Merge branch 'develop' into refactor_readme
Showing
ctr/README.md
0 → 100644
ctr/data_provider.py
0 → 100644
ctr/dataset.md
0 → 100644
ctr/images/lr_vs_dnn.jpg
0 → 100644
{kind=link}
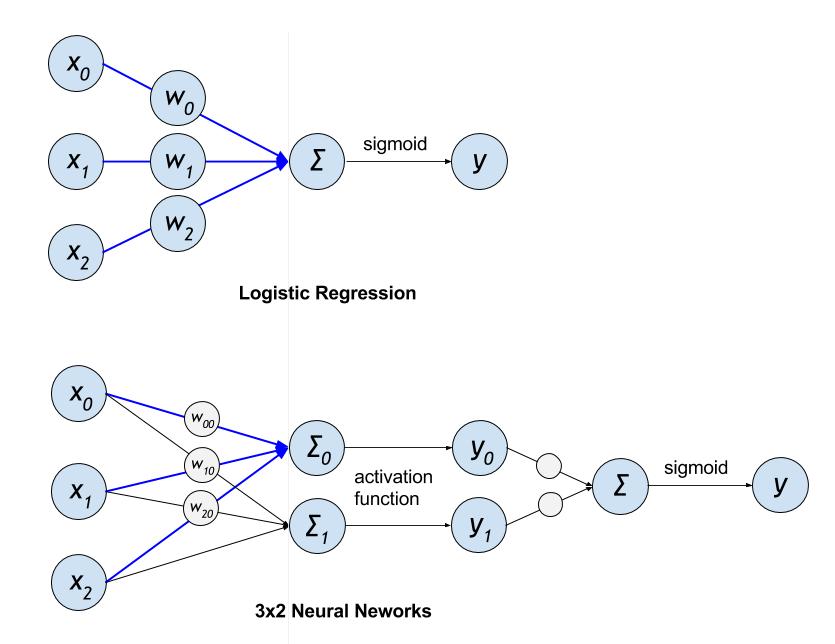
43.1 KB
ctr/images/wide_deep.png
0 → 100644
{kind=link}
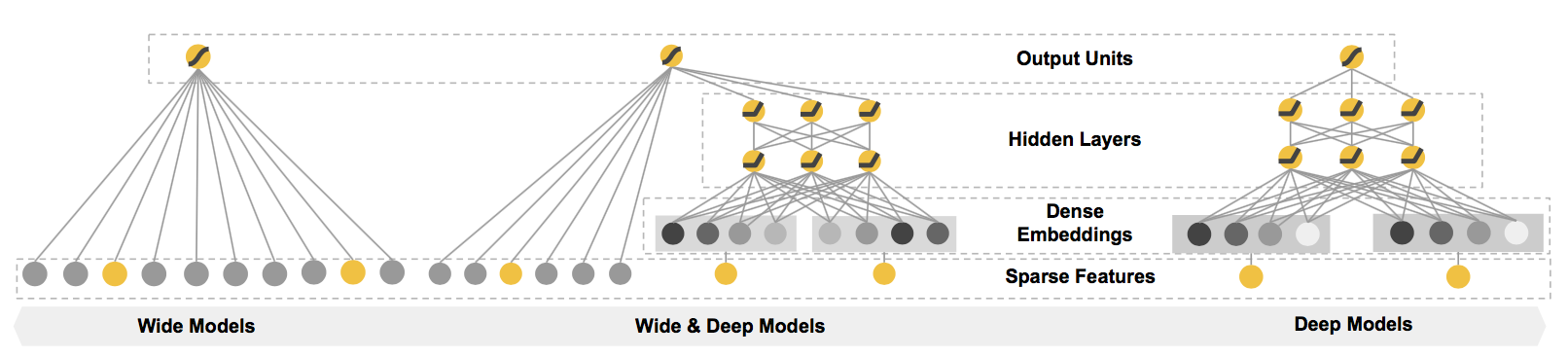
139.6 KB
ctr/train.py
0 → 100644