Merge pull request #43 from pakchoi/add_nce_cost
Add the NCE example.
Showing
nce_cost/images/network_conf.png
0 → 100644
{kind=link}
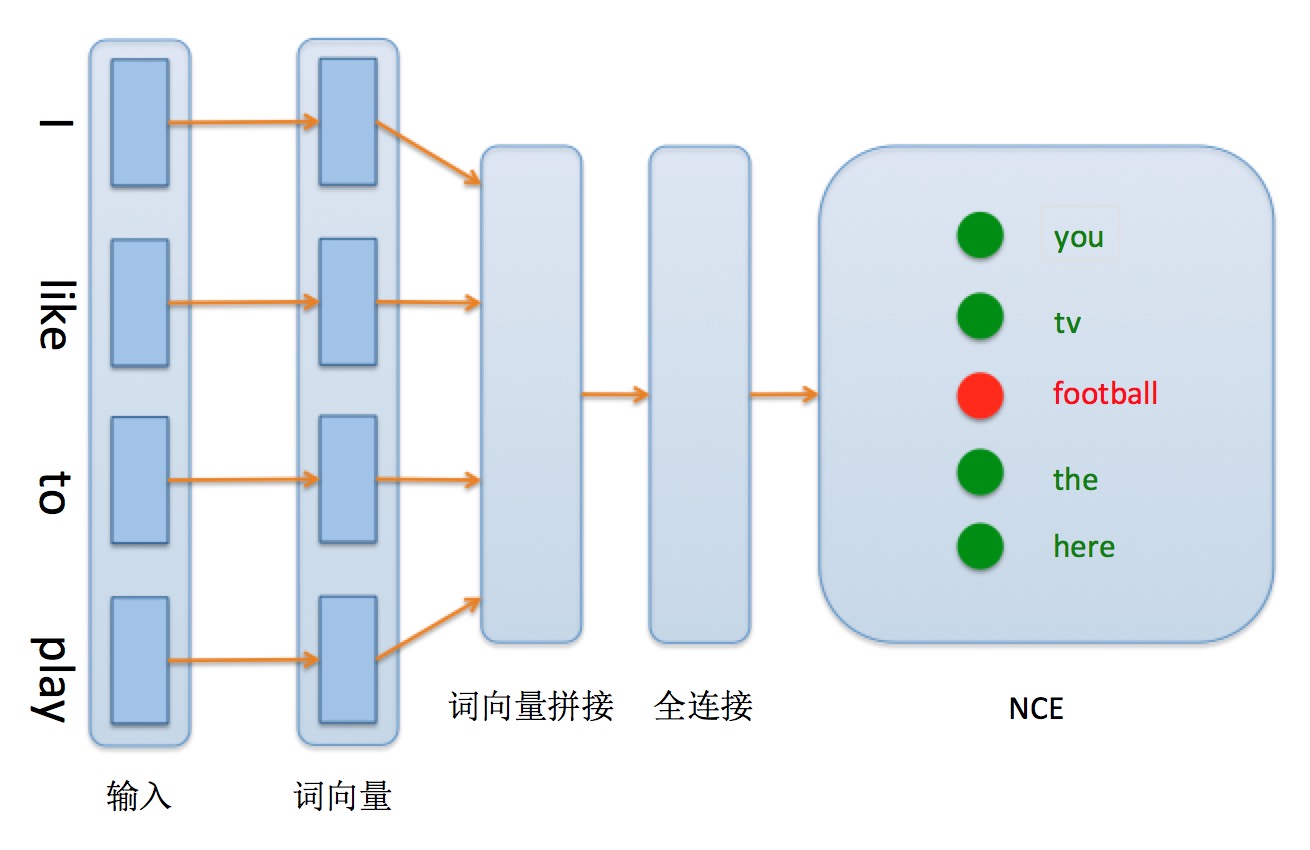
102.9 KB
nce_cost/infer.py
0 → 100644
nce_cost/nce_conf.py
0 → 100644
nce_cost/train.py
0 → 100644