
add inference doc (#5404)
* add inference doc * fix reprod log * fix test inference * add predict into reprod * fix readme * add py serving doc * fix tipc test * fix * fix
Showing
{kind=link}
{kind=link}
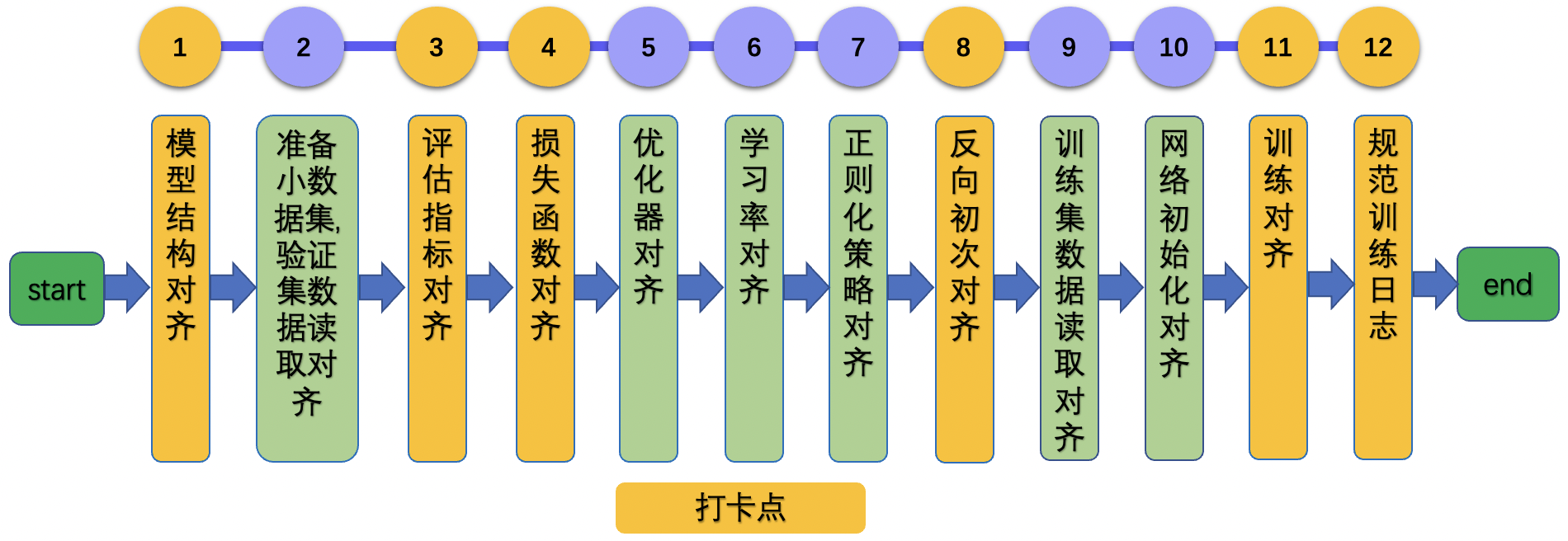
| W: | H:
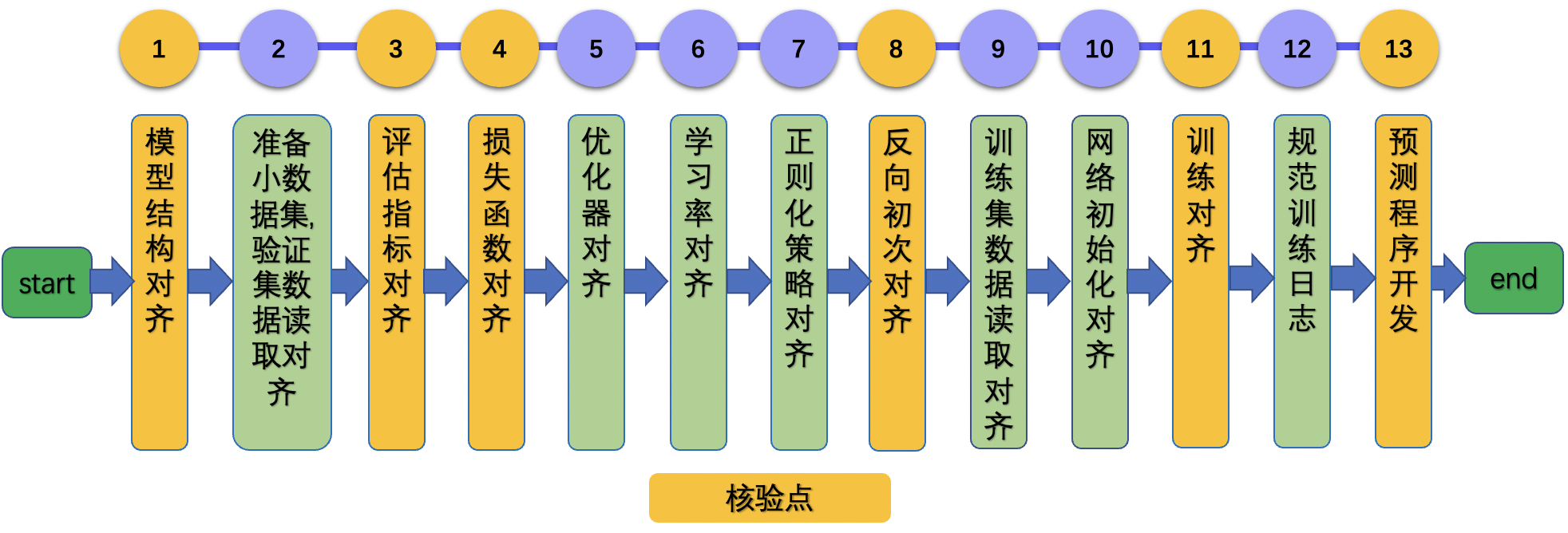
| W: | H:
{kind=link}

608.7 KB
{kind=link}

330.9 KB
文件已移动
* add inference doc * fix reprod log * fix test inference * add predict into reprod * fix readme * add py serving doc * fix tipc test * fix * fix
| W: | H:
| W: | H:
608.7 KB
330.9 KB