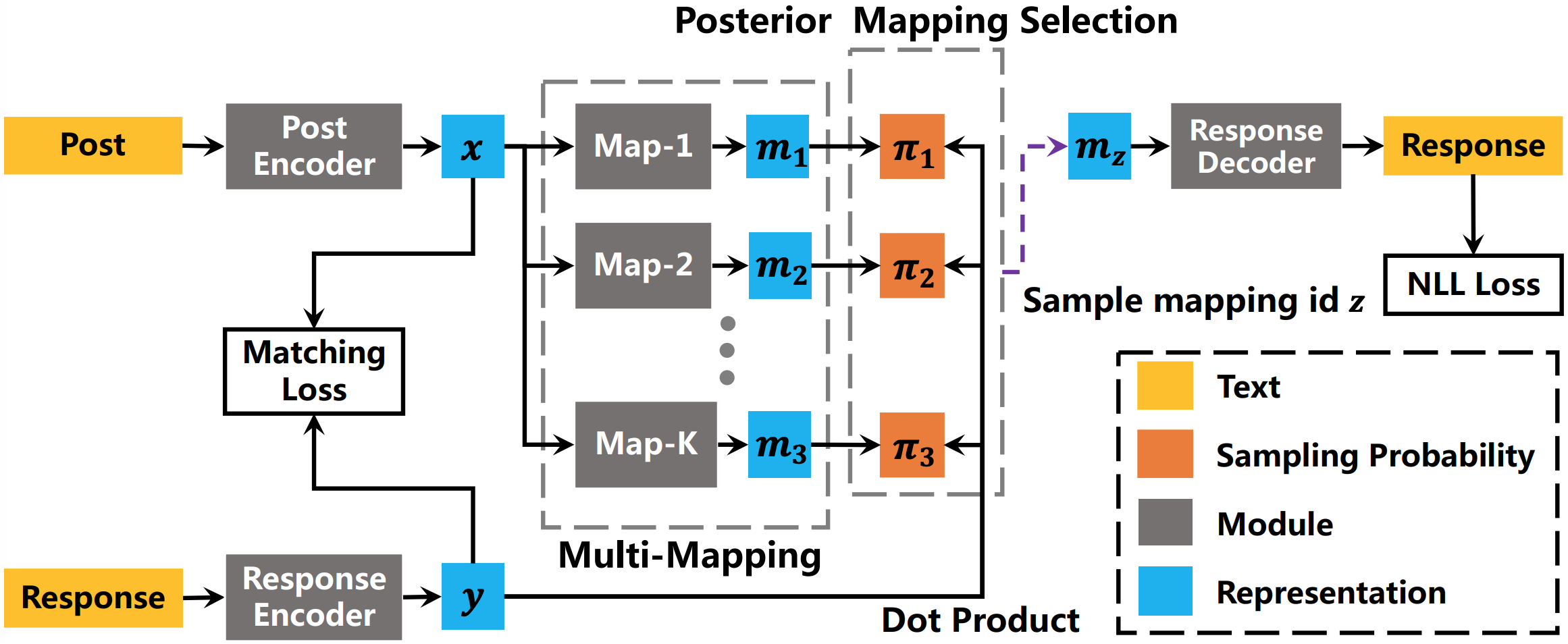
This is an implementation of **MMPMS** model for the one-to-many problem in open-domain conversation. MMPMS employs a *multi-mapping* mechanism to capture the one-to-many responding regularities between an input post and its diverse responses with multiple mapping modules. MMPMS also incorporates a *posterior mapping selection* module to identify the mapping module corresponding to the target response for accurate optimization. Experiments on Weibo and Reddit conversation dataset demonstrate the capacity of MMPMS in generating multiple diverse and informative responses.For more details, see the IJCAI-2019 paper: [Generating Multiple Diverse Responses with Multi-Mapping and Posterior Mapping Selection](https://arxiv.org/abs/1906.01781).
<palign="center">
<imgsrc="./images/architechture.png"width="500">
</p>
## 2. Quick Start
### Requirements
- Python >= 3.6
- PaddlePaddle >= 1.3.2 && <= 1.4.1
- NLTK
### Data Preparation
Prepare one-turn conversation dataset (e.g. [Weibo](https://www.aclweb.org/anthology/P15-1152) and [Reddit](https://www.ijcai.org/proceedings/2018/0643.pdf)), and put the train/valid/test data files into the `data` folder:
```
data/
├── dial.train
├── dial.valid
└── dial.test
```
In the data file, each line is a post-response pair formatted by `post \t response`.
Prepare pre-trained word embedding (e.g. [sgns.weibo.300d.txt](https://pan.baidu.com/s/1zbuUJEEEpZRNHxZ7Gezzmw) for Weibo and [glove.840B.300d.txt](http://nlp.stanford.edu/data/glove.840B.300d.zip) for Reddit), and put it into the `data` folder. The first line of pre-trained word embedding file should be formatted by `num_words embedding_dim`.
Preprocess the data by running:
```pyhton
python preprocess.py
```
The vocabulary and the preprocessed data will be saved in the same `data` folder:
```
data/
├── dial.train.pkl
├── dial.valid.pkl
├── dial.test.pkl
└── vocab.json
```
### Train
To train a model, run:
```python
pythonrun.py--data_dirDATA_DIR
```
The logs and model parameters will be saved to the `./output` folder by default.
### Test
Generate text result to `RESULT_FILE` with the saved model in `MODEL_DIR` by running:
{kind=link}