Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
c50d1f18
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
c50d1f18
编写于
4月 16, 2019
作者:
G
gongweibao
提交者:
GitHub
4月 16, 2019
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add DGC support (#2031)
上级
cb764459
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
73 addition
and
6 deletion
+73
-6
PaddleCV/image_classification/dist_train/README.md
PaddleCV/image_classification/dist_train/README.md
+21
-0
PaddleCV/image_classification/dist_train/dist_train.py
PaddleCV/image_classification/dist_train/dist_train.py
+21
-2
PaddleCV/image_classification/dist_train/dist_utils.py
PaddleCV/image_classification/dist_train/dist_utils.py
+3
-2
PaddleCV/image_classification/dist_train/run_nccl2_mode.sh
PaddleCV/image_classification/dist_train/run_nccl2_mode.sh
+28
-2
PaddleCV/image_classification/images/resnet_dgc.png
PaddleCV/image_classification/images/resnet_dgc.png
+0
-0
未找到文件。
PaddleCV/image_classification/dist_train/README.md
浏览文件 @
c50d1f18
...
@@ -108,3 +108,24 @@ The second figure shows speed-ups when using multiple GPUs according to the abov
...
@@ -108,3 +108,24 @@ The second figure shows speed-ups when using multiple GPUs according to the abov
Speed-ups of Multiple-GPU Training of Resnet50 on Imagenet
Speed-ups of Multiple-GPU Training of Resnet50 on Imagenet
</p>
</p>
## Deep Gradient Compression([arXiv:1712.01887](https://arxiv.org/abs/1712.01887)) for resnet
#### Environment
-
GPU: NVIDIA® Tesla® V100
-
Machine number
* Card number: 4 *
4
-
System: Centos 6u3
-
Cuda/Cudnn: 9.0/7.1
-
Dataset: ImageNet
-
Date: 2017.04
-
PaddleVersion: 1.4
-
Batch size: 32
#### Performance
<p
align=
"center"
>
<img
src=
"../images/resnet_dgc.png"
width=
528
>
<br
/>
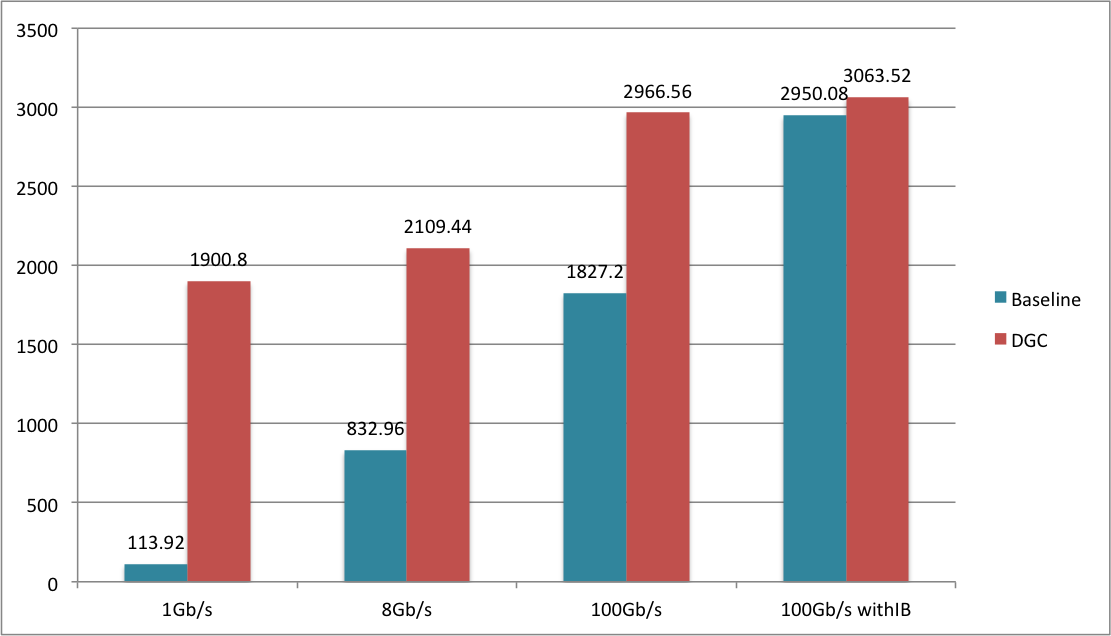
Performance using DGC for resnet-fp32 under different bandwidth
</p>
PaddleCV/image_classification/dist_train/dist_train.py
浏览文件 @
c50d1f18
...
@@ -68,6 +68,9 @@ def parse_args():
...
@@ -68,6 +68,9 @@ def parse_args():
add_arg
(
'reduce_strategy'
,
str
,
"allreduce"
,
"Choose from reduce or allreduce."
)
add_arg
(
'reduce_strategy'
,
str
,
"allreduce"
,
"Choose from reduce or allreduce."
)
add_arg
(
'skip_unbalanced_data'
,
bool
,
False
,
"Skip data not if data not balanced on nodes."
)
add_arg
(
'skip_unbalanced_data'
,
bool
,
False
,
"Skip data not if data not balanced on nodes."
)
add_arg
(
'enable_sequential_execution'
,
bool
,
False
,
"Skip data not if data not balanced on nodes."
)
add_arg
(
'enable_sequential_execution'
,
bool
,
False
,
"Skip data not if data not balanced on nodes."
)
#for dgc
add_arg
(
'enable_dgc'
,
bool
,
False
,
"Skip data not if data not balanced on nodes."
)
add_arg
(
'rampup_begin_step'
,
int
,
5008
,
"Skip data not if data not balanced on nodes."
)
# yapf: enable
# yapf: enable
args
=
parser
.
parse_args
()
args
=
parser
.
parse_args
()
return
args
return
args
...
@@ -157,6 +160,17 @@ def build_program(is_train, main_prog, startup_prog, args):
...
@@ -157,6 +160,17 @@ def build_program(is_train, main_prog, startup_prog, args):
boundaries
=
bd
,
values
=
lr
),
boundaries
=
bd
,
values
=
lr
),
warmup_steps
,
start_lr
,
end_lr
),
warmup_steps
,
start_lr
,
end_lr
),
momentum
=
0.9
)
momentum
=
0.9
)
if
args
.
enable_dgc
:
optimizer
=
fluid
.
optimizer
.
DGCMomentumOptimizer
(
learning_rate
=
utils
.
learning_rate
.
lr_warmup
(
fluid
.
layers
.
piecewise_decay
(
boundaries
=
bd
,
values
=
lr
),
warmup_steps
,
start_lr
,
end_lr
),
momentum
=
0.9
,
sparsity
=
[
0.999
,
0.999
],
rampup_begin_step
=
args
.
rampup_begin_step
)
if
args
.
fp16
:
if
args
.
fp16
:
params_grads
=
optimizer
.
backward
(
avg_cost
)
params_grads
=
optimizer
.
backward
(
avg_cost
)
master_params_grads
=
utils
.
create_master_params_grads
(
master_params_grads
=
utils
.
create_master_params_grads
(
...
@@ -224,7 +238,7 @@ def train_parallel(args):
...
@@ -224,7 +238,7 @@ def train_parallel(args):
if
args
.
update_method
==
"pserver"
:
if
args
.
update_method
==
"pserver"
:
train_prog
,
startup_prog
=
pserver_prepare
(
args
,
train_prog
,
startup_prog
)
train_prog
,
startup_prog
=
pserver_prepare
(
args
,
train_prog
,
startup_prog
)
elif
args
.
update_method
==
"nccl2"
:
elif
args
.
update_method
==
"nccl2"
:
nccl2_prepare
(
args
,
startup_prog
)
nccl2_prepare
(
args
,
startup_prog
,
main_prog
=
train_prog
)
if
args
.
dist_env
[
"training_role"
]
==
"PSERVER"
:
if
args
.
dist_env
[
"training_role"
]
==
"PSERVER"
:
run_pserver
(
train_prog
,
startup_prog
)
run_pserver
(
train_prog
,
startup_prog
)
...
@@ -247,11 +261,16 @@ def train_parallel(args):
...
@@ -247,11 +261,16 @@ def train_parallel(args):
strategy
=
fluid
.
ExecutionStrategy
()
strategy
=
fluid
.
ExecutionStrategy
()
strategy
.
num_threads
=
args
.
num_threads
strategy
.
num_threads
=
args
.
num_threads
# num_iteration_per_drop_scope indicates how
# many iterations to clean up the temp variables which
# is generated during execution. It may make the execution faster,
# because the temp variable's shape maybe the same between two iterations
strategy
.
num_iteration_per_drop_scope
=
30
build_strategy
=
fluid
.
BuildStrategy
()
build_strategy
=
fluid
.
BuildStrategy
()
build_strategy
.
enable_inplace
=
False
build_strategy
.
enable_inplace
=
False
build_strategy
.
memory_optimize
=
False
build_strategy
.
memory_optimize
=
False
build_strategy
.
enable_sequential_execution
=
bool
(
args
.
enable_sequential_execution
)
build_strategy
.
enable_sequential_execution
=
bool
(
args
.
enable_sequential_execution
)
if
args
.
reduce_strategy
==
"reduce"
:
if
args
.
reduce_strategy
==
"reduce"
:
build_strategy
.
reduce_strategy
=
fluid
.
BuildStrategy
(
build_strategy
.
reduce_strategy
=
fluid
.
BuildStrategy
(
...
...
PaddleCV/image_classification/dist_train/dist_utils.py
浏览文件 @
c50d1f18
...
@@ -2,7 +2,7 @@ import os
...
@@ -2,7 +2,7 @@ import os
import
paddle.fluid
as
fluid
import
paddle.fluid
as
fluid
def
nccl2_prepare
(
args
,
startup_prog
):
def
nccl2_prepare
(
args
,
startup_prog
,
main_prog
):
config
=
fluid
.
DistributeTranspilerConfig
()
config
=
fluid
.
DistributeTranspilerConfig
()
config
.
mode
=
"nccl2"
config
.
mode
=
"nccl2"
t
=
fluid
.
DistributeTranspiler
(
config
=
config
)
t
=
fluid
.
DistributeTranspiler
(
config
=
config
)
...
@@ -12,7 +12,8 @@ def nccl2_prepare(args, startup_prog):
...
@@ -12,7 +12,8 @@ def nccl2_prepare(args, startup_prog):
t
.
transpile
(
envs
[
"trainer_id"
],
t
.
transpile
(
envs
[
"trainer_id"
],
trainers
=
','
.
join
(
envs
[
"trainer_endpoints"
]),
trainers
=
','
.
join
(
envs
[
"trainer_endpoints"
]),
current_endpoint
=
envs
[
"current_endpoint"
],
current_endpoint
=
envs
[
"current_endpoint"
],
startup_program
=
startup_prog
)
startup_program
=
startup_prog
,
program
=
main_prog
)
def
pserver_prepare
(
args
,
train_prog
,
startup_prog
):
def
pserver_prepare
(
args
,
train_prog
,
startup_prog
):
...
...
PaddleCV/image_classification/dist_train/run_nccl2_mode.sh
浏览文件 @
c50d1f18
#!/bin/bash
#!/bin/bash
set
-e
enable_dgc
=
False
while
true
;
do
case
"
$1
"
in
-enable_dgc
)
enable_dgc
=
"
$2
"
;
shift
2
;;
*
)
if
[[
${#
1
}
>
0
]]
;
then
echo
"not supported arugments
${
1
}
"
;
exit
1
;
else
break
fi
;;
esac
done
case
"
${
enable_dgc
}
"
in
True
)
;;
False
)
;;
*
)
echo
"not support argument -enable_dgc:
${
dgc
}
"
;
exit
1
;;
esac
export
MODEL
=
"DistResNet"
export
MODEL
=
"DistResNet"
export
PADDLE_TRAINER_ENDPOINTS
=
"127.0.0.1:7160,127.0.0.1:7161"
export
PADDLE_TRAINER_ENDPOINTS
=
"127.0.0.1:7160,127.0.0.1:7161"
...
@@ -9,16 +31,20 @@ mkdir -p logs
...
@@ -9,16 +31,20 @@ mkdir -p logs
# NOTE: set NCCL_P2P_DISABLE so that can run nccl2 distribute train on one node.
# NOTE: set NCCL_P2P_DISABLE so that can run nccl2 distribute train on one node.
# You can set vlog to see more details' log.
# export GLOG_v=1
# export GLOG_logtostderr=1
PADDLE_TRAINING_ROLE
=
"TRAINER"
\
PADDLE_TRAINING_ROLE
=
"TRAINER"
\
PADDLE_CURRENT_ENDPOINT
=
"127.0.0.1:7160"
\
PADDLE_CURRENT_ENDPOINT
=
"127.0.0.1:7160"
\
PADDLE_TRAINER_ID
=
"0"
\
PADDLE_TRAINER_ID
=
"0"
\
CUDA_VISIBLE_DEVICES
=
"0"
\
CUDA_VISIBLE_DEVICES
=
"0"
\
NCCL_P2P_DISABLE
=
"1"
\
NCCL_P2P_DISABLE
=
"1"
\
python
dist_train.py
--model
$MODEL
--update_method
nccl2
--batch_size
32
&> logs/tr0.log &
python
-u
dist_train.py
--enable_dgc
${
enable_dgc
}
--model
$MODEL
--update_method
nccl2
--batch_size
32
&> logs/tr0.log &
PADDLE_TRAINING_ROLE
=
"TRAINER"
\
PADDLE_TRAINING_ROLE
=
"TRAINER"
\
PADDLE_CURRENT_ENDPOINT
=
"127.0.0.1:7161"
\
PADDLE_CURRENT_ENDPOINT
=
"127.0.0.1:7161"
\
PADDLE_TRAINER_ID
=
"1"
\
PADDLE_TRAINER_ID
=
"1"
\
CUDA_VISIBLE_DEVICES
=
"1"
\
CUDA_VISIBLE_DEVICES
=
"1"
\
NCCL_P2P_DISABLE
=
"1"
\
NCCL_P2P_DISABLE
=
"1"
\
python
dist_train.py
--model
$MODEL
--update_method
nccl2
--batch_size
32
&> logs/tr1.log &
python
-u
dist_train.py
--enable_dgc
${
enable_dgc
}
--model
$MODEL
--update_method
nccl2
--batch_size
32
&> logs/tr1.log &
PaddleCV/image_classification/images/resnet_dgc.png
0 → 100644
浏览文件 @
c50d1f18
49.9 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}