Add SMOKE model (#5308)
* add SMOKE
* add deployment
* add pretrained link.
* Update README.md
* Update README.md
* Update README.md
* update config
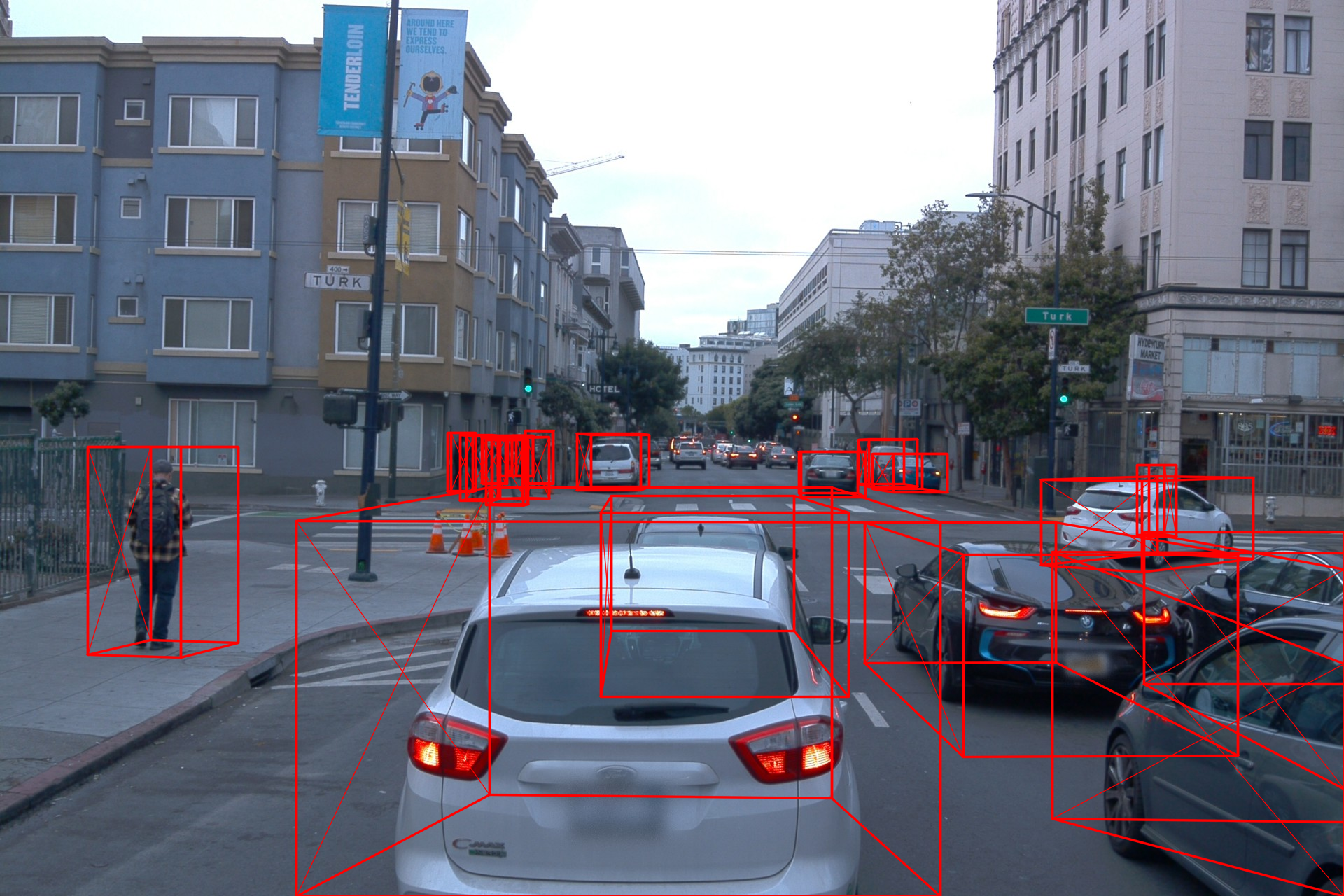
* add figure
* fix a typo
* delete unused codes
* add reference links
* resolved problems
* change to 2.1
Co-authored-by: Nliuyi22 <liuyi22@baidu.com>
Showing
{kind=link}
3.1 MB
{kind=link}

3.0 MB
PaddleCV/3d_vision/SMOKE/test.py
0 → 100644
此差异已折叠。
PaddleCV/3d_vision/SMOKE/train.py
0 → 100644
PaddleCV/3d_vision/SMOKE/val.py
0 → 100644
此差异已折叠。