Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
d7cf2a53
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
“86fd748808dee2448bf368f3b1389f91ec6e9d29”上不存在“develop/doc/howto/usage/cmd_parameter/index_en.html”
提交
d7cf2a53
编写于
11月 08, 2019
作者:
A
aprilvkuo
提交者:
pkpk
11月 08, 2019
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
dialogue_domain_classification init (#3839)
上级
695e8f40
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
1250 addition
and
0 deletion
+1250
-0
PaddleNLP/dialogue_domain_classification/README.MD
PaddleNLP/dialogue_domain_classification/README.MD
+223
-0
PaddleNLP/dialogue_domain_classification/imgs/function.png
PaddleNLP/dialogue_domain_classification/imgs/function.png
+0
-0
PaddleNLP/dialogue_domain_classification/imgs/nets.png
PaddleNLP/dialogue_domain_classification/imgs/nets.png
+0
-0
PaddleNLP/dialogue_domain_classification/nets.py
PaddleNLP/dialogue_domain_classification/nets.py
+96
-0
PaddleNLP/dialogue_domain_classification/run.sh
PaddleNLP/dialogue_domain_classification/run.sh
+118
-0
PaddleNLP/dialogue_domain_classification/run_classifier.py
PaddleNLP/dialogue_domain_classification/run_classifier.py
+459
-0
PaddleNLP/dialogue_domain_classification/utils.py
PaddleNLP/dialogue_domain_classification/utils.py
+354
-0
未找到文件。
PaddleNLP/dialogue_domain_classification/README.MD
0 → 100755
浏览文件 @
d7cf2a53
# Paddle NLP(对话领域分类器)
## 模型简介
在对话业务场景中,完整的对话能力往往由多个领域的语义解析bot组成并提供,对话领域分类器能够根据业务场景需求,将流量分发到对应领域的语义解析bot。对话领域分类器不但能够节省机器资源,流量只分发到所属领域的bot,避免了无效流量调用bot; 同时,对话领域分类器的精准分发,过滤了无效的解析结果,也使得最终的解析结果更加精确。
## 快速开始
**目前模型要求使用PaddlePaddle 1.6及以上版本或适当的develop版本运行。**
### 1. Paddle版本安装
本项目训练模块兼容Python2.7.x以及Python3.7.x, 依赖PaddlePaddle 1.6版本以及CentOS系统环境, 安装请参考官网
[
快速安装
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/install/index_cn.html
)
。
注意:该模型同时支持cpu和gpu训练和预测,用户可以根据自身需求,选择安装对应的paddlepaddle-gpu或paddlepaddle版本。
> Warning: GPU 和 CPU 版本的 PaddlePaddle 分别是 paddlepaddle-gpu 和 paddlepaddle,请安装时注意区别。
### 2. 代码安装
克隆工具集代码库到本地
```
shell
git clone https://github.com/PaddlePaddle/models.git
cd
models/PaddleNLP/dialogue_domain_classification
```
### 3. 数据准备
本项目提供了部分涉及的数据集,通过运行以下指令可以快速下载。运行指令后会生成
`data/input`
目录,
`data/input`
目录下有训练集数据(train.txt)、开发集数据(eval.txt)、测试集数据(test.txt),对应词典(char.dict),领域词表(domain.dict) 以及模型配置文件(model.conf)
```
shell
mkdir
-p
data/input
wget
--no-check-certificate
https://baidu-nlp.bj.bcebos.com/dialogue_domain_classification-dataset-1.0.0.tar.gz
tar
-zxvf
dialogue_domain_classification-dataset-1.0.0.tar.gz
-C
./data/input
```
**数据格式说明**
1.
数据格式
输入和输出的数据格式相同。
数据格式为: query
\t
domain_1
\0
02 domain_2 (多个标签, 使用
\0
02分隔开)
指定输入数据的文件夹: 参数
`data_dir`
训练文件: train.txt
验证集: eval.txt
测试集: test.txt
指定输出结果的文件夹: 参数
`save_dir`
测试集预测结果为: test.rst
2.
模型配置
参数
`config_path`
指定模型配置文件地址, 格式如下:
```
shell
[
model]
emb_dim
=
128
win_sizes
=
[
5, 5, 5]
hid_dim
=
160
hid_dim2
=
160
```
### 4. 模型下载
针对于"打电话, 天气, 火车票预订, 机票预订, 音乐"这5个领域数据,我们开源了一个使用CharCNN训练好的对话领域分类模型,使用以下指令可以对模型进行下载。
```
model
mkdir -p model
wget --no-check-certificate https://baidu-nlp.bj.bcebos.com/dialogue_domain_classification-model-1.0.0.tar.gz
tar -zxvf dialogue_domain_classification-model-1.0.0.tar.gz -C ./model
```
### 5. 脚本参数说明
通过执行如下指令,可以查看入口脚本文件所需要的参数以及说明,指令如下:
`export PATH="/path/to/your/python:$PATH"; python run_classifier.py --help `
```
shell
1. 模型参数
--init_checkpoint
# 指定热启动加载的checkpoint模型, Default: None.
--checkpoints
# 指定保存checkpoints的地址,Default: ./checkpoints.
--config_path
# 指定模型配置文件,Default: ./data/input/model.conf.
--build_dict
# 是否根据训练数据建立char字典和domain字典,Default: False
2. 训练参数
--epoch
# 训练的轮次,Default: 100.
--learning_rate
# 学习率, Default: 0.1.
--save_steps
# 保存模型的频率,每x个steps保存一次模型,Default: 1000.
--validation_steps
# 模型评估的频率,每x个steps在验证集上验证模型的效果,Default: 100.
--random_seed
# 随机数种子,Default: 7
--threshold
# 领域置信度阈值,当置信度超过阈值,预测结果出对应的领域标签。 Default: 0.1.
--cpu_num
# 当使用cpu训练时的线程数(当use_cuda=False才起作用)。 Default: 3.
3. logging
--skip_steps
# 训练时打印loss的频率,每x个steps打印一次loss,Default: 10.
4. 数据
--data_dir
# 数据集的目录,其中train.txt为训练集,eval.txt为验证集,test.txt为测试集。Default: ./data/input/
--save_dir
# 模型产出的目录, Default: ./data/output/
--max_seq_len
# 最大句子长度,超过会进行截断,Default: 50.
--batch_size
# 批大小, Default: 64.
5. 脚本运行配置
--use_cuda
# 是否使用GPU,Default: False
--do_train
# 是否进行训练,Default: True
--do_eval
# 是否进行验证,Default: True
--do_test
# 是否进行测试,Default: True
```
### 6. 模型训练
用户可以基于示例数据构建训练集和开发集,可以运行下面的命令,进行模型训练和开发集验证。
```
sh run.sh train
```
> Warning1: 可以参考`run.sh`脚本以及第5节的**脚本参数说明**, 对默认参数进行修改。
> Warning2: CPU多线程以及GPU多卡训练时,每个step训练分别给每一个CPU核或者GPU卡提供一个batch数据,实际上的batch_size为单核的线程数倍或者单卡的多卡数倍。
### 7. 模型评估
基于已有的预训练模型和数据,可以运行下面的命令进行测试,查看训练的模型在验证集(test.tsv)上的评测结果
```
sh run.sh eval
```
> Warning: 可以参考`run.sh`脚本以及第5节的**脚本参数说明**, 对默认参数进行修改。
### 8. 模型推断
```
sh run.sh test
```
> Warning: 可以参考`run.sh`脚本以及第5节的**脚本参数说明**, 对默认参数进行修改。
## 进阶使用
### 1. 任务定义与建模
在真实复杂业务场景中,语义解析服务往往由多个不同领域的语义解析bot组成,从而同时满足多个场景下的语义解析需求。例如:同时能查天气、播放音乐、查询股票等多种功能的对话bot。
与此同时用户输入的query句子形式各样,而且存在很多歧义。比如用户输入的query为
`“下雨了”`
, 这条query的语义解析既属于
`天气`
领域, 又属于
`音乐`
领域(薛之谦的歌曲)。针对这种多歧义的情况,业务上常见的方法是将query进行"广播",即同时请求每一个语义解析bot,再对返回的解析结果进行粗排,得到最终的语义解析结果。
对话领域分类器能够处理同一query同时命中多个领域的情况,根据对话领域分类器的解析结果,可以对query进行有效的分发到各个领域的bot。对话领域分类器对query进行有效的分发,可以避免"广播"式调用带来的资源浪费,大量的节省了机器资源;同时也提高了最终粗排后的语义解析结果的准确率。
对话领域分类模型解决了一个多标签分类(Multilabel Classification)的问题, 将用户输入的文本作为模型的输入,分类器会预测出输入文本对应的每一个标签的置信度,从而得到多标签结果,并依次对query分发。
### 2. 模型原理介绍
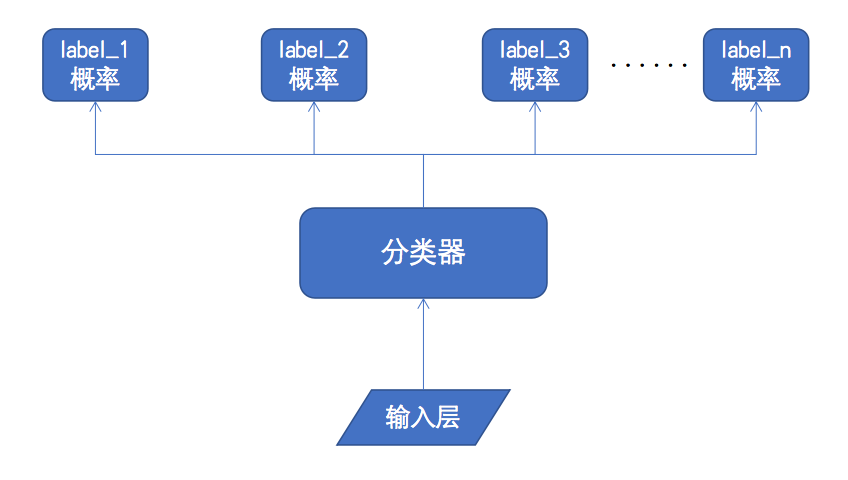
对话领域分类器的大体结构如下图所示,用户输入通过
`输入层`
进行向量化后,作为
`分类器模型`
的输入,
`分类器`
最终的输出是一个多标签结果为
`[label_1, label_2, ..., label_n]`
,它的维度为
`n`
.(训练数据定义的训练领域总共有
`n-1`
个,每一个领域对应一个标签,还有额外一个标签表示背景,即不属于任何一个训练领域)
其中每个
`label_i`
的概率为0到1之间,且所有label的概率之和不恒为1,它表示当前输入属于第
`i`
个领域的概率。最后可以人为对每一个label的概率设置阈值,从而可以得到多标签分类的结果。

**评估指标说明**
传统的二分类任务中,通常使用准确率、召回率和F1值对模型效果进行评估。
<p
align=
"center"
>

</p>
**该项目中对于正负样本的定义**
在多标签分类任务中,我们将样本分为正样本(Pos)与负样本(Neg)两种。如果样本包含了领域标签,表示需要分发到至少1个bot进行解析,则为正样本;反之,样本不包含任何领域标签流量,表示不需要分发,则为负样本。
我们的对话领域分类器在保证了原有解析效果的基础之上,有效的降低机器资源的消耗。即在保证正样本召回率的情况下,尽可能提高准确率。
**该项目中样本预测正确的定义**
1.
如果
`正确结果`
不包含领域标签, 则
`预测结果`
也不包含领域标签时,预测正确。
2.
如果
`正确结果`
包含领域标签, 则
`预测结果`
包含
`正确结果`
的所有领域标签时(即
`预测结果`
的标签是
`正确结果`
的超集,预测正确。
### 3. 代码结构说明
```
├── run_classifier.py:该项目的主函数,封装包括训练、预测、评估的部分
├── nets.py : 定义了模型所使用的网络结构
├── utils.py:定义了其他常用的功能函数
├── run.sh: 启动主函数的demo脚本
```
### 4. 如何组建自己的模型
可以根据自己的需求,组建自定义的模型,具体方法如下所示:
1.
定义自己的对话领域模型,可以在 ../models/classification/nets.py 中添加自己的网络结构。
2.
定义自己的领域对话数据,可以参考
**第3节数据准备**
的数据格式,准备自己的训练数据。
3.
模型训练、评估、预测的逻辑,需要在
[
run.sh
](
./run.sh
)
中修改对应的模型路径、数据路径和词典路径等参数,具体说明请参照
**第5节的脚本参数说明**
.
PaddleNLP/dialogue_domain_classification/imgs/function.png
0 → 100755
浏览文件 @
d7cf2a53
15.2 KB
PaddleNLP/dialogue_domain_classification/imgs/nets.png
0 → 100755
浏览文件 @
d7cf2a53
36.5 KB
PaddleNLP/dialogue_domain_classification/nets.py
0 → 100755
浏览文件 @
d7cf2a53
"""
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
import
paddle.fluid
as
fluid
import
paddle
def
textcnn_net_multi_label
(
data
,
label
,
dict_dim
,
emb_dim
=
128
,
hid_dim
=
128
,
hid_dim2
=
96
,
class_dim
=
2
,
win_sizes
=
None
,
is_infer
=
False
,
threshold
=
0.5
,
max_seq_len
=
100
):
"""
multi labels Textcnn_net
"""
init_bound
=
0.1
initializer
=
fluid
.
initializer
.
Uniform
(
low
=-
init_bound
,
high
=
init_bound
)
#gradient_clip = fluid.clip.GradientClipByNorm(10.0)
gradient_clip
=
None
regularizer
=
fluid
.
regularizer
.
L2DecayRegularizer
(
regularization_coeff
=
1e-4
)
seg_param_attrs
=
fluid
.
ParamAttr
(
name
=
"seg_weight"
,
learning_rate
=
640.0
,
initializer
=
initializer
,
gradient_clip
=
gradient_clip
,
trainable
=
True
)
fc_param_attrs_1
=
fluid
.
ParamAttr
(
name
=
"fc_weight_1"
,
learning_rate
=
1.0
,
regularizer
=
regularizer
,
initializer
=
initializer
,
gradient_clip
=
gradient_clip
,
trainable
=
True
)
fc_param_attrs_2
=
fluid
.
ParamAttr
(
name
=
"fc_weight_2"
,
learning_rate
=
1.0
,
regularizer
=
regularizer
,
initializer
=
initializer
,
gradient_clip
=
gradient_clip
,
trainable
=
True
)
if
win_sizes
is
None
:
win_sizes
=
[
1
,
2
,
3
]
# embedding layer
emb
=
fluid
.
embedding
(
input
=
data
,
size
=
[
dict_dim
,
emb_dim
],
param_attr
=
seg_param_attrs
)
# convolution layer
convs
=
[]
for
cnt
,
win_size
in
enumerate
(
win_sizes
):
emb
=
fluid
.
layers
.
reshape
(
x
=
emb
,
shape
=
[
-
1
,
1
,
max_seq_len
,
emb_dim
],
inplace
=
True
)
filter_size
=
(
win_size
,
emb_dim
)
cnn_param_attrs
=
fluid
.
ParamAttr
(
name
=
"cnn_weight"
+
str
(
cnt
),
learning_rate
=
1.0
,
regularizer
=
regularizer
,
initializer
=
initializer
,
trainable
=
True
)
conv_out
=
fluid
.
layers
.
conv2d
(
input
=
emb
,
num_filters
=
hid_dim
,
filter_size
=
filter_size
,
act
=
"relu"
,
\
param_attr
=
cnn_param_attrs
)
pool_out
=
fluid
.
layers
.
pool2d
(
input
=
conv_out
,
pool_type
=
'max'
,
pool_stride
=
1
,
global_pooling
=
True
)
convs
.
append
(
pool_out
)
convs_out
=
fluid
.
layers
.
concat
(
input
=
convs
,
axis
=
1
)
# full connect layer
fc_1
=
fluid
.
layers
.
fc
(
input
=
[
pool_out
],
size
=
hid_dim2
,
act
=
None
,
param_attr
=
fc_param_attrs_1
)
# sigmoid layer
fc_2
=
fluid
.
layers
.
fc
(
input
=
[
fc_1
],
size
=
class_dim
,
act
=
None
,
param_attr
=
fc_param_attrs_2
)
prediction
=
fluid
.
layers
.
sigmoid
(
fc_2
)
if
is_infer
:
return
prediction
cost
=
fluid
.
layers
.
sigmoid_cross_entropy_with_logits
(
x
=
fc_2
,
label
=
label
)
avg_cost
=
fluid
.
layers
.
mean
(
x
=
cost
)
pred_label
=
fluid
.
layers
.
ceil
(
fluid
.
layers
.
thresholded_relu
(
prediction
,
threshold
))
return
[
avg_cost
,
prediction
,
pred_label
,
label
]
PaddleNLP/dialogue_domain_classification/run.sh
0 → 100755
浏览文件 @
d7cf2a53
export
PATH
=
"/home/guohongjie/tmp/paddle/paddle_release_home/python/bin/:
$PATH
"
# CPU setting
:
<<
EOF
USE_CUDA=false
CPU_NUM=3 # cpu_num works only when USE_CUDA=false
# path to your python
export PATH="/home/work/guohongjie/cpu_paddle/python2/bin:
$PATH
"
EOF
# GPU_settting
:
<<
EOF
# cuda path
LD_LIBRARY_PATH=/home/work/cuda/cudnn/cudnn_v7/cuda/lib64:/usr/local/cuda/lib64:/usr/local/cuda/lib:/usr/local/cuda/lib64:/usr/local/cuda/lib:
$LD_LIBRARY_PATH
export LD_LIBRARY_PATH="/home/work/guohongjie/cuda/cudnn/cudnn_v7/cuda/lib64:
$LD_LIBRARY_PATH
"
export LD_LIBRARY_PATH="/home/work/guohongjie/cuda/cuda-9.0/lib64:
$LD_LIBRARY_PATH
"
USE_CUDA=true
CPU_NUM=3 # cpu_num works only when USE_CUDA=false
export FLAGS_fraction_of_gpu_memory_to_use=0.02
export FLAGS_eager_delete_tensor_gb=0.0
export FLAGS_fast_eager_deletion_mode=1
export CUDA_VISIBLE_DEVICES=0 # which GPU to use
# path to your python
export PATH="/home/work/guohongjie/gpu_paddle/python2/bin:
$PATH
"
EOF
echo
"the python your use is
`
which python
`
"
MODEL_PATH
=
None
# not loading any pretrained model
#MODEL_PATH=./model/ # the default pretrained model
INPUT_DIR
=
./data/input/
OUTPUT_DIR
=
./data/output/
TRAIN_CONF
=
./data/input/model.conf
BUILD_DICT
=
false
# if you use your new dataset, set it true to build domain and char dict
BATCH_SIZE
=
64
train
()
{
python
-u
run_classifier.py
\
--use_cuda
${
USE_CUDA
}
\
--cpu_num
${
CPU_NUM
}
\
--do_train
true
\
--do_eval
false
\
--do_test
false
\
--build_dict
${
BUILD_DICT
}
\
--data_dir
${
INPUT_DIR
}
\
--save_dir
${
OUTPUT_DIR
}
\
--config_path
${
TRAIN_CONF
}
\
--batch_size
${
BATCH_SIZE
}
\
--init_checkpoint
${
MODEL_PATH
}
}
evaluate
()
{
python
-u
run_classifier.py
\
--use_cuda
${
USE_CUDA
}
\
--cpu_num
${
CPU_NUM
}
\
--do_train
true
\
--do_eval
true
\
--do_test
false
\
--build_dict
${
BUILD_DICT
}
\
--data_dir
${
INPUT_DIR
}
\
--save_dir
${
OUTPUT_DIR
}
\
--config_path
${
TRAIN_CONF
}
\
--batch_size
${
BATCH_SIZE
}
\
--init_checkpoint
${
MODEL_PATH
}
}
infer
()
{
python
-u
run_classifier.py
\
--use_cuda
${
USE_CUDA
}
\
--cpu_num
${
CPU_NUM
}
\
--do_train
false
\
--do_eval
false
\
--do_test
true
\
--build_dict
${
BUILD_DICT
}
\
--data_dir
${
INPUT_DIR
}
\
--save_dir
${
OUTPUT_DIR
}
\
--config_path
${
TRAIN_CONF
}
\
--batch_size
${
BATCH_SIZE
}
\
--init_checkpoint
${
MODEL_PATH
}
}
main
()
{
local
cmd
=
${
1
:-
help
}
case
"
${
cmd
}
"
in
train
)
train
"
$@
"
;
;;
eval
)
evaluate
"
$@
"
;
;;
test
)
infer
"
$@
"
;
;;
help
)
echo
"Usage:
${
BASH_SOURCE
}
{train|eval|test}"
;
return
0
;
;;
*
)
echo
"Unsupport commend [
${
cmd
}
]"
;
echo
"Usage:
${
BASH_SOURCE
}
{train|eval|test}"
;
return
1
;
;;
esac
}
main
"
$@
"
PaddleNLP/dialogue_domain_classification/run_classifier.py
0 → 100755
浏览文件 @
d7cf2a53
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
os
import
time
import
argparse
import
numpy
as
np
import
multiprocessing
import
sys
# sys.path.append("../models/classification/")
from
nets
import
textcnn_net_multi_label
import
paddle
import
paddle.fluid
as
fluid
from
utils
import
ArgumentGroup
,
print_arguments
,
DataProcesser
,
DataReader
,
ConfigReader
from
utils
import
init_checkpoint
,
check_version
,
logger
import
random
import
codecs
import
logging
import
math
np
.
random
.
seed
(
0
)
random
.
seed
(
0
)
parser
=
argparse
.
ArgumentParser
(
__doc__
)
DEV_COUNT
=
1
model_g
=
ArgumentGroup
(
parser
,
"model"
,
"model configuration and paths."
)
model_g
.
add_arg
(
"init_checkpoint"
,
str
,
None
,
"Init checkpoint to resume training from."
)
model_g
.
add_arg
(
"checkpoints"
,
str
,
"./checkpoints"
,
"Path to save checkpoints."
)
model_g
.
add_arg
(
"config_path"
,
str
,
"./data/input/model.conf"
,
"Model conf."
)
model_g
.
add_arg
(
"build_dict"
,
bool
,
False
,
"Build dict."
)
train_g
=
ArgumentGroup
(
parser
,
"training"
,
"training options."
)
train_g
.
add_arg
(
"cpu_num"
,
int
,
3
,
"Number of Threads."
)
train_g
.
add_arg
(
"epoch"
,
int
,
100
,
"Number of epoches for training."
)
train_g
.
add_arg
(
"learning_rate"
,
float
,
0.1
,
"Learning rate used to train with warmup."
)
train_g
.
add_arg
(
"save_steps"
,
int
,
1000
,
"The steps interval to save checkpoints."
)
train_g
.
add_arg
(
"validation_steps"
,
int
,
100
,
"The steps interval to evaluate model performance."
)
train_g
.
add_arg
(
"random_seed"
,
int
,
7
,
"random seed"
)
train_g
.
add_arg
(
"threshold"
,
float
,
0.1
,
"When the confidence exceeds the threshold, the corresponding label is given."
)
log_g
=
ArgumentGroup
(
parser
,
"logging"
,
"logging related."
)
log_g
.
add_arg
(
"skip_steps"
,
int
,
10
,
"The steps interval to print loss."
)
data_g
=
ArgumentGroup
(
parser
,
"data"
,
"Data paths, vocab paths and data processing options"
)
data_g
.
add_arg
(
"data_dir"
,
str
,
"./data/input/"
,
"Path to training data."
)
data_g
.
add_arg
(
"save_dir"
,
str
,
"./data/output/"
,
"Path to save."
)
data_g
.
add_arg
(
"max_seq_len"
,
int
,
50
,
"Tokens' number of the longest seqence allowed."
)
data_g
.
add_arg
(
"batch_size"
,
int
,
64
,
"The total number of examples in one batch for training."
)
run_type_g
=
ArgumentGroup
(
parser
,
"run_type"
,
"running type options."
)
run_type_g
.
add_arg
(
"use_cuda"
,
bool
,
False
,
"If set, use GPU for training."
)
# run_type_g.add_arg("use_fast_executor", bool, False, "If set, use fast parallel executor (in experiment).")
run_type_g
.
add_arg
(
"do_train"
,
bool
,
True
,
"Whether to perform evaluation on test data set."
)
run_type_g
.
add_arg
(
"do_eval"
,
bool
,
True
,
"Whether to perform evaluation on test data set."
)
run_type_g
.
add_arg
(
"do_test"
,
bool
,
True
,
"Whether to perform evaluation on test data set."
)
args
=
parser
.
parse_args
()
def
get_score
(
pred_result
,
label
,
eval_phase
):
"""[get precision recall and f-score]
Arguments:
pred_result {[type]} -- [pred labels]
label {[type]} -- [origin labels]
"""
tp
=
0
total
=
0
true_cnt
=
0
pred_pos_num
=
0
pos_num
=
0
for
i
in
range
(
len
(
pred_result
)):
total
+=
1
pred_labels
=
[]
actual_labels
=
[]
for
j
in
range
(
1
,
len
(
pred_result
[
0
])):
# the 0 one is background
if
pred_result
[
i
][
j
]
==
1
:
pred_labels
.
append
(
j
)
if
label
[
i
][
j
]
==
1
:
actual_labels
.
append
(
j
)
if
len
(
pred_labels
)
>
0
:
pred_pos_num
+=
1
if
len
(
actual_labels
)
>
0
:
pos_num
+=
1
if
set
(
actual_labels
).
issubset
(
set
(
pred_labels
)):
tp
+=
1
true_cnt
+=
1
elif
len
(
pred_labels
)
==
0
and
len
(
actual_labels
)
==
0
:
true_cnt
+=
1
try
:
precision
=
tp
*
1.0
/
pred_pos_num
recall
=
tp
*
1.0
/
pos_num
f1
=
2
*
precision
*
recall
/
(
recall
+
precision
)
except
Exception
as
e
:
precision
=
0
recall
=
0
f1
=
0
acc
=
true_cnt
*
1.0
/
total
logger
.
info
(
"tp, pred_pos_num, pos_num, total"
)
logger
.
info
(
"%d, %d, %d, %d"
%
(
tp
,
pred_pos_num
,
pos_num
,
total
))
logger
.
info
(
"%s result is : precision is %f, recall is %f, f1_score is %f, acc is %f"
%
(
eval_phase
,
precision
,
\
recall
,
f1
,
acc
))
def
train
(
args
,
train_exe
,
compiled_prog
,
build_res
,
place
):
"""[train the net]
Arguments:
args {[type]} -- [description]
train_exe {[type]} -- [description]
compiled_prog{[type]} -- [description]
build_res {[type]} -- [description]
place {[type]} -- [description]
"""
global
DEV_COUNT
cost
=
build_res
[
"cost"
]
prediction
=
build_res
[
"prediction"
]
pred_label
=
build_res
[
"pred_label"
]
label
=
build_res
[
"label"
]
fetch_list
=
[
cost
.
name
,
prediction
.
name
,
pred_label
.
name
,
label
.
name
]
train_pyreader
=
build_res
[
"train_pyreader"
]
train_prog
=
build_res
[
"train_prog"
]
steps
=
0
time_begin
=
time
.
time
()
test_exe
=
train_exe
logger
.
info
(
"Begin training"
)
feed_data
=
[]
for
i
in
range
(
args
.
epoch
):
try
:
for
data
in
train_pyreader
():
feed_data
.
extend
(
data
)
if
len
(
feed_data
)
==
DEV_COUNT
:
avg_cost_np
,
avg_pred_np
,
pred_label
,
label
=
train_exe
.
run
(
feed
=
feed_data
,
program
=
compiled_prog
,
\
fetch_list
=
fetch_list
)
feed_data
=
[]
steps
+=
1
if
steps
%
int
(
args
.
skip_steps
)
==
0
:
time_end
=
time
.
time
()
used_time
=
time_end
-
time_begin
get_score
(
pred_label
,
label
,
eval_phase
=
"Train"
)
logger
.
info
(
'loss is {}'
.
format
(
avg_cost_np
))
logger
.
info
(
"epoch: %d, step: %d, speed: %f steps/s"
%
(
i
,
steps
,
args
.
skip_steps
/
used_time
))
time_begin
=
time
.
time
()
if
steps
%
args
.
save_steps
==
0
:
save_path
=
os
.
path
.
join
(
args
.
checkpoints
,
"step_"
+
str
(
steps
))
fluid
.
io
.
save_persistables
(
train_exe
,
save_path
,
train_prog
)
logger
.
info
(
"[save]step %d : save at %s"
%
(
steps
,
save_path
))
if
steps
%
args
.
validation_steps
==
0
:
if
args
.
do_eval
:
evaluate
(
args
,
test_exe
,
build_res
[
"eval_prog"
],
build_res
,
place
,
"eval"
)
if
args
.
do_test
:
evaluate
(
args
,
test_exe
,
build_res
[
"test_prog"
],
build_res
,
place
,
"test"
)
except
Exception
as
e
:
logger
.
exception
(
str
(
e
))
logger
.
error
(
"Train error : %s"
%
str
(
e
))
exit
(
1
)
save_path
=
os
.
path
.
join
(
args
.
checkpoints
,
"step_"
+
str
(
steps
))
fluid
.
io
.
save_persistables
(
train_exe
,
save_path
,
train_prog
)
logger
.
info
(
"[save]step %d : save at %s"
%
(
steps
,
save_path
))
def
evaluate
(
args
,
test_exe
,
test_prog
,
build_res
,
place
,
eval_phase
,
save_result
=
False
,
id2intent
=
None
):
"""[evaluate on dev/test dataset]
Arguments:
args {[type]} -- [description]
test_exe {[type]} -- [description]
test_prog {[type]} -- [description]
build_res {[type]} -- [description]
place {[type]} -- [description]
eval_phase {[type]} -- [description]
Keyword Arguments:
threshold {float} -- [description] (default: {0.5})
save_result {bool} -- [description] (default: {False})
id2intent {[type]} -- [description] (default: {None})
"""
threshold
=
args
.
threshold
cost
=
build_res
[
"cost"
]
prediction
=
build_res
[
"prediction"
]
pred_label
=
build_res
[
"pred_label"
]
label
=
build_res
[
"label"
]
fetch_list
=
[
cost
.
name
,
prediction
.
name
,
pred_label
.
name
,
label
.
name
]
total_cost
,
total_acc
,
pred_prob_list
,
pred_label_list
,
label_list
=
[],
[],
[],
[],
[]
if
eval_phase
==
"eval"
:
test_pyreader
=
build_res
[
"eval_pyreader"
]
elif
eval_phase
==
"test"
:
test_pyreader
=
build_res
[
"test_pyreader"
]
else
:
exit
(
1
)
logger
.
info
(
"-----------------------------------------------------------"
)
for
data
in
test_pyreader
():
avg_cost_np
,
avg_pred_np
,
pred_label
,
label
=
test_exe
.
run
(
program
=
test_prog
,
fetch_list
=
fetch_list
,
feed
=
data
,
\
return_numpy
=
True
)
total_cost
.
append
(
avg_cost_np
)
pred_prob_list
.
extend
(
avg_pred_np
)
pred_label_list
.
extend
(
pred_label
)
label_list
.
extend
(
label
)
if
save_result
:
logger
.
info
(
"save result at : %s"
%
args
.
save_dir
+
"/"
+
eval_phase
+
".rst"
)
save_dir
=
args
.
save_dir
if
not
os
.
path
.
exists
(
save_dir
):
logger
.
warning
(
"save dir not exists, and create it"
)
os
.
makedirs
(
save_dir
)
fin
=
codecs
.
open
(
os
.
path
.
join
(
args
.
data_dir
,
eval_phase
+
".txt"
),
"r"
,
encoding
=
"utf8"
)
fout
=
codecs
.
open
(
args
.
save_dir
+
"/"
+
eval_phase
+
".rst"
,
"w"
,
encoding
=
"utf8"
)
for
line
in
pred_prob_list
:
query
=
fin
.
readline
().
rsplit
(
"
\t
"
,
1
)[
0
]
res
=
[]
for
i
in
range
(
1
,
len
(
line
)):
if
line
[
i
]
>
threshold
:
#res.append(id2intent[i]+":"+str(line[i]))
res
.
append
(
id2intent
[
i
])
if
len
(
res
)
==
0
:
res
.
append
(
id2intent
[
0
])
fout
.
write
(
"%s
\t
%s
\n
"
%
(
query
,
"
\2
"
.
join
(
sorted
(
res
))))
fout
.
close
()
fin
.
close
()
logger
.
info
(
"[%s] result: "
%
eval_phase
)
get_score
(
pred_label_list
,
label_list
,
eval_phase
)
logger
.
info
(
'loss is {}'
.
format
(
sum
(
total_cost
)
*
1.0
/
len
(
total_cost
)))
logger
.
info
(
"-----------------------------------------------------------"
)
def
create_net
(
args
,
flow_data
,
class_dim
,
dict_dim
,
place
,
model_name
=
"textcnn_net"
,
is_infer
=
False
):
"""[create network and pyreader]
Arguments:
flow_data {[type]} -- [description]
class_dim {[type]} -- [description]
dict_dim {[type]} -- [description]
place {[type]} -- [description]
Keyword Arguments:
model_name {str} -- [description] (default: {"textcnn_net"})
is_infer {bool} -- [description] (default: {False})
Returns:
[type] -- [description]
"""
if
model_name
==
"textcnn_net"
:
model
=
textcnn_net_multi_label
else
:
return
char_list
=
fluid
.
data
(
name
=
"char"
,
shape
=
[
None
,
args
.
max_seq_len
,
1
],
dtype
=
"int64"
,
lod_level
=
0
)
label
=
fluid
.
data
(
name
=
"label"
,
shape
=
[
None
,
class_dim
],
dtype
=
"float32"
,
lod_level
=
0
)
# label data
reader
=
fluid
.
io
.
PyReader
(
feed_list
=
[
char_list
,
label
],
capacity
=
args
.
batch_size
*
10
,
iterable
=
True
,
\
return_list
=
False
)
output
=
model
(
char_list
,
label
,
dict_dim
,
emb_dim
=
flow_data
[
"model"
][
"emb_dim"
],
hid_dim
=
flow_data
[
"model"
][
"hid_dim"
],
hid_dim2
=
flow_data
[
"model"
][
"hid_dim2"
],
class_dim
=
class_dim
,
win_sizes
=
flow_data
[
"model"
][
"win_sizes"
],
is_infer
=
is_infer
,
threshold
=
args
.
threshold
,
max_seq_len
=
args
.
max_seq_len
)
if
is_infer
:
prediction
=
output
return
[
reader
,
prediction
]
else
:
avg_cost
,
prediction
,
pred_label
,
label
=
output
[
0
],
output
[
1
],
output
[
2
],
output
[
3
]
return
[
reader
,
avg_cost
,
prediction
,
pred_label
,
label
]
def
build_data_reader
(
args
,
char_dict
,
intent_dict
):
"""[decorate samples for pyreader]
Arguments:
args {[type]} -- [description]
char_dict {[type]} -- [description]
intent_dict {[type]} -- [description]
Returns:
[type] -- [description]
"""
reader_res
=
{}
if
args
.
do_train
:
train_processor
=
DataReader
(
char_dict
,
intent_dict
,
args
.
max_seq_len
)
train_data_generator
=
train_processor
.
prepare_data
(
data_path
=
args
.
data_dir
+
"train.txt"
,
batch_size
=
args
.
batch_size
,
mode
=
'train'
)
reader_res
[
"train_data_generator"
]
=
train_data_generator
num_train_examples
=
train_processor
.
_get_num_examples
()
logger
.
info
(
"Num train examples: %d"
%
num_train_examples
)
logger
.
info
(
"Num train steps: %d"
%
(
math
.
ceil
(
num_train_examples
*
1.0
/
args
.
batch_size
)
*
\
args
.
epoch
//
DEV_COUNT
))
if
math
.
ceil
(
num_train_examples
*
1.0
/
args
.
batch_size
)
//
DEV_COUNT
<=
0
:
logger
.
error
(
"Num of train steps is less than 0 or equals to 0, exit"
)
exit
(
1
)
if
args
.
do_eval
:
eval_processor
=
DataReader
(
char_dict
,
intent_dict
,
args
.
max_seq_len
)
eval_data_generator
=
eval_processor
.
prepare_data
(
data_path
=
args
.
data_dir
+
"eval.txt"
,
batch_size
=
args
.
batch_size
,
mode
=
'eval'
)
reader_res
[
"eval_data_generator"
]
=
eval_data_generator
num_eval_examples
=
eval_processor
.
_get_num_examples
()
logger
.
info
(
"Num eval examples: %d"
%
num_eval_examples
)
if
args
.
do_test
:
test_processor
=
DataReader
(
char_dict
,
intent_dict
,
args
.
max_seq_len
)
test_data_generator
=
test_processor
.
prepare_data
(
data_path
=
args
.
data_dir
+
"test.txt"
,
batch_size
=
args
.
batch_size
,
mode
=
'test'
)
reader_res
[
"test_data_generator"
]
=
test_data_generator
return
reader_res
def
build_graph
(
args
,
model_config
,
num_labels
,
dict_dim
,
place
,
reader_res
):
"""[build paddle graph]
Arguments:
args {[type]} -- [description]
model_config {[type]} -- [description]
num_labels {[type]} -- [description]
dict_dim {[type]} -- [description]
place {[type]} -- [description]
reader_res {[type]} -- [description]
Returns:
[type] -- [description]
"""
res
=
{}
cost
,
prediction
,
pred_label
,
label
=
None
,
None
,
None
,
None
train_prog
=
fluid
.
default_main_program
()
startup_prog
=
fluid
.
default_startup_program
()
eval_prog
=
train_prog
.
clone
(
for_test
=
True
)
test_prog
=
train_prog
.
clone
(
for_test
=
True
)
train_prog
.
random_seed
=
args
.
random_seed
startup_prog
.
random_seed
=
args
.
random_seed
if
args
.
do_train
:
with
fluid
.
program_guard
(
train_prog
,
startup_prog
):
with
fluid
.
unique_name
.
guard
():
train_pyreader
,
cost
,
prediction
,
pred_label
,
label
=
create_net
(
args
,
model_config
,
num_labels
,
\
dict_dim
,
place
,
model_name
=
"textcnn_net"
)
train_pyreader
.
decorate_sample_list_generator
(
reader_res
[
'train_data_generator'
],
places
=
place
)
res
[
"train_pyreader"
]
=
train_pyreader
sgd_optimizer
=
fluid
.
optimizer
.
SGD
(
learning_rate
=
fluid
.
layers
.
exponential_decay
(
learning_rate
=
args
.
learning_rate
,
decay_steps
=
1000
,
decay_rate
=
0.5
,
staircase
=
True
))
sgd_optimizer
.
minimize
(
cost
)
if
args
.
do_eval
:
with
fluid
.
program_guard
(
eval_prog
,
startup_prog
):
with
fluid
.
unique_name
.
guard
():
eval_pyreader
,
cost
,
prediction
,
pred_label
,
label
=
create_net
(
args
,
model_config
,
num_labels
,
\
dict_dim
,
place
,
model_name
=
"textcnn_net"
)
eval_pyreader
.
decorate_sample_list_generator
(
reader_res
[
'eval_data_generator'
],
places
=
place
)
res
[
"eval_pyreader"
]
=
eval_pyreader
if
args
.
do_test
:
with
fluid
.
program_guard
(
test_prog
,
startup_prog
):
with
fluid
.
unique_name
.
guard
():
test_pyreader
,
cost
,
prediction
,
pred_label
,
label
=
create_net
(
args
,
model_config
,
num_labels
,
\
dict_dim
,
place
,
model_name
=
"textcnn_net"
)
test_pyreader
.
decorate_sample_list_generator
(
reader_res
[
'test_data_generator'
],
places
=
place
)
res
[
"test_pyreader"
]
=
test_pyreader
res
[
"cost"
]
=
cost
res
[
"prediction"
]
=
prediction
res
[
"label"
]
=
label
res
[
"pred_label"
]
=
pred_label
res
[
"train_prog"
]
=
train_prog
res
[
"eval_prog"
]
=
eval_prog
res
[
"test_prog"
]
=
test_prog
return
res
def
main
(
args
):
"""
Main Function
"""
global
DEV_COUNT
startup_prog
=
fluid
.
default_startup_program
()
random
.
seed
(
args
.
random_seed
)
model_config
=
ConfigReader
.
read_conf
(
args
.
config_path
)
if
args
.
use_cuda
:
place
=
fluid
.
CUDAPlace
(
int
(
os
.
getenv
(
'FLAGS_selected_gpus'
,
'0'
)))
DEV_COUNT
=
fluid
.
core
.
get_cuda_device_count
()
else
:
place
=
fluid
.
CPUPlace
()
os
.
environ
[
'CPU_NUM'
]
=
str
(
args
.
cpu_num
)
DEV_COUNT
=
args
.
cpu_num
logger
.
info
(
"Dev Num is %s"
%
str
(
DEV_COUNT
))
exe
=
fluid
.
Executor
(
place
)
if
args
.
do_train
and
args
.
build_dict
:
DataProcesser
.
build_dict
(
args
.
data_dir
+
"train.txt"
,
args
.
data_dir
)
# read dict
char_dict
=
DataProcesser
.
read_dict
(
args
.
data_dir
+
"char.dict"
)
dict_dim
=
len
(
char_dict
)
intent_dict
=
DataProcesser
.
read_dict
(
args
.
data_dir
+
"domain.dict"
)
id2intent
=
{}
for
key
,
value
in
intent_dict
.
items
():
id2intent
[
int
(
value
)]
=
key
num_labels
=
len
(
intent_dict
)
# build model
reader_res
=
build_data_reader
(
args
,
char_dict
,
intent_dict
)
build_res
=
build_graph
(
args
,
model_config
,
num_labels
,
dict_dim
,
place
,
reader_res
)
if
not
(
args
.
do_train
or
args
.
do_eval
or
args
.
do_test
):
raise
ValueError
(
"For args `do_train`, `do_eval` and `do_test`, at "
"least one of them must be True."
)
exe
.
run
(
startup_prog
)
if
args
.
init_checkpoint
and
args
.
init_checkpoint
!=
"None"
:
try
:
init_checkpoint
(
exe
,
args
.
init_checkpoint
,
main_program
=
startup_prog
)
logger
.
info
(
"Load model from %s"
%
args
.
init_checkpoint
)
except
Exception
as
e
:
logger
.
exception
(
str
(
e
))
logger
.
error
(
"Faild load model from %s [%s]"
%
(
args
.
init_checkpoint
,
str
(
e
)))
if
args
.
do_train
:
build_strategy
=
fluid
.
compiler
.
BuildStrategy
()
compiled_prog
=
fluid
.
compiler
.
CompiledProgram
(
build_res
[
"train_prog"
]).
with_data_parallel
(
\
loss_name
=
build_res
[
"cost"
].
name
,
build_strategy
=
build_strategy
)
build_res
[
"compiled_prog"
]
=
compiled_prog
train
(
args
,
exe
,
compiled_prog
,
build_res
,
place
)
if
args
.
do_eval
:
evaluate
(
args
,
exe
,
build_res
[
"eval_prog"
],
build_res
,
place
,
"eval"
,
\
save_result
=
True
,
id2intent
=
id2intent
)
if
args
.
do_test
:
evaluate
(
args
,
exe
,
build_res
[
"test_prog"
],
build_res
,
place
,
"test"
,
\
save_result
=
True
,
id2intent
=
id2intent
)
if
__name__
==
"__main__"
:
logger
.
info
(
"the paddle version is %s"
%
paddle
.
__version__
)
check_version
(
'1.6.0'
)
print_arguments
(
args
)
main
(
args
)
PaddleNLP/dialogue_domain_classification/utils.py
0 → 100755
浏览文件 @
d7cf2a53
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
from
__future__
import
unicode_literals
import
sys
import
os
import
random
import
paddle
import
logging
import
paddle.fluid
as
fluid
import
numpy
as
np
import
collections
import
six
import
codecs
try
:
import
configparser
as
cp
except
ImportError
:
import
ConfigParser
as
cp
random_seed
=
7
logger
=
logging
.
getLogger
()
format
=
"%(asctime)s - %(name)s - %(levelname)s -%(filename)s-%(lineno)4d -%(message)s"
# format = "%(levelname)8s: %(asctime)s: %(filename)s:%(lineno)4d %(message)s"
logging
.
basicConfig
(
format
=
format
)
logger
.
setLevel
(
logging
.
INFO
)
logger
=
logging
.
getLogger
(
'Paddle-DDC'
)
def
str2bool
(
v
):
"""[ because argparse does not support to parse "true, False" as python
boolean directly]
Arguments:
v {[type]} -- [description]
Returns:
[type] -- [description]
"""
return
v
.
lower
()
in
(
"true"
,
"t"
,
"1"
)
def
to_lodtensor
(
data
,
place
):
"""
convert ot LODtensor
"""
seq_lens
=
[
len
(
seq
)
for
seq
in
data
]
cur_len
=
0
lod
=
[
cur_len
]
for
l
in
seq_lens
:
cur_len
+=
l
lod
.
append
(
cur_len
)
flattened_data
=
np
.
concatenate
(
data
,
axis
=
0
).
astype
(
"int64"
)
flattened_data
=
flattened_data
.
reshape
([
len
(
flattened_data
),
1
])
res
=
fluid
.
LoDTensor
()
res
.
set
(
flattened_data
,
place
)
res
.
set_lod
([
lod
])
return
res
class
ArgumentGroup
(
object
):
"""[ArgumentGroup]
Arguments:
object {[type]} -- [description]
"""
def
__init__
(
self
,
parser
,
title
,
des
):
self
.
_group
=
parser
.
add_argument_group
(
title
=
title
,
description
=
des
)
def
add_arg
(
self
,
name
,
type
,
default
,
help
,
**
kwargs
):
"""[add_arg]
Arguments:
name {[type]} -- [description]
type {[type]} -- [description]
default {[type]} -- [description]
help {[type]} -- [description]
"""
type
=
str2bool
if
type
==
bool
else
type
self
.
_group
.
add_argument
(
"--"
+
name
,
default
=
default
,
type
=
type
,
help
=
help
+
' Default: %(default)s.'
,
**
kwargs
)
class
DataReader
(
object
):
"""[get data generator for dataset]
Arguments:
object {[type]} -- [description]
Returns:
[type] -- [description]
"""
def
__init__
(
self
,
char_vocab
,
intent_dict
,
max_len
):
self
.
_char_vocab
=
char_vocab
self
.
_intent_dict
=
intent_dict
self
.
_oov_id
=
0
self
.
intent_size
=
len
(
intent_dict
)
self
.
all_data
=
[]
self
.
max_len
=
max_len
self
.
padding_id
=
0
def
_get_num_examples
(
self
):
return
len
(
self
.
all_data
)
def
prepare_data
(
self
,
data_path
,
batch_size
,
mode
):
"""
prepare data
"""
# print word_dict_path
# assert os.path.exists(
# word_dict_path), "The given word dictionary dose not exist."
assert
os
.
path
.
exists
(
data_path
),
"The given data file does not exist."
if
mode
==
"train"
:
train_reader
=
fluid
.
io
.
batch
(
paddle
.
reader
.
shuffle
(
self
.
data_reader
(
data_path
,
self
.
max_len
,
shuffle
=
True
),
buf_size
=
batch_size
*
100
),
batch_size
)
# train_reader = fluid.io.batch(self.data_reader(data_path), batch_size)
return
train_reader
else
:
test_reader
=
fluid
.
io
.
batch
(
self
.
data_reader
(
data_path
,
self
.
max_len
),
batch_size
)
return
test_reader
def
data_reader
(
self
,
file_path
,
max_len
,
shuffle
=
False
):
"""
Convert query into id list
use fixed voc
"""
for
line
in
codecs
.
open
(
file_path
,
"r"
,
encoding
=
"utf8"
):
line
=
line
.
strip
()
if
isinstance
(
line
,
six
.
binary_type
):
line
=
line
.
decode
(
"utf8"
,
errors
=
"ignore"
)
query
,
intent
=
line
.
split
(
"
\t
"
)
char_id_list
=
list
(
map
(
lambda
x
:
0
if
x
not
in
self
.
_char_vocab
else
int
(
self
.
_char_vocab
[
x
]),
\
list
(
query
)))
if
len
(
char_id_list
)
<
max_len
:
char_id_list
.
extend
([
self
.
padding_id
]
*
(
max_len
-
len
(
char_id_list
)))
char_id_list
=
char_id_list
[:
max_len
]
intent_id_list
=
[
self
.
padding_id
]
*
self
.
intent_size
for
item
in
intent
.
split
(
'
\2
'
):
intent_id_list
[
int
(
self
.
_intent_dict
[
item
])]
=
1
self
.
all_data
.
append
([
char_id_list
,
intent_id_list
])
if
shuffle
:
random
.
seed
(
random_seed
)
random
.
shuffle
(
self
.
all_data
)
def
reader
():
"""
reader
"""
for
char_id_list
,
intent_id_list
in
self
.
all_data
:
# print char_id_list, intent_id
yield
char_id_list
,
intent_id_list
return
reader
class
DataProcesser
(
object
):
"""[file process methods]
Arguments:
object {[type]} -- [description]
Returns:
[type] -- [description]
"""
@
staticmethod
def
read_dict
(
filename
):
"""
read_dict: key
\2
value
"""
res_dict
=
{}
for
line
in
codecs
.
open
(
filename
,
encoding
=
"utf8"
):
try
:
if
isinstance
(
line
,
six
.
binary_type
):
line
=
line
.
strip
().
decode
(
"utf8"
)
line
=
line
.
strip
()
key
,
value
=
line
.
strip
().
split
(
"
\2
"
)
res_dict
[
key
]
=
value
except
Exception
as
err
:
logger
.
error
(
str
(
err
))
logger
.
error
(
"read dict[%s] failed"
%
filename
)
return
res_dict
@
staticmethod
def
build_dict
(
filename
,
save_dir
,
min_num_char
=
2
,
min_num_intent
=
2
):
"""[build_dict from file]
Arguments:
filename {[type]} -- [description]
save_dir {[type]} -- [description]
Keyword Arguments:
min_num_char {int} -- [description] (default: {2})
min_num_intent {int} -- [description] (default: {2})
"""
char_dict
=
{}
intent_dict
=
{}
# readfile
for
line
in
codecs
.
open
(
filename
):
line
=
line
.
strip
()
if
isinstance
(
line
,
six
.
binary_type
):
line
=
line
.
strip
().
decode
(
"utf8"
,
errors
=
"ignore"
)
query
,
intents
=
line
.
split
(
"
\t
"
)
# read query
for
char_item
in
list
(
query
):
if
char_item
not
in
char_dict
:
char_dict
[
char_item
]
=
0
char_dict
[
char_item
]
+=
1
# read intents
for
intent
in
intents
.
split
(
'
\002
'
):
if
intent
not
in
intent_dict
:
intent_dict
[
intent
]
=
0
intent_dict
[
intent
]
+=
1
# save char dict
with
codecs
.
open
(
"%s/char.dict"
%
save_dir
,
"w"
,
encoding
=
"utf8"
)
as
f_out
:
f_out
.
write
(
"PAD
\002
0
\n
"
)
f_out
.
write
(
"OOV
\002
1
\n
"
)
char_id
=
2
for
key
,
value
in
char_dict
.
items
():
if
value
>=
min_num_char
:
if
isinstance
(
key
,
six
.
binary_type
):
key
=
key
.
encode
(
"utf8"
)
f_out
.
write
(
"%s
\002
%d
\n
"
%
(
key
,
char_id
))
char_id
+=
1
# save intent dict
with
codecs
.
open
(
"%s/domain.dict"
%
save_dir
,
"w"
,
encoding
=
"utf8"
)
as
f_out
:
f_out
.
write
(
"SYS_OTHER
\002
0
\n
"
)
intent_id
=
1
for
key
,
value
in
intent_dict
.
items
():
if
value
>=
min_num_intent
and
key
!=
u
'SYS_OTHER'
:
if
isinstance
(
key
,
six
.
binary_type
):
key
=
key
.
encode
(
"utf8"
)
f_out
.
write
(
"%s
\002
%d
\n
"
%
(
key
,
intent_id
))
intent_id
+=
1
class
ConfigReader
(
object
):
"""[read model config file]
Arguments:
object {[type]} -- [description]
Returns:
[type] -- [description]
"""
@
staticmethod
def
read_conf
(
conf_file
):
"""[read_conf]
Arguments:
conf_file {[type]} -- [description]
Returns:
[type] -- [description]
"""
flow_data
=
collections
.
defaultdict
(
lambda
:
{})
class2key
=
set
([
"model"
])
param_conf
=
cp
.
ConfigParser
()
param_conf
.
read
(
conf_file
)
for
section
in
param_conf
.
sections
():
if
section
not
in
class2key
:
continue
for
option
in
param_conf
.
items
(
section
):
flow_data
[
section
][
option
[
0
]]
=
eval
(
option
[
1
])
return
flow_data
def
init_pretraining_params
(
exe
,
pretraining_params_path
,
main_program
,
use_fp16
=
False
):
"""load params of pretrained model, NOT including moment, learning_rate"""
assert
os
.
path
.
exists
(
pretraining_params_path
),
"[%s] cann't be found."
%
pretraining_params_path
def
_existed_params
(
var
):
if
not
isinstance
(
var
,
fluid
.
framework
.
Parameter
):
return
False
return
os
.
path
.
exists
(
os
.
path
.
join
(
pretraining_params_path
,
var
.
name
))
fluid
.
io
.
load_vars
(
exe
,
pretraining_params_path
,
main_program
=
main_program
,
predicate
=
_existed_params
)
print
(
"Load pretraining parameters from {}."
.
format
(
pretraining_params_path
))
def
init_checkpoint
(
exe
,
init_checkpoint_path
,
main_program
):
"""
Init CheckPoint
"""
assert
os
.
path
.
exists
(
init_checkpoint_path
),
"[%s] cann't be found."
%
init_checkpoint_path
def
existed_persitables
(
var
):
"""
If existed presitabels
"""
if
not
fluid
.
io
.
is_persistable
(
var
):
return
False
return
os
.
path
.
exists
(
os
.
path
.
join
(
init_checkpoint_path
,
var
.
name
))
fluid
.
io
.
load_vars
(
exe
,
init_checkpoint_path
,
main_program
=
main_program
,
predicate
=
existed_persitables
)
print
(
"Load model from {}"
.
format
(
init_checkpoint_path
))
def
print_arguments
(
args
):
"""
Print Arguments
"""
print
(
'----------- Configuration Arguments -----------'
)
for
arg
,
value
in
sorted
(
six
.
iteritems
(
vars
(
args
))):
print
(
'%s: %s'
%
(
arg
,
value
))
print
(
'------------------------------------------------'
)
def
check_version
(
version
=
'1.6.0'
):
"""
Log error and exit when the installed version of paddlepaddle is
not satisfied.
"""
err
=
"PaddlePaddle version 1.6 or higher is required, "
\
"or a suitable develop version is satisfied as well.
\n
"
\
"Please make sure the version is good with your code."
\
try
:
fluid
.
require_version
(
version
)
except
Exception
as
e
:
logger
.
error
(
err
)
sys
.
exit
(
1
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}