Merge branch 'develop' of https://github.com/PaddlePaddle/models into ctc_reader
Showing
fluid/DeepASR/data_utils/util.py
0 → 100644
youtube_recall/README.cn.md
0 → 100644
此差异已折叠。
youtube_recall/README.md
0 → 100644
此差异已折叠。
youtube_recall/data/data.tar
0 → 100644
文件已添加
youtube_recall/data_processor.py
0 → 100644
{kind=link}

241.5 KB
{kind=link}
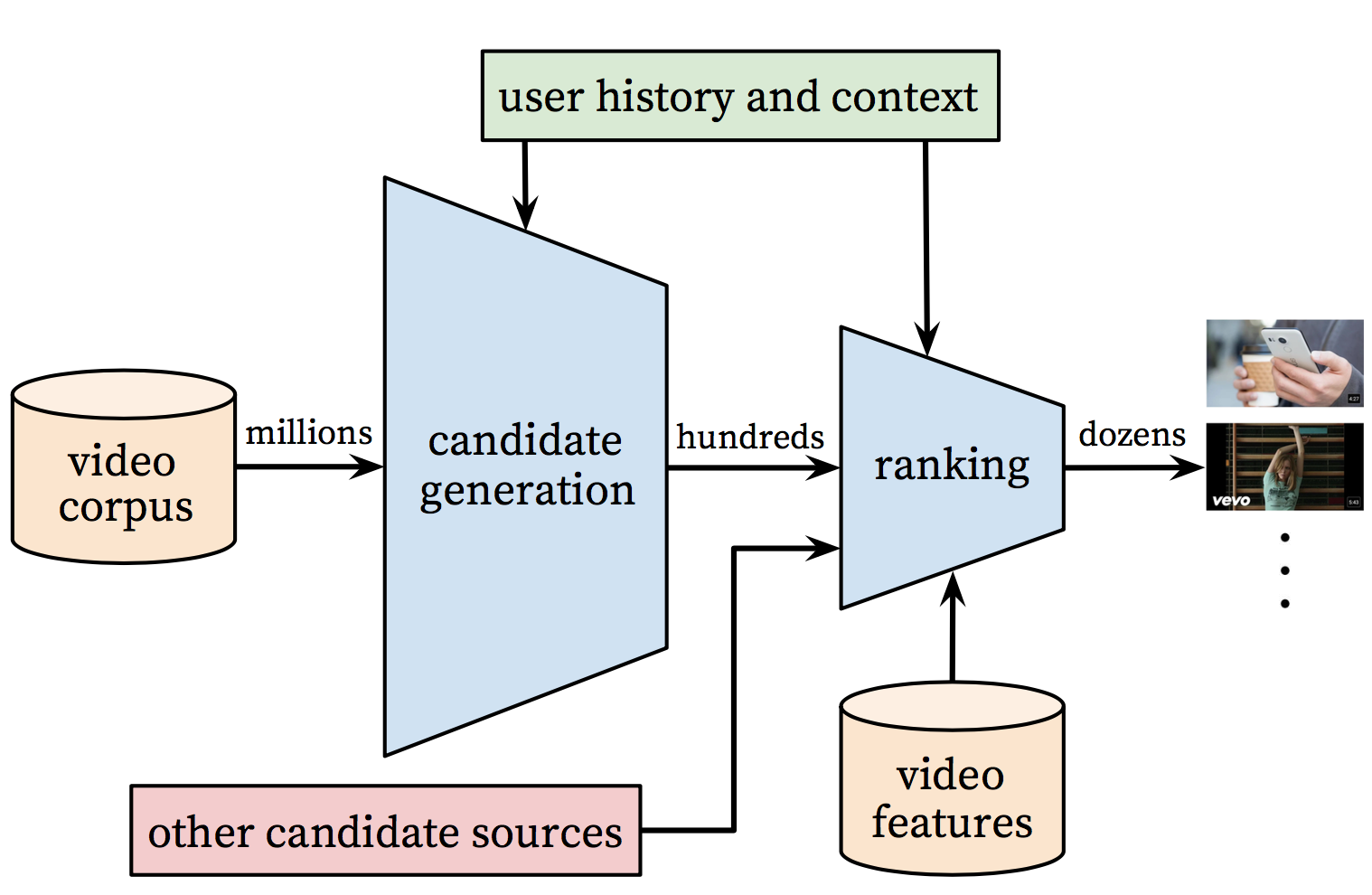
182.1 KB
youtube_recall/infer.py
0 → 100644
youtube_recall/infer_user.py
0 → 100644
youtube_recall/item_vector.py
0 → 100644
youtube_recall/network_conf.py
0 → 100644
youtube_recall/reader.py
0 → 100644
youtube_recall/train.py
0 → 100644
youtube_recall/user_vector.py
0 → 100644
youtube_recall/utils.py
0 → 100644