@@ -90,21 +90,11 @@ To train the model, [cocoapi](https://github.com/cocodataset/cocoapi) is needed.
...
@@ -90,21 +90,11 @@ To train the model, [cocoapi](https://github.com/cocodataset/cocoapi) is needed.
* Use momentum optimizer with momentum=0.9.
* Use momentum optimizer with momentum=0.9.
* Weight decay is 0.0001.
* Weight decay is 0.0001.
* In first 500 iteration, the learning rate increases linearly from 0.00333 to 0.01. Then lr is decayed at 120000, 160000 iteration with multiplier 0.1, 0.01. The maximum iteration is 180000.
* In first 500 iteration, the learning rate increases linearly from 0.00333 to 0.01. Then lr is decayed at 120000, 160000 iteration with multiplier 0.1, 0.01. The maximum iteration is 180000. Also, we released a 2x model which has 360000 iterations and lr is decayed at 240000, 320000. These configuration can be set by max_iter and lr_steps in config.py.
* Set the learning rate of bias to two times as global lr in non basic convolutional layers.
* Set the learning rate of bias to two times as global lr in non basic convolutional layers.
* In basic convolutional layers, parameters of affine layers and res body do not update.
* In basic convolutional layers, parameters of affine layers and res body do not update.
* Use Nvidia Tesla V100 8GPU, total time for training is about 40 hours.
* Use Nvidia Tesla V100 8GPU, total time for training is about 40 hours.
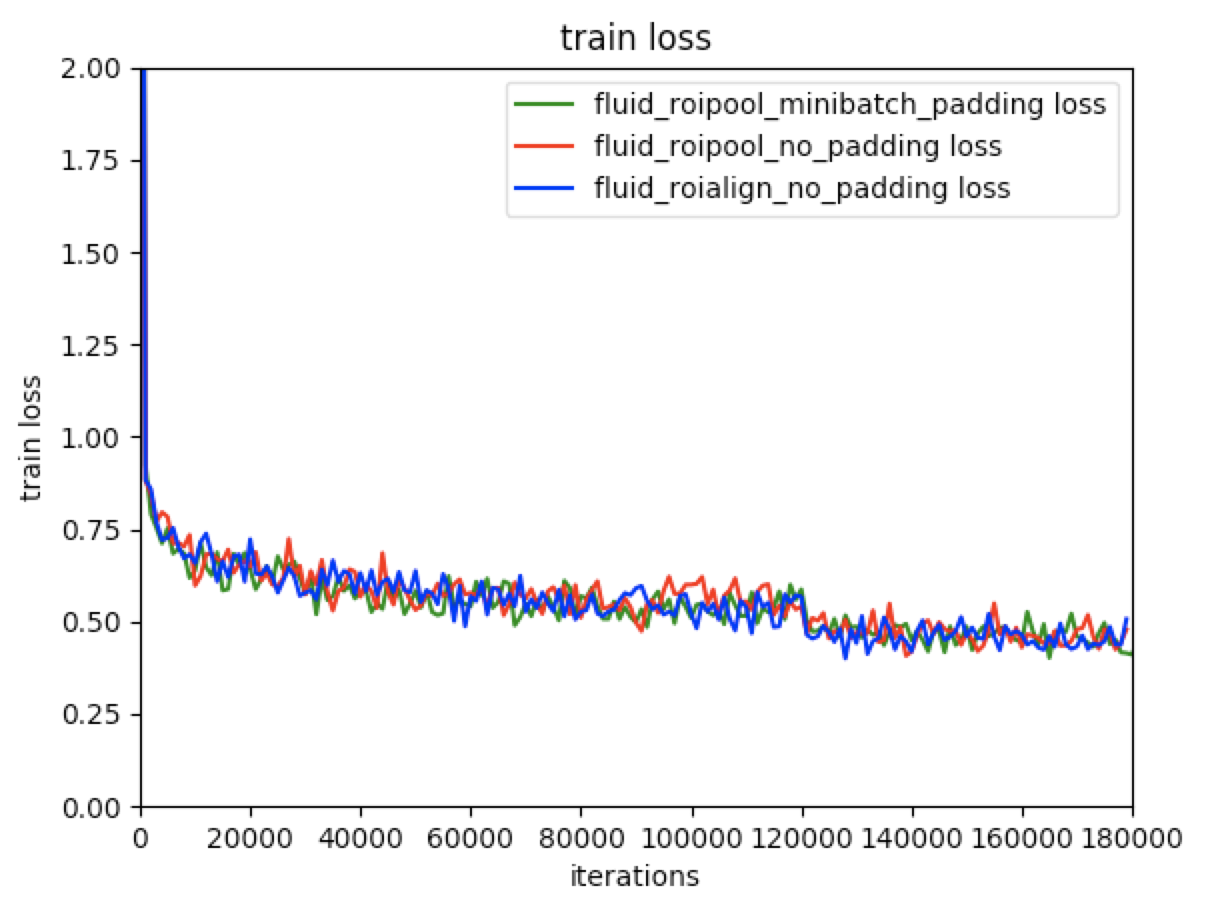
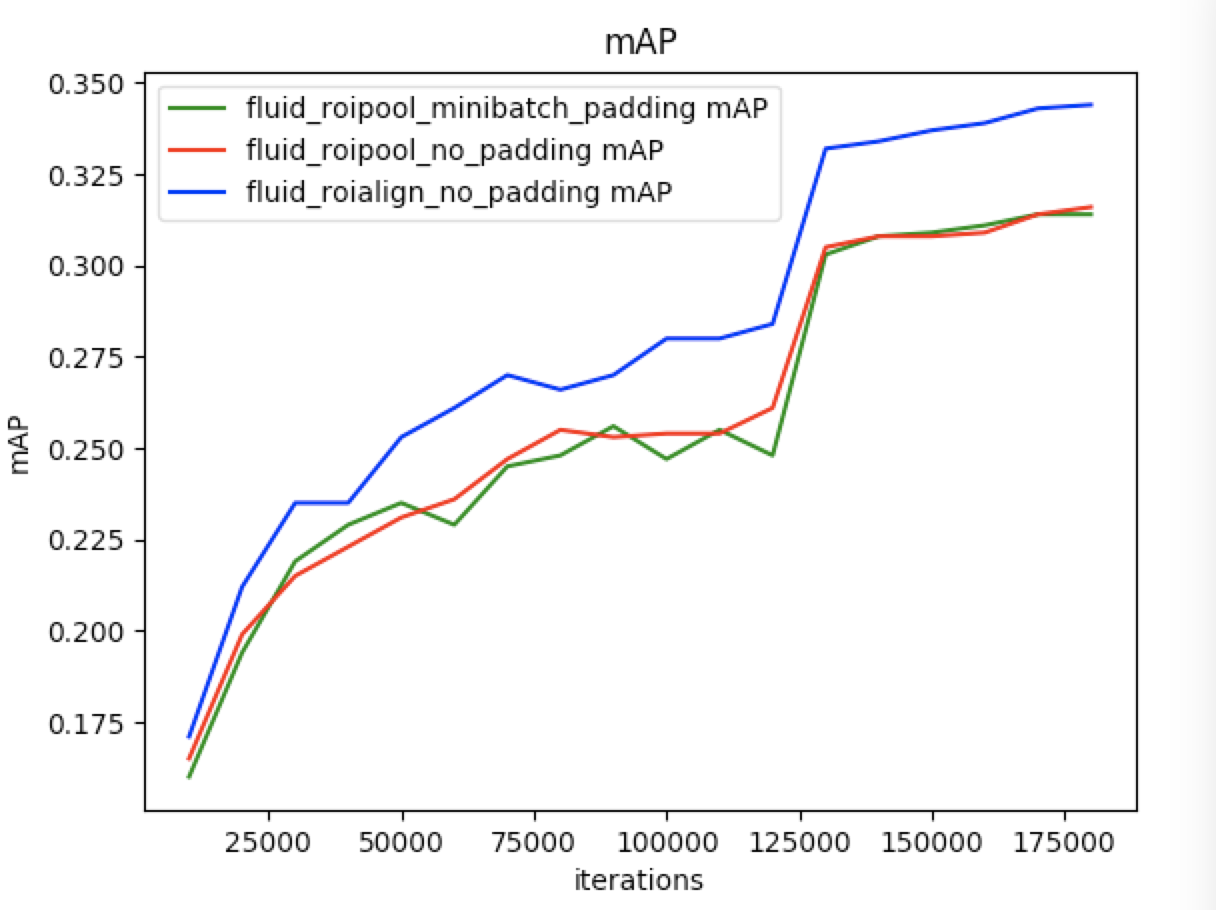
* Fluid RoIPool minibatch padding: Use RoIPool. Images in one batch padding to the same size. This method is same as detectron.
* Fluid RoIpool no padding: Use RoIPool. Images without padding.
* Fluid RoIAlign no padding: Use RoIAlign. Images without padding.
## Evaluation
## Evaluation
Evaluation is to evaluate the performance of a trained model. This sample provides `eval_coco_map.py` which uses a COCO-specific mAP metric defined by [COCO committee](http://cocodataset.org/#detections-eval).
Evaluation is to evaluate the performance of a trained model. This sample provides `eval_coco_map.py` which uses a COCO-specific mAP metric defined by [COCO committee](http://cocodataset.org/#detections-eval).
...
@@ -118,20 +108,18 @@ Evaluation is to evaluate the performance of a trained model. This sample provid
...
@@ -118,20 +108,18 @@ Evaluation is to evaluate the performance of a trained model. This sample provid
- Set ```export CUDA_VISIBLE_DEVICES=0``` to specifiy one GPU to eval.
- Set ```export CUDA_VISIBLE_DEVICES=0``` to specifiy one GPU to eval.
{kind=link}
{kind=link}