Merge branch 'develop' of upstream into infer_ckpt
Showing
fluid/DeepQNetwork/DQN.py
已删除
100644 → 0
fluid/DeepQNetwork/DQN_agent.py
0 → 100644
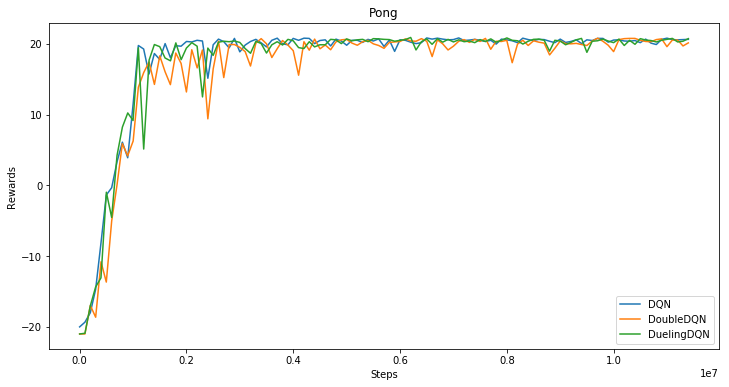
fluid/DeepQNetwork/assets/dqn.png
0 → 100644
{kind=link}
38.1 KB
fluid/DeepQNetwork/atari.py
0 → 100644
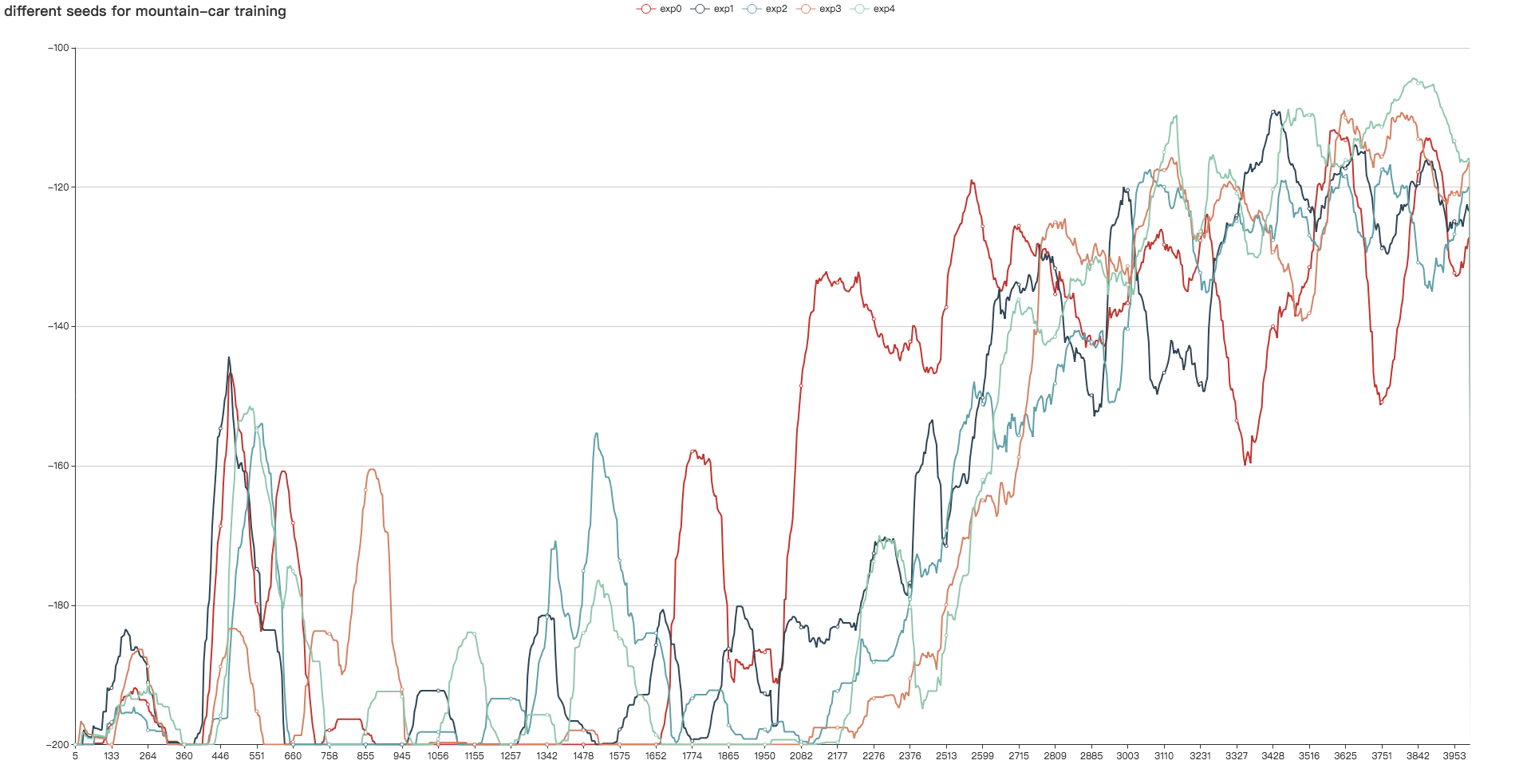
fluid/DeepQNetwork/curve.png
已删除
100644 → 0
{kind=link}
442.3 KB
{kind=link}

98.6 KB
fluid/DeepQNetwork/play.py
0 → 100644
文件已添加
文件已添加
fluid/DeepQNetwork/train.py
0 → 100644
fluid/DeepQNetwork/utils.py
0 → 100644
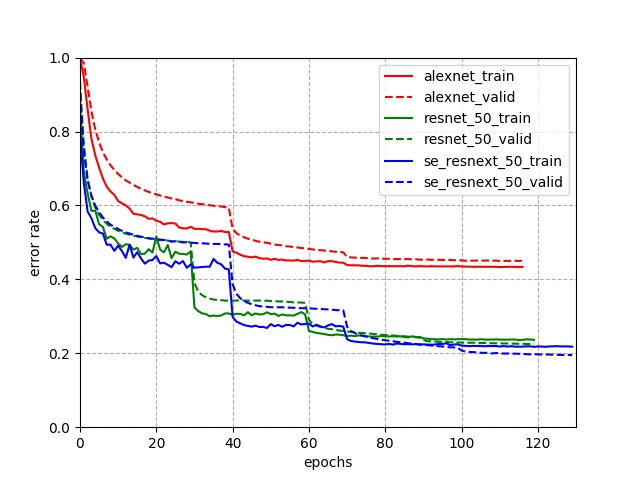
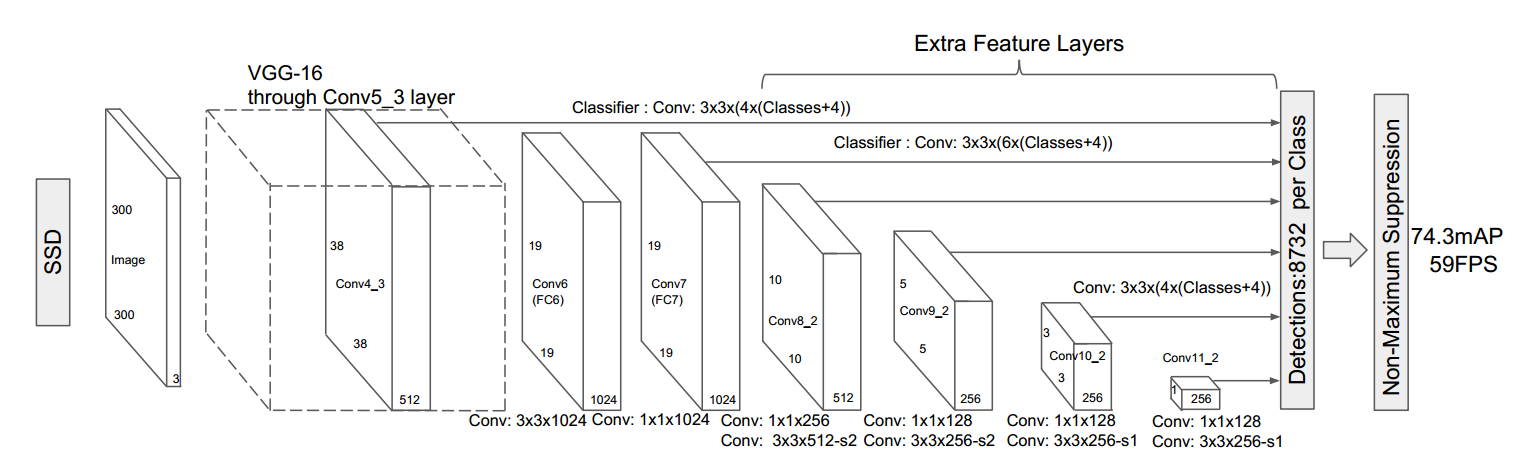
fluid/face_detection/infer.py
0 → 100644
{kind=link}
72.4 KB
{kind=link}

24.1 KB
{kind=link}

42.1 KB
{kind=link}

32.7 KB
{kind=link}

47.6 KB
{kind=link}
126.0 KB