Add train_amp_python (#5449)
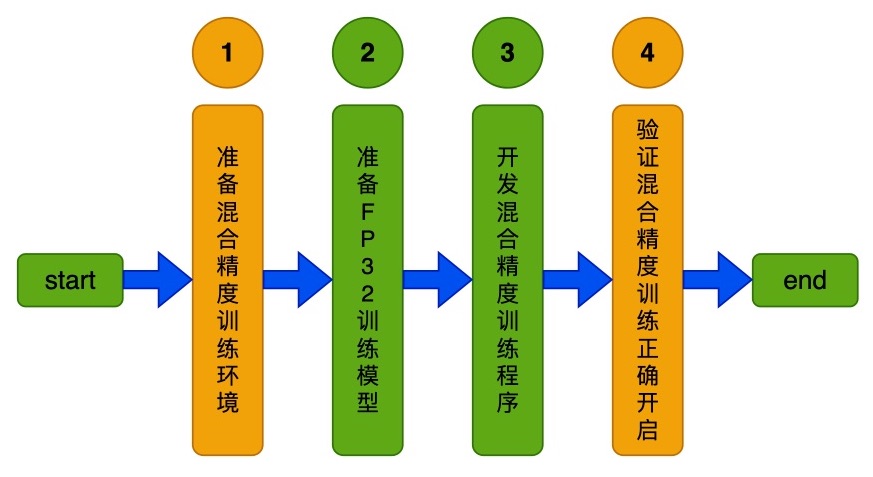
* add train_amp_python * refine picture * add mv3 amp train doc * refine doc * refine code * refine * refine
Showing
{kind=link}
63.0 KB
* add train_amp_python * refine picture * add mv3 amp train doc * refine doc * refine code * refine * refine
63.0 KB