Upgrade plato2 using paddle2.0 (#5002)
* The first version of plato2. Not finished the network. * Update decode stratage. * Update decode stratage. * Completed the encoder and decoder. But it will oom. * Completed the encoder and decoder. * backend the code. * Only completed the network of plato2 and nsp. * Completed the development. But the effect has not be verified. * Add readme and remove the code about deal PY2 and PY3. * Modify comment. * Modify readme and add images. * Delete the data folder.
Showing
{kind=link}

187.8 KB
{kind=link}
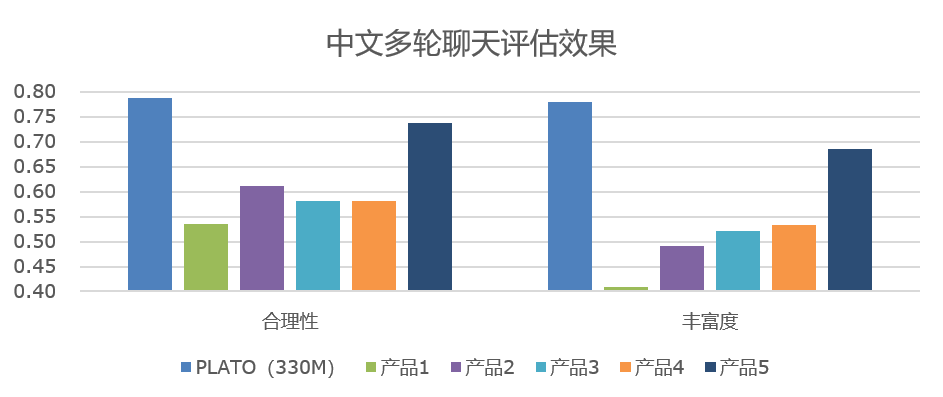
17.7 KB
{kind=link}
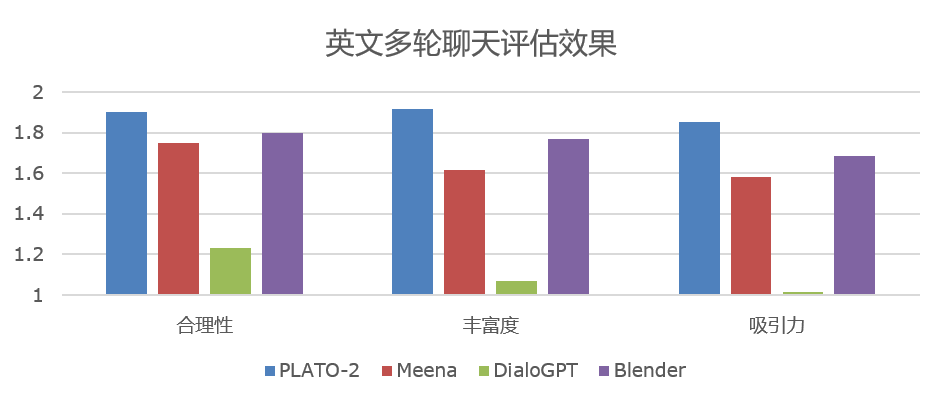
17.1 KB
{kind=link}
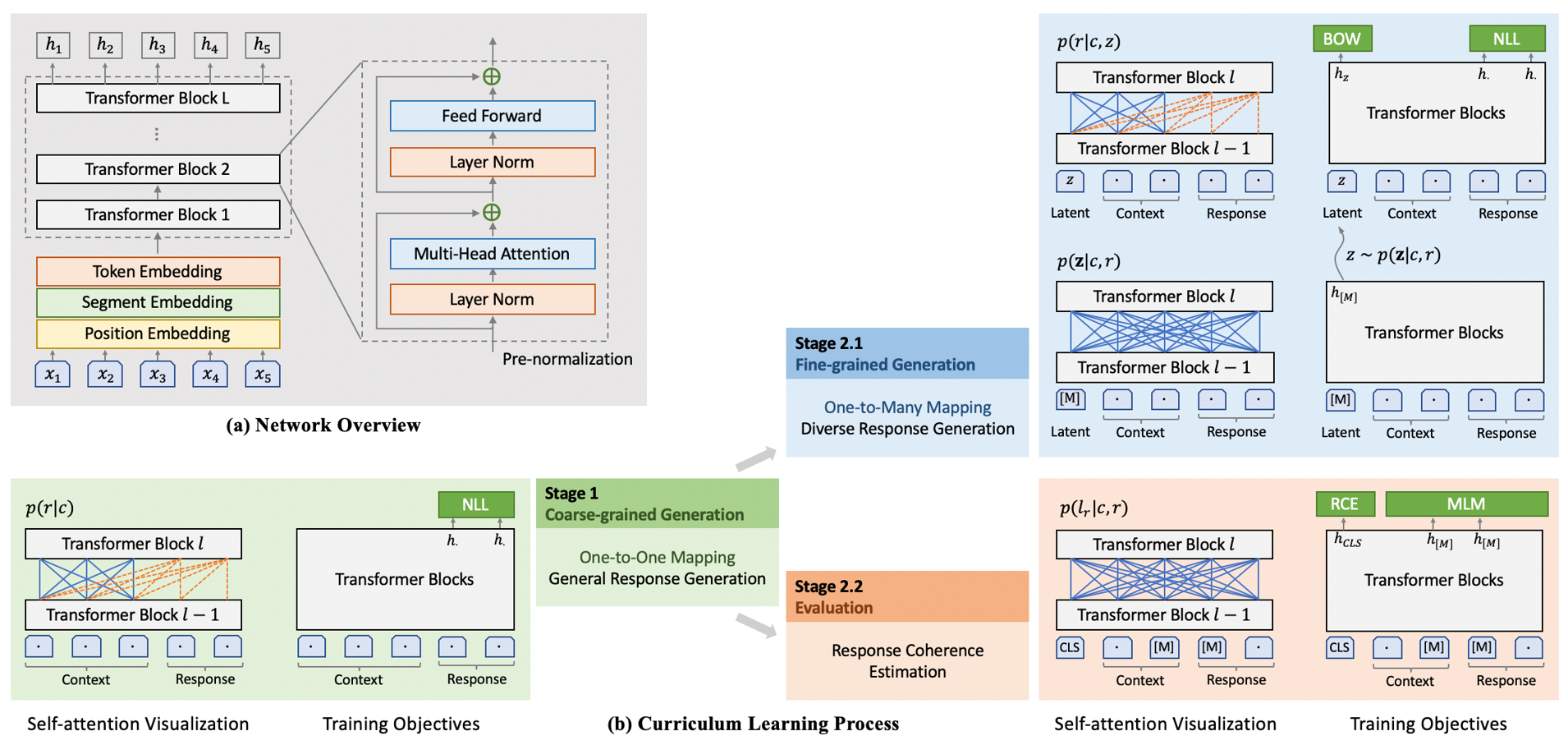
1.6 MB