Init paddle-nlp (#2112)
* init paddle-nlp tools for QA test * Fix paragraph extraction bug * Update download links * first update LAC README.md * rename EmoTect as emotion_detection * download data from bos * Update README.md * Rename project * second add code * modify downloads.sh for lac * rename LAC to lexical_analysis * update lac readme * Update README.md * Update README.md * Update README.md * add struct.jpg * Update README.md * Update README.md * update README * Update README.md * update emotion_detection README * add download_data.sh and download_model.sh * first commit ADE * dialogue_model_toolkit_update * update emotion_detection model bos url * update README * update readme * update readme * update download file * first commit DAM * add readme * fix readme * fix readme * fix readme * fix readme * fix readme * rename * rename again * 1. add gradient_clip for ernie_lac 2. delete LARK config * fix download.sh * Rename MRC task * fix logger * fix to douban * fix final * update readme * update readme * update readme * fix batch is null * fix typo * fix typo * fix typo * update ernie config * update readme * add AI platform url in readme * update readme subtitlestyle * update * Update README.md * Update README.md * update * Create README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * update batch size * adapt to samll data size * update ERNIE bcebos url * add language model * modify readme * update * update * Update README.md * Update README.md * fix readme * fix max_step, update run.sh and run_ernie.sh * add finetuned model for lac * fix bug * Update README.md * update * Update README.md * add ERNIE pretrained model, and update README * update readme * add CPU * update infer in run.sh and run_ernie.sh * Update README.md * Update README.md * Delete test.py * fix bug * fix run.sh infer bug & add ernie infer code * fix cpu mode * Update README.md * fix bug for python3 * fix CPU and GPU diff result bug * Update README.md * update readme * Update run_classifier.py * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update run.sh * Update run_ernie.sh * modify dir * Update README.md * modify dir too * modify path * Update README.md * PaddleNLP modules backup to old/, rm links-LAC,Senta,SimNet * mv all modules out of paddle-nlp, rm Senta, auto_dialog_eval, deep_match * mv models/classify to models/classification, models/seq_lab to models/sequence_labeling * update readme for models/classification * update sentiment_classification and rm README * Add Transformer into paddle-nlp * change seq_lab to sequence labeling * Rename old as unarchived in PaddleNLP * add LARK * Update README, add paddlehub * add paddlehub * Add tmp readme * Update README.md * Update README.md * Update README.md * Update README.md * Update run_ernie.sh * Update run_ernie.sh * Update README.md * Update run_ernie_classifier.py * Update README.md * Update README.md * Update run.sh * Update run_ernie_classifier.py * update * fix chunk_evaluator bug * change names * Update README * add gitmodules * add install code * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update READMEs * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * README * Update README.md * update emotion_detection README * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * update REAME, add finetune doc * update emotion_detection readme * change run.sh * Update README.md * Update the link in fluid dir * update readme * update README for markdown style * Update README.md * Update README.md
Showing
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
knowledge_driven_dialogue @ 199af066
文件已移动
此差异已折叠。
文件已移动
PaddleNLP/language_model/run.sh
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
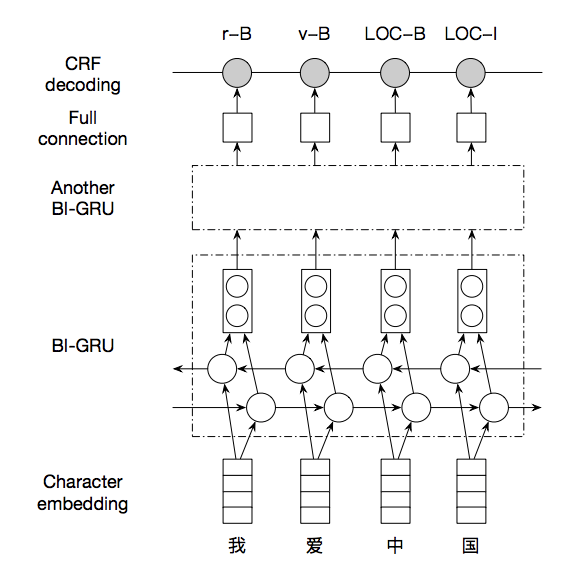
60.9 KB
此差异已折叠。
PaddleNLP/lexical_analysis/run.sh
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
PaddleNLP/models/matching/bow.py
0 → 100644
此差异已折叠。
PaddleNLP/models/matching/cnn.py
0 → 100644
此差异已折叠。
PaddleNLP/models/matching/gru.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
PaddleNLP/models/matching/lstm.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
PaddleNLP/preprocess/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
PaddleNLP/preprocess/padding.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
PaddleNLP/similarity_net/run.sh
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
PaddleNLP/similarity_net/utils.py
0 → 100644
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
{kind=link}
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。