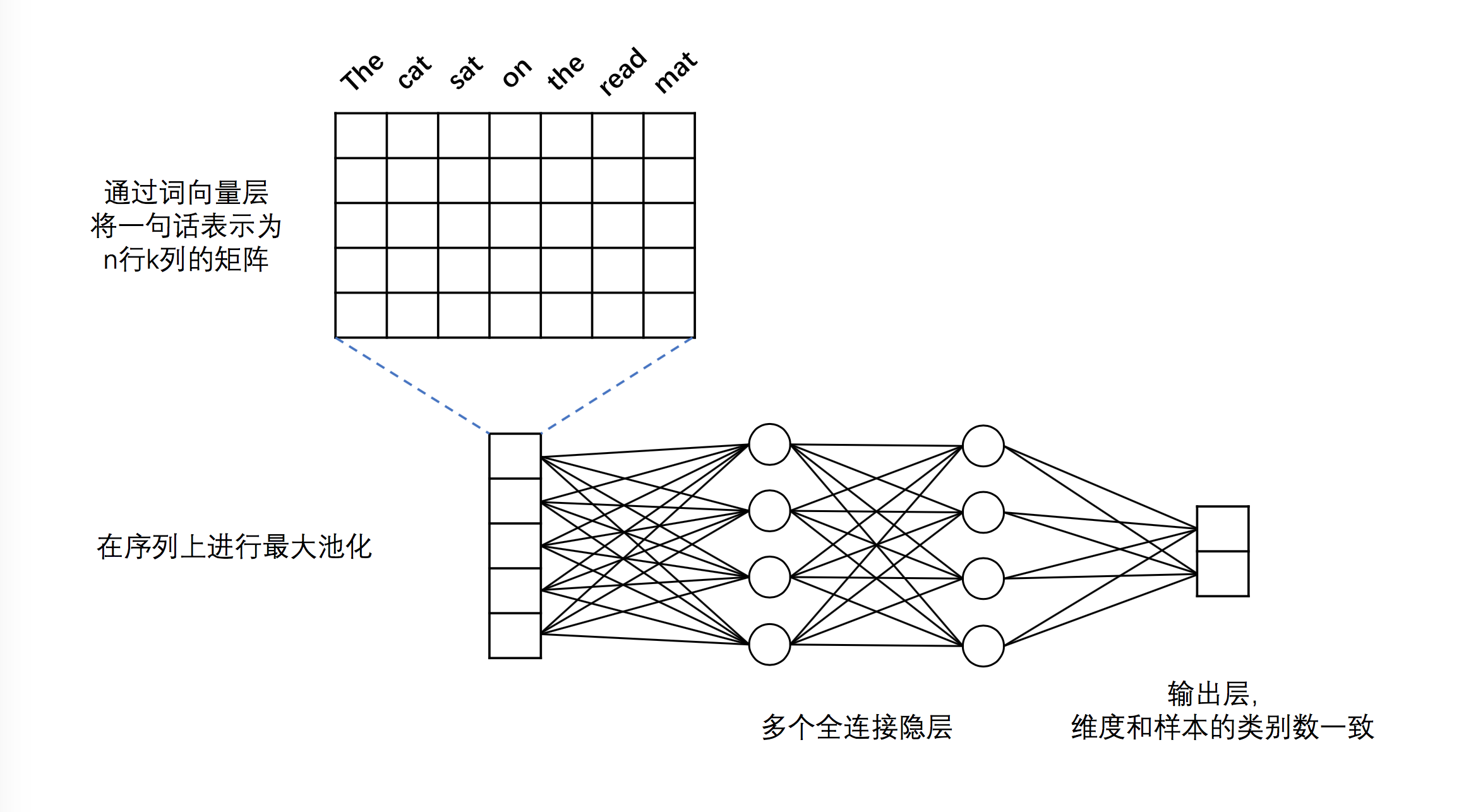
-**词向量层**:与DNN中词向量层的作用一样,将英文单词转化为固定维度的向量,利用向量之间的距离来表示词之间的语义相关程度。如图2中所示,将得到的词向量定义为行向量,再将语料中所有的单词产生的行向量拼接在一起组成矩阵。假设词向量维度为5,语料“The cat sat on the read mat”包含7个单词,那么得到的矩阵维度为7*5。关于词向量的更多信息请参考PaddleBook中的[词向量](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec)一节。
-**词向量层**:与DNN中词向量层的作用一样,将英文单词转化为固定维度的向量,利用向量之间的距离来表示词之间的语义相关程度。如图2中所示,将得到的词向量定义为行向量,再将语料中所有的单词产生的行向量拼接在一起组成矩阵。假设词向量维度为5,语料“The cat sat on the read mat”包含7个单词,那么得到的矩阵维度为7*5。关于词向量的更多信息请参考PaddleBook中的[词向量](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec)一节。
{kind=link}
{kind=link}