Merge branch 'develop' into update_ctr
Showing
fluid/DeepASR/.gitignore
0 → 100644
fluid/DeepASR/decoder/.gitignore
0 → 100644
{kind=link}

20.1 KB
{kind=link}

20.5 KB
{kind=link}
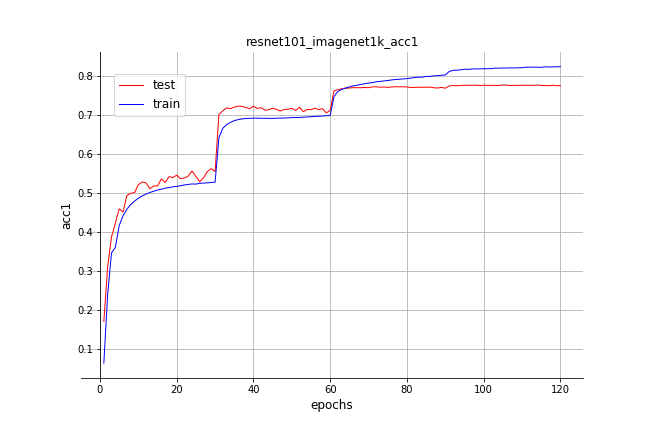
21.1 KB
{kind=link}
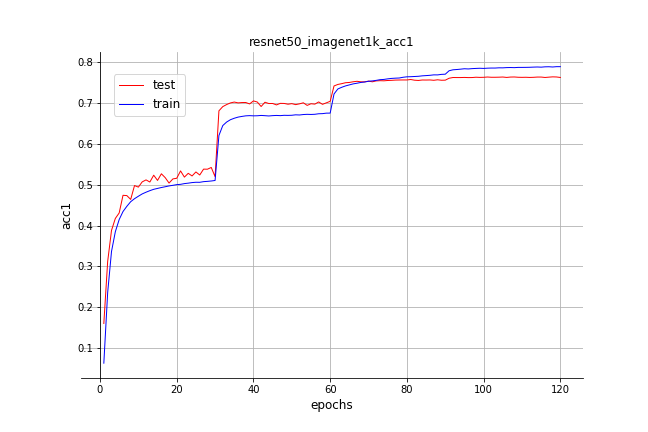
21.4 KB
{kind=link}
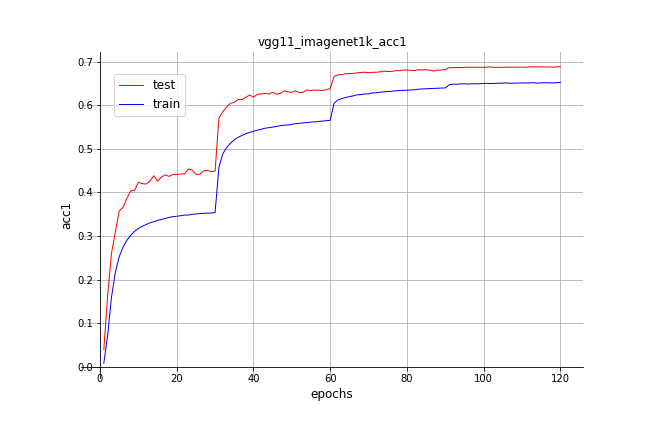
20.9 KB
fluid/PaddleRec/tagspace/net.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/PaddleRec/word2vec/infer.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/PaddleRec/word2vec/train.py
0 → 100644
此差异已折叠。
fluid/__init__.py
0 → 100644