@@ -273,7 +273,7 @@ or refer to `example/librispeech/run_test.sh`.
## Hyper-parameters Tuning
The hyper-parameters $\alpha$ (coefficient for language model scorer) and $\beta$ (coefficient for word count scorer) for the [*CTC beam search decoder*](https://arxiv.org/abs/1408.2873) often have a significant impact on the decoder's performance. It would be better to re-tune them on a validation set when the acoustic model is renewed.
The hyper-parameters $\alpha$ (language model weight) and $\beta$ (word insertion weight) for the [*CTC beam search decoder*](https://arxiv.org/abs/1408.2873) often have a significant impact on the decoder's performance. It would be better to re-tune them on the validation set when the acoustic model is renewed.
`tools/tune.py` performs a 2-D grid search over the hyper-parameter $\alpha$ and $\beta$. You must provide the range of $\alpha$ and $\beta$, as well as the number of their attempts.
...
...
@@ -283,12 +283,12 @@ The hyper-parameters $\alpha$ (coefficient for language model scorer) and $\beta
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
python tools/tune.py \
--trainer_count 8 \
--alpha_from 0.1 \
--alpha_to 0.36 \
--num_alphas 14 \
--beta_from 0.05 \
--beta_to 1.0 \
--num_betas 20
--alpha_from 1.0 \
--alpha_to 3.2 \
--num_alphas 45 \
--beta_from 0.1 \
--beta_to 0.45 \
--num_betas 8
```
- Tuning with CPU:
...
...
@@ -296,15 +296,23 @@ The hyper-parameters $\alpha$ (coefficient for language model scorer) and $\beta
```bash
python tools/tune.py --use_gpu False
```
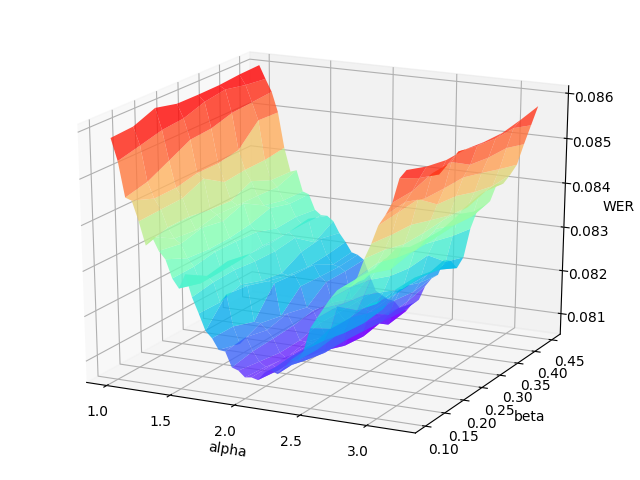
The grid search will print the WER (word error rate) or CER (character error rate) at each point in the hyper-parameters space, and draw the error surface optionally. A proper hyper-parameters range should include the global minima of the error surface for WER/CER, as illustrated in the following figure.
After tuning, you can reset $\alpha$ and $\beta$ in the inference and evaluation modules to see if they really help improve the ASR performance.
<br/>An example error surface for tuning on the dev-clean set of LibriSpeech
</p>
Usually, as the figure shows, the variation of language model weight ($\alpha$) significantly affect the performance of CTC beam search decoder. And a better procedure is to first tune on serveral data batches (the number can be specified) to find out the proper range of hyper-parameters, then change to the whole validation set to carray out an accurate tuning.
After tuning, you can reset $\alpha$ and $\beta$ in the inference and evaluation modules to see if they really help improve the ASR performance. For more help
{kind=link}