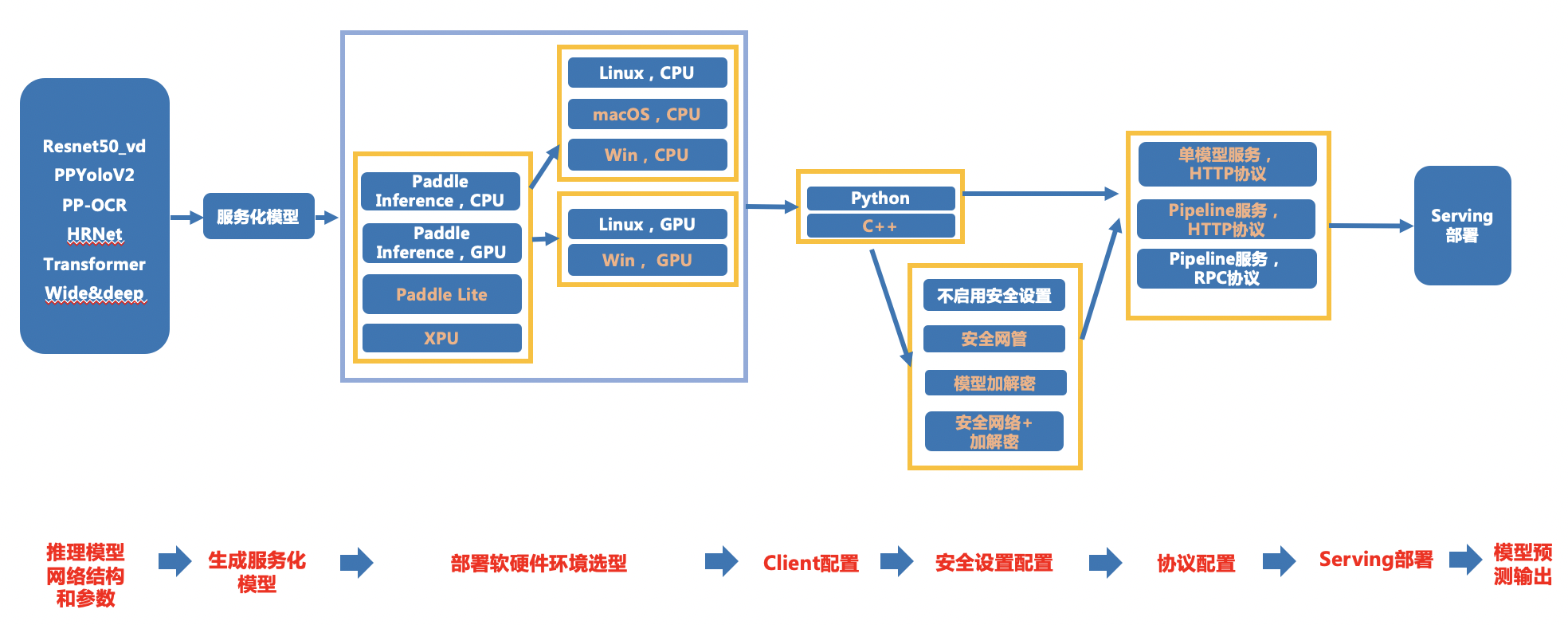
训推一体 CI 机制,旨在监控框架代码更新可能导致的**模型训练、预测报错、性能下降**等问题。本文主要介绍训推一体中**Paddle2ONNX预测链条**的接入规范和监测点,是在[基础链条](http://agroup.baidu.com/paddlepaddle/md/article/4273691)上针对Paddle2ONNX链条的补充说明。
主要监控的内容有:
- 框架更新后,套件模型的 Paddle2ONNX 预测是否能正常走通;(比如 API 的不兼容升级)
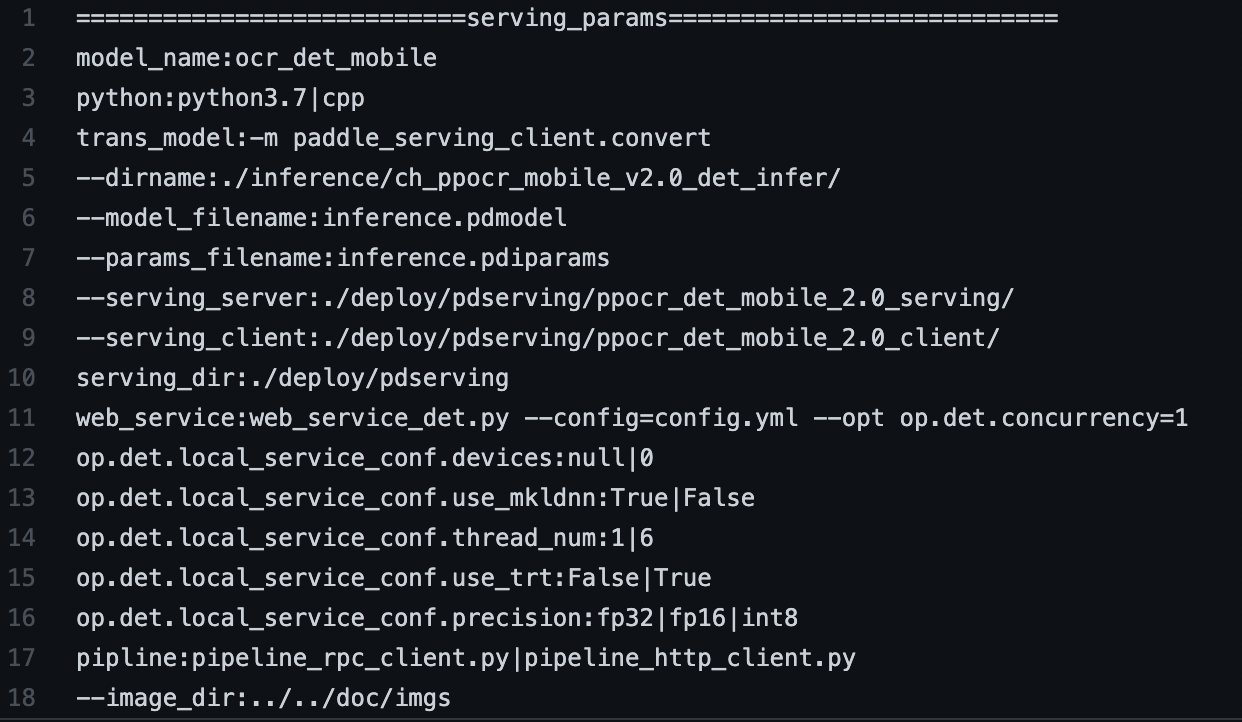
为了能监控上述问题,希望把套件模型的 Paddle2ONNX 预测链条加到框架的 CI 和 CE 中,提升 PR 合入的质量。因此,需要在套件中加入运行脚本(不影响套件正常运行),完成模型的自动化测试。
cd ./inference && tar xf ch_ppocr_mobile_v2.0_det_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf ch_ppocr_server_v2.0_rec_infer.tar && tar xf ch_ppocr_server_v2.0_det_infer.tar && tar xf ch_det_data_50.tar && tar xf rec_inference.tar && cd ../
{kind=link}
{kind=link}
{kind=link}
