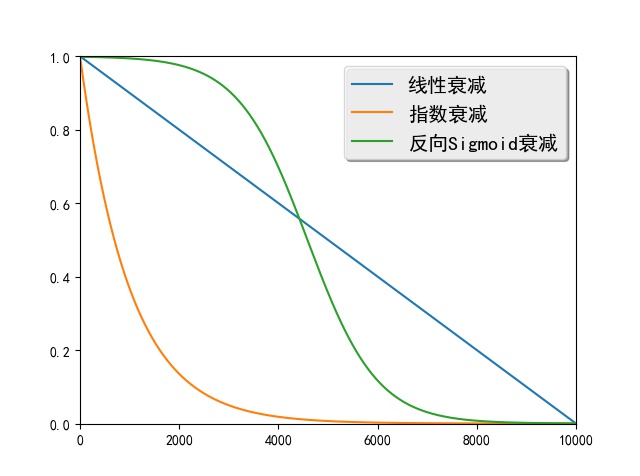
[1] Bengio S, Vinyals O, Jaitly N, et al. [Scheduled sampling for sequence prediction with recurrent neural networks](http://papers.nips.cc/paper/5956-scheduled-sampling-for-sequence-prediction-with-recurrent-neural-networks)//Advances in Neural Information Processing Systems. 2015: 1171-1179.
{kind=link}
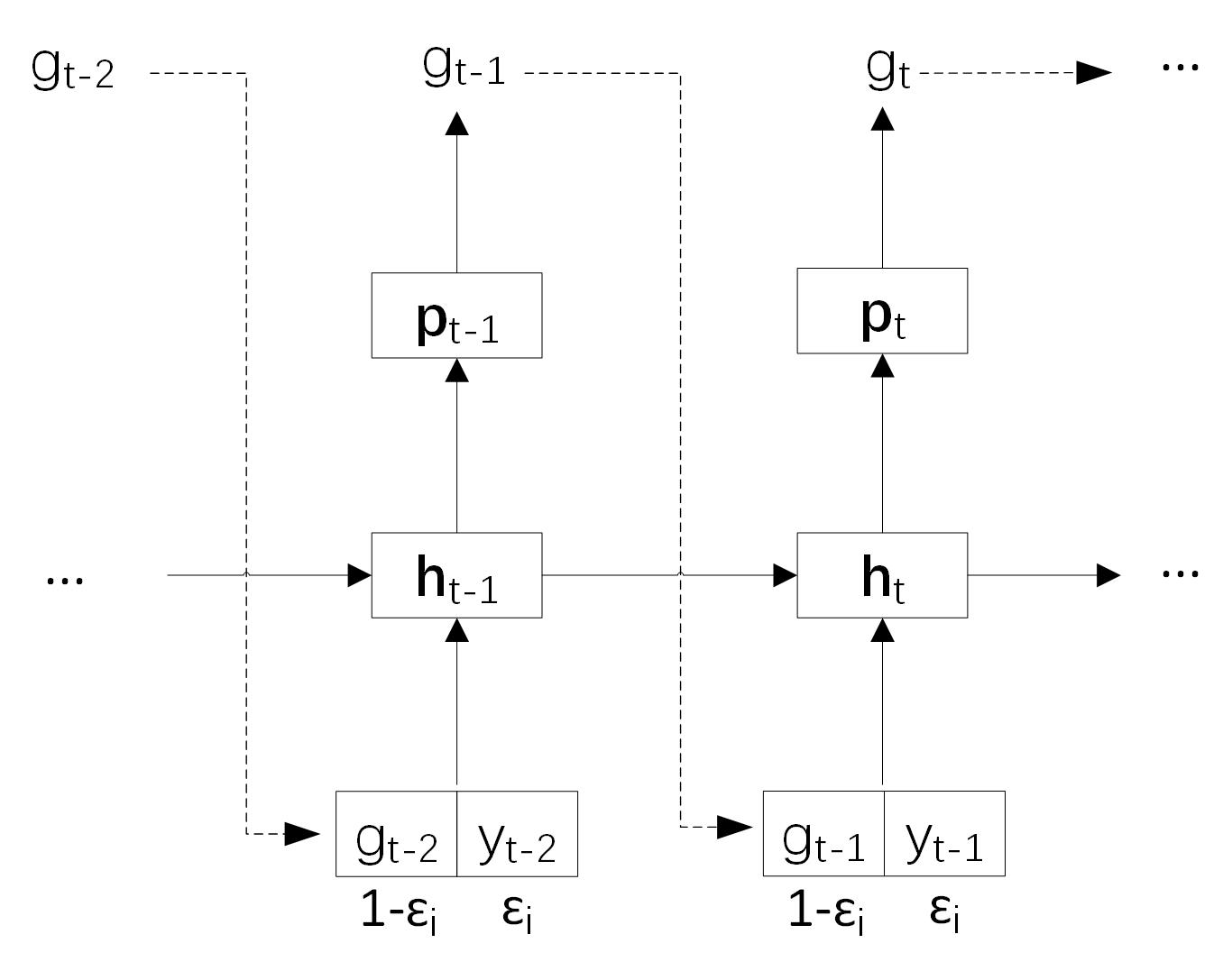
{kind=link}