Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
8e4eebfc
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
8e4eebfc
编写于
2月 04, 2020
作者:
A
anpark
提交者:
GitHub
2月 04, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add kdd2020-p3ac (#4238)
* update README * fix monopoly info * add kdd2020-p3ac * add kdd2020-p3ac
上级
a026656e
变更
12
展开全部
隐藏空白更改
内联
并排
Showing
12 changed file
with
1667 addition
and
7 deletion
+1667
-7
PaddleST/README.md
PaddleST/README.md
+1
-0
PaddleST/Research/CIKM2019-MONOPOLY/README.md
PaddleST/Research/CIKM2019-MONOPOLY/README.md
+1
-1
PaddleST/Research/CIKM2019-MONOPOLY/conf/house_price/house_price.local.template
...2019-MONOPOLY/conf/house_price/house_price.local.template
+1
-1
PaddleST/Research/CIKM2019-MONOPOLY/nets/house_price/house_price.py
...esearch/CIKM2019-MONOPOLY/nets/house_price/house_price.py
+8
-5
PaddleST/Research/KDD2020-P3AC/README.md
PaddleST/Research/KDD2020-P3AC/README.md
+78
-0
PaddleST/Research/KDD2020-P3AC/conf/poi_qac_personalized/poi_qac_personalized.local.conf.template
...qac_personalized/poi_qac_personalized.local.conf.template
+342
-0
PaddleST/Research/KDD2020-P3AC/datasets/poi_qac_personalized/__init__.py
...ch/KDD2020-P3AC/datasets/poi_qac_personalized/__init__.py
+0
-0
PaddleST/Research/KDD2020-P3AC/datasets/poi_qac_personalized/qac_personalized.py
...20-P3AC/datasets/poi_qac_personalized/qac_personalized.py
+577
-0
PaddleST/Research/KDD2020-P3AC/docs/framework.png
PaddleST/Research/KDD2020-P3AC/docs/framework.png
+0
-0
PaddleST/Research/KDD2020-P3AC/nets/poi_qac_personalized/__init__.py
...search/KDD2020-P3AC/nets/poi_qac_personalized/__init__.py
+0
-0
PaddleST/Research/KDD2020-P3AC/nets/poi_qac_personalized/qac_personalized.py
...DD2020-P3AC/nets/poi_qac_personalized/qac_personalized.py
+659
-0
PaddleST/Research/KDD2020-P3AC/test/__init__.py
PaddleST/Research/KDD2020-P3AC/test/__init__.py
+0
-0
未找到文件。
PaddleST/README.md
浏览文件 @
8e4eebfc
...
@@ -19,3 +19,4 @@ The full list of frontier industrial projects:
...
@@ -19,3 +19,4 @@ The full list of frontier industrial projects:
|应用项目|项目简介|开源地址|
|应用项目|项目简介|开源地址|
|----|----|----|
|----|----|----|
||||
||||
PaddleST/Research/CIKM2019-MONOPOLY/README.md
浏览文件 @
8e4eebfc
...
@@ -29,7 +29,7 @@ We have conducted extensive experiments with the large-scale urban data of sever
...
@@ -29,7 +29,7 @@ We have conducted extensive experiments with the large-scale urban data of sever
1.
paddle安装
1.
paddle安装
本项目依赖于Paddle Fluid 1.
5
.1 及以上版本,请参考[安装指南](http://www.paddlepaddle.org/#quick-start)进行安装
本项目依赖于Paddle Fluid 1.
6
.1 及以上版本,请参考[安装指南](http://www.paddlepaddle.org/#quick-start)进行安装
2.
下载代码
2.
下载代码
...
...
PaddleST/Research/CIKM2019-MONOPOLY/conf/house_price/house_price.local.template
浏览文件 @
8e4eebfc
...
@@ -280,7 +280,7 @@ num_in_dimension: ${DEFAULT:num_in_dimension}
...
@@ -280,7 +280,7 @@ num_in_dimension: ${DEFAULT:num_in_dimension}
num_out_dimension: ${DEFAULT:num_out_dimension}
num_out_dimension: ${DEFAULT:num_out_dimension}
# Directory where the results are saved to
# Directory where the results are saved to
eval_dir: ${Train:train_dir}/
epoch<s>
eval_dir: ${Train:train_dir}/
checkpoint_1
# The number of samples in each batch
# The number of samples in each batch
batch_size: ${DEFAULT:eval_batch_size}
batch_size: ${DEFAULT:eval_batch_size}
PaddleST/Research/CIKM2019-MONOPOLY/nets/house_price/house_price.py
浏览文件 @
8e4eebfc
...
@@ -77,8 +77,7 @@ class HousePrice(BaseNet):
...
@@ -77,8 +77,7 @@ class HousePrice(BaseNet):
act
=
act
)
act
=
act
)
return
_fc
return
_fc
def
pred_format
(
self
,
result
,
**
kwargs
):
def
pred_format
(
self
,
result
):
"""
"""
format pred output
format pred output
"""
"""
...
@@ -118,7 +117,7 @@ class HousePrice(BaseNet):
...
@@ -118,7 +117,7 @@ class HousePrice(BaseNet):
max_house_num
=
FLAGS
.
max_house_num
max_house_num
=
FLAGS
.
max_house_num
max_public_num
=
FLAGS
.
max_public_num
max_public_num
=
FLAGS
.
max_public_num
pred_keys
=
inputs
.
keys
()
#step1. get house self feature
#step1. get house self feature
if
FLAGS
.
with_house_attr
:
if
FLAGS
.
with_house_attr
:
def
_get_house_attr
(
name
,
attr_vec_size
):
def
_get_house_attr
(
name
,
attr_vec_size
):
...
@@ -136,6 +135,10 @@ class HousePrice(BaseNet):
...
@@ -136,6 +135,10 @@ class HousePrice(BaseNet):
else
:
else
:
#no house attr
#no house attr
house_vec
=
fluid
.
layers
.
reshape
(
inputs
[
"house_business"
],
[
-
1
,
self
.
city_info
.
business_num
])
house_vec
=
fluid
.
layers
.
reshape
(
inputs
[
"house_business"
],
[
-
1
,
self
.
city_info
.
business_num
])
pred_keys
.
remove
(
'house_wuye'
)
pred_keys
.
remove
(
'house_kfs'
)
pred_keys
.
remove
(
'house_age'
)
pred_keys
.
remove
(
'house_lou'
)
house_self
=
self
.
fc_fn
(
house_vec
,
1
,
act
=
'sigmoid'
,
layer_name
=
'house_self'
,
FLAGS
=
FLAGS
)
house_self
=
self
.
fc_fn
(
house_vec
,
1
,
act
=
'sigmoid'
,
layer_name
=
'house_self'
,
FLAGS
=
FLAGS
)
house_self
=
fluid
.
layers
.
reshape
(
house_self
,
[
-
1
,
1
])
house_self
=
fluid
.
layers
.
reshape
(
house_self
,
[
-
1
,
1
])
...
@@ -192,8 +195,8 @@ class HousePrice(BaseNet):
...
@@ -192,8 +195,8 @@ class HousePrice(BaseNet):
net_output
=
{
"debug_output"
:
debug_output
,
net_output
=
{
"debug_output"
:
debug_output
,
"model_output"
:
model_output
}
"model_output"
:
model_output
}
model_output
[
'feeded_var_names'
]
=
inputs
.
keys
()
model_output
[
'feeded_var_names'
]
=
pred_keys
model_output
[
'
target_var
s'
]
=
[
label
,
pred
]
model_output
[
'
fetch_target
s'
]
=
[
label
,
pred
]
model_output
[
'loss'
]
=
avg_cost
model_output
[
'loss'
]
=
avg_cost
#debug_output['pred'] = pred
#debug_output['pred'] = pred
...
...
PaddleST/Research/KDD2020-P3AC/README.md
0 → 100644
浏览文件 @
8e4eebfc
# P3AC
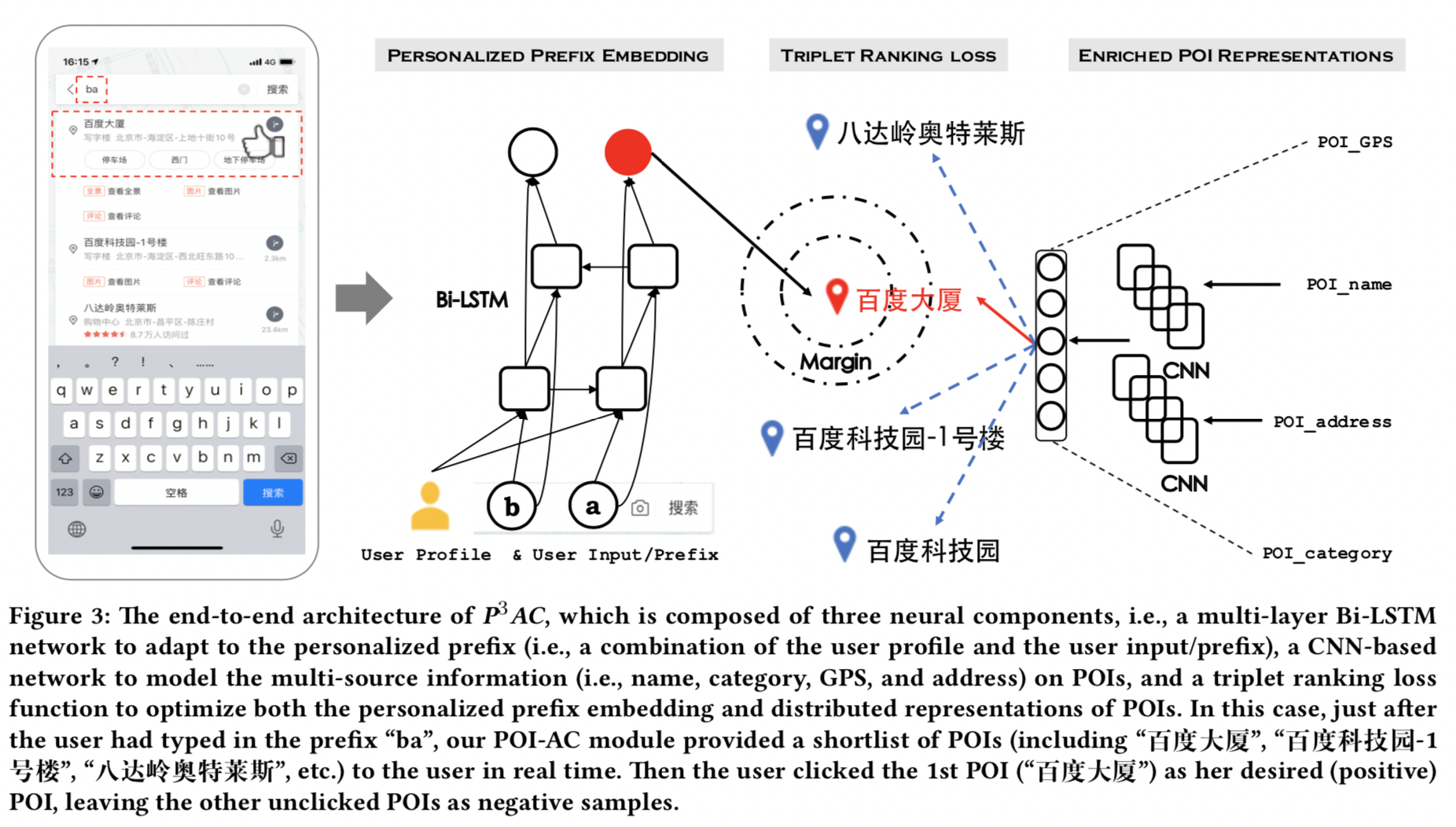
## 任务说明(Introduction)
TODO

## 安装说明(Install Guide)
### 环境准备
1.
paddle安装
本项目依赖于Paddle Fluid 1.6.1 及以上版本,请参考[安装指南](http://www.paddlepaddle.org/#quick-start)进行安装
2.
下载代码
克隆数据集代码库到本地, 本代码依赖[Paddle-EPEP框架](https://github.com/PaddlePaddle/epep)
```
git clone https://github.com/PaddlePaddle/epep.git
cd epep
git clone https://github.com/PaddlePaddle/models.git
ln -s models/PaddleST/Research/KDD2020-P3AC/conf/poi_qac_personalized conf/poi_qac_personalized
ln -s models/PaddleST/Research/KDD2020-P3AC/datasets/poi_qac_personalized datasets/poi_qac_personalized
ln -s models/PaddleST/Research/KDD2020-P3AC/nets/poi_qac_personalized nets/poi_qac_personalized
```
3.
环境依赖
python版本依赖python 2.7
### 实验说明
1.
数据准备
TODO
```
#script to download
```
2.
模型训练
```
cp conf/poi_qac_personalized/poi_qac_personalized.local.conf.template conf/poi_qac_personalized/poi_qac_personalized.local.conf
sh run.sh -c conf/poi_qac_personalized/poi_qac_personalized.local.conf -m train [ -g 0 ]
```
3.
模型评估
```
pred_gpu=$1
mode=$2 #query, poi, eval
if [ $# -lt 2 ];then
exit 1
fi
#编辑conf/poi_qac_personalized/poi_qac_personalized.local.conf.template,打开 CUDA_VISIBLE_DEVICES: <pred_gpu>
cp conf/poi_qac_personalized/poi_qac_personalized.local.conf.template conf/poi_qac_personalized/poi_qac_personalized.local.conf
sed -i "s#<pred_gpu>#$pred_gpu#g" conf/poi_qac_personalized/poi_qac_personalized.local.conf
sed -i "s#<mode>#$mode#g" conf/poi_qac_personalized/poi_qac_personalized.local.conf
sh run.sh -c poi_qac_personalized.local -m predict 1>../tmp/$mode-pred$pred_gpu.out 2>../tmp/$mode-pred$pred_gpu.err
```
## 论文下载(Paper Download)
Please feel free to review our paper :)
TODO
## 引用格式(Paper Citation)
TODO
PaddleST/Research/KDD2020-P3AC/conf/poi_qac_personalized/poi_qac_personalized.local.conf.template
0 → 100644
浏览文件 @
8e4eebfc
[DEFAULT]
sample_seed: 1234
# The value in `DEFAULT` section will be referenced by other sections.
# For convinence, we will put the variables which changes frequently here and
# let other section refer them
debug_mode: False
#reader: dataset | pyreader | async | datafeed | sync
#data_reader: dataset
dataset_mode: Memory
#data_reader: datafeed
data_reader: pyreader
py_reader_iterable: False
#model_type: lstm_net
model_type: cnn_net
vocab_size: 93896
#emb_dim: 200
emb_dim: 128
time_size: 28
tag_size: 371
fc_dim: 64
emb_lr: 1.0
base_lr: 0.001
margin: 0.35
window_size: 3
pooling_type: max
#activate: sigmoid
activate: None
use_attention: True
use_personal: True
max_seq_len: 128
prefix_word_id: True
#print_period: 200
#TODO personal_resident_drive + neg_only_sample
#query cityid trendency, poi tag/alias
#local-cpu | local-gpu | pserver-cpu | pserver-gpu | nccl2
platform: local-gpu
# Input settings
dataset_name: PoiQacPersonalized
CUDA_VISIBLE_DEVICES: 0,1,2,3
#CUDA_VISIBLE_DEVICES: <pred_gpu>
train_batch_size: 128
#train_batch_size: 2
eval_batch_size: 2
#file_list: ../tmp/data/poi/qac/train_data/part-00000
dataset_dir: ../tmp/data/poi/qac/train_data
#init_train_params: ../tmp/data/poi/qac/tencent_pretrain.words
tag_dict_path: None
qac_dict_path: None
kv_path: None
#qac_dict_path: ./datasets/poi_qac_personalized/qac_term.dict
#tag_dict_path: ./datasets/poi_qac_personalized/poi_tag.dict
#kv_path: ../tmp/data/poi/qac/kv
# Model settings
model_name: PoiQacPersonalized
preprocessing_name: None
#file_pattern: %s-part-*
file_pattern: part-
num_in_dimension: 3
num_out_dimension: 4
# Learning options
num_samples_train: 100
num_samples_eval: 10
max_number_of_steps: 155000
[Convert]
# The name of the dataset to convert
dataset_name: ${DEFAULT:dataset_name}
#dataset_dir: ${DEFAULT:dataset_dir}
dataset_dir: stream
# The output Records file name prefix.
dataset_split_name: train
# The number of Records per shard
num_per_shard: 100000
# The dimensions of net input vectors, it is just used by svm dataset
# which of input are sparse tensors now
num_in_dimension: ${DEFAULT:num_in_dimension}
# The output file name pattern with two placeholders ("%s" and "%d"),
# it must correspond to the glob `file_pattern' in Train and Evaluate
# config sections
#file_pattern: %s-part-%05d
file_pattern: part-
[Train]
#######################
# Dataset Configure #
#######################
# The name of the dataset to load
dataset_name: ${DEFAULT:dataset_name}
# The directory where the dataset files are stored
dataset_dir: ${DEFAULT:dataset_dir}
# dataset_split_name
dataset_split_name: train
batch_shuffle_size: 128
#log_exp or hinge
#loss_func: hinge
loss_func: log_exp
neg_sample_num: 5
reader_batch: True
drop_last_batch: False
# The glob pattern for data path, `file_pattern' must contain only one "%s"
# which is the placeholder for split name (such as 'train', 'validation')
file_pattern: ${DEFAULT:file_pattern}
# The file type text or record
file_type: record
# kv path, used in image_sim
kv_path: ${DEFAULT:kv_path}
# The number of input sample for training
num_samples: ${DEFAULT:num_samples_train}
# The number of parallel readers that read data from the dataset
num_readers: 2
# The number of threads used to create the batches
num_preprocessing_threads: 2
# Number of epochs from dataset source
num_epochs_input: 10
###########################
# Basic Train Configure #
###########################
# Directory where checkpoints and event logs are written to.
train_dir: ../tmp/model/poi/qac/save_model
# The max number of ckpt files to store variables
save_max_to_keep: 40
# The frequency with which the model is saved, in seconds.
save_model_secs: None
# The frequency with which the model is saved, in steps.
save_model_steps: 5000
# The name of the architecture to train
model_name: ${DEFAULT:model_name}
# The dimensions of net input vectors, it is just used by svm dataset
# which of input are sparse tensors now
num_in_dimension: ${DEFAULT:num_in_dimension}
# The dimensions of net output vector, it will be num of classes in image classify task
num_out_dimension: ${DEFAULT:num_out_dimension}
#####################################
# Training Optimization Configure #
#####################################
# The number of samples in each batch
batch_size: ${DEFAULT:train_batch_size}
# The maximum number of training steps
max_number_of_steps: ${DEFAULT:max_number_of_steps}
# The weight decay on the model weights
#weight_decay: 0.00000001
weight_decay: None
# The decay to use for the moving average. If left as None, then moving averages are not used
moving_average_decay: None
# ***************** learning rate options ***************** #
# Specifies how the learning rate is decayed. One of "fixed", "exponential" or "polynomial"
learning_rate_decay_type: fixed
# Learning rate decay factor
learning_rate_decay_factor: 0.1
# Proportion of training steps to perform linear learning rate warmup for
learning_rate_warmup_proportion: 0.1
init_learning_rate: 0
learning_rate_warmup_steps: 10000
# The minimal end learning rate used by a polynomial decay learning rate
end_learning_rate: 0.0001
# Number of epochs after which learning rate decays
num_epochs_per_decay: 10
# A boolean, whether or not it should cycle beyond decay_steps
learning_rate_polynomial_decay_cycle: False
# ******************* optimizer options ******************* #
# The name of the optimizer, one of the following:
# "adadelta", "adagrad", "adam", "ftrl", "momentum", "sgd" or "rmsprop"
#optimizer: weight_decay_adam
optimizer: adam
#optimizer: sgd
# Epsilon term for the optimizer, used for adadelta, adam, rmsprop
opt_epsilon: 1e-8
# conf for adadelta
# The decay rate for adadelta
adadelta_rho: 0.95
# Starting value for the AdaGrad accumulators
adagrad_initial_accumulator_value: 0.1
# conf for adam
# The exponential decay rate for the 1st moment estimates
adam_beta1: 0.9
# The exponential decay rate for the 2nd moment estimates
adam_beta2: 0.997
adam_weight_decay: 0.01
#adam_exclude_from_weight_decay: LayerNorm,layer_norm,bias
# conf for ftrl
# The learning rate power
ftrl_learning_rate_power: -0.1
# Starting value for the FTRL accumulators
ftrl_initial_accumulator_value: 0.1
# The FTRL l1 regularization strength
ftrl_l1: 0.0
# The FTRL l2 regularization strength
ftrl_l2: 0.01
# conf for momentum
# The momentum for the MomentumOptimizer and RMSPropOptimizer
momentum: 0.9
# conf for rmsprop
# Decay term for RMSProp
rmsprop_decay: 0.9
# Number of model clones to deploy
num_gpus: 3
#############################
# Log and Trace Configure #
#############################
# The frequency with which logs are print
log_every_n_steps: 100
# The frequency with which logs are trace.
trace_every_n_steps: 1
[Evaluate]
# process mode: pred, eval or export
#proc_name: eval
proc_name: pred
#data_reader: datafeed
py_reader_iterable: True
#platform: hadoop
platform: local-gpu
qac_dict_path: ./datasets/poi_qac_personalized/qac_term.dict
tag_dict_path: ./datasets/poi_qac_personalized/poi_tag.dict
#kv_path: ../tmp/data/poi/qac/kv
# The directory where the dataset files are stored
#file_list: ../tmp/x.bug
file_list: ../tmp/data/poi/qac/recall_data/<mode>/part-0<pred_gpu>
#file_list: ../tmp/data/poi/qac/ltr_data/<mode>/part-0<pred_gpu>
#dataset_dir: stream_record
# The directory where the model was written to or an absolute path to a checkpoint file
init_pretrain_model: ../tmp/model/poi/qac/save_model_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_personal_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_wordid_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_personal_wordid_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_attention_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_attention_personal_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_attention_wordid_logexp/checkpoint_125000
#init_pretrain_model: ../tmp/model/poi/qac/save_model_attention_personal_wordid_logexp/checkpoint_125000
model_type: cnn_net
fc_dim: 64
use_attention: False
use_personal: False
prefix_word_id: False
#dump_vec: query
#dump_vec: <mode>
dump_vec: eval
# The number of samples in each batch
#batch_size: ${DEFAULT:eval_batch_size}
batch_size: 1
# The file type text or record
#file_type: record
file_type: text
reader_batch: False
# only exectute evaluation once
eval_once: True
#######################
# Dataset Configure #
#######################
# The name of the dataset to load
dataset_name: ${DEFAULT:dataset_name}
# The name of the train/test split
dataset_split_name: validation
# The glob pattern for data path, `file_pattern' must contain only one "%s"
# which is the placeholder for split name (such as 'train', 'validation')
file_pattern: ${DEFAULT:file_pattern}
# The number of input sample for evaluation
num_samples: ${DEFAULT:num_samples_eval}
# The number of parallel readers that read data from the dataset
num_readers: 2
# The number of threads used to create the batches
num_preprocessing_threads: 1
# Number of epochs from dataset source
num_epochs_input: 1
# The name of the architecture to evaluate
model_name: ${DEFAULT:model_name}
# The dimensions of net input vectors, it is just used by svm dataset
# which of input are sparse tensors now
num_in_dimension: ${DEFAULT:num_in_dimension}
# The dimensions of net output vector, it will be num of classes in image classify task
num_out_dimension: ${DEFAULT:num_out_dimension}
# Directory where the results are saved to
eval_dir: ${Train:train_dir}/checkpoint_1
PaddleST/Research/KDD2020-P3AC/datasets/poi_qac_personalized/__init__.py
0 → 100644
浏览文件 @
8e4eebfc
PaddleST/Research/KDD2020-P3AC/datasets/poi_qac_personalized/qac_personalized.py
0 → 100644
浏览文件 @
8e4eebfc
此差异已折叠。
点击以展开。
PaddleST/Research/KDD2020-P3AC/docs/framework.png
0 → 100644
浏览文件 @
8e4eebfc
1.2 MB
PaddleST/Research/KDD2020-P3AC/nets/poi_qac_personalized/__init__.py
0 → 100644
浏览文件 @
8e4eebfc
PaddleST/Research/KDD2020-P3AC/nets/poi_qac_personalized/qac_personalized.py
0 → 100644
浏览文件 @
8e4eebfc
此差异已折叠。
点击以展开。
PaddleST/Research/KDD2020-P3AC/test/__init__.py
0 → 100644
浏览文件 @
8e4eebfc
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}