Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
7c2e0190
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
7c2e0190
编写于
12月 17, 2020
作者:
Z
Zeyu Chen
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/models
into develop
上级
60d5b7a0
6bed7a6b
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
216 addition
and
5 deletion
+216
-5
PaddleNLP/docs/data.md
PaddleNLP/docs/data.md
+215
-0
PaddleNLP/examples/dialogue/plato-2/README.md
PaddleNLP/examples/dialogue/plato-2/README.md
+1
-5
PaddleNLP/examples/dialogue/plato-2/imgs/eval_cn.png
PaddleNLP/examples/dialogue/plato-2/imgs/eval_cn.png
+0
-0
PaddleNLP/examples/dialogue/plato-2/imgs/eval_en.png
PaddleNLP/examples/dialogue/plato-2/imgs/eval_en.png
+0
-0
未找到文件。
PaddleNLP/docs/data.md
0 → 100644
浏览文件 @
7c2e0190
# paddlenlp.data
该模块提供了在NLP任务中构建有效的数据pipeline的一些常用API。
## API汇总
| API | 简介 |
| ------------------------------- | :----------------------------------------- |
|
`paddlenlp.data.Stack`
| 堆叠N个具有相同shape的输入数据来构建一个batch |
|
`paddlenlp.data.Pad`
| 堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
|
`paddlenlp.data.Tuple`
| 将多个batchify函数包装在一起 |
|
`paddlenlp.data.SamplerHelper`
| 构建用于
`Dataloader`
的可迭代sampler |
|
`paddlenlp.data.Vocab`
| 用于文本token和ID之间的映射 |
|
`paddlenlp.data.JiebaTokenizer`
| Jieba分词 |
## API使用方法
以上API都是用来辅助构建
`DataLoader`
,
`DataLoader`
比较重要的三个初始化参数是
`dataset`
、
`batch_sampler`
和
`collate_fn`
。
`paddlenlp.data.Vocab`
和
`paddlenlp.data.JiebaTokenizer`
用在构建
`dataset`
时处理文本token到ID的映射。
`paddlenlp.data.SamplerHelper`
用于构建可迭代的
`batch_sampler`
。
`paddlenlp.data.Stack`
、
`paddlenlp.data.Pad`
和
`paddlenlp.data.Tuple`
用于构建生成mini-batch的
`collate_fn`
函数。
### 构建`dataset`
#### `paddlenlp.data.Vocab`
`paddlenlp.data.Vocab`
词表类,集合了一系列文本token与ids之间映射的一系列方法,支持从文件、字典、json等一系方式构建词表。
```
python
from
paddlenlp.data
import
Vocab
# 从文件构建
vocab1
=
Vocab
.
load_vocabulary
(
vocab_file_path
)
# 从字典构建
# dic = {'unk':0, 'pad':1, 'bos':2, 'eos':3, ...}
vocab2
=
Vocab
.
from_dict
(
dic
)
# 从json构建,一般是已构建好的Vocab对象先保存为json_str或json文件后再进行恢复
# json_str方式
json_str
=
vocab1
.
to_json
()
vocab3
=
Vocab
.
from_json
(
json_str
)
# json文件方式
vocab1
.
to_json
(
json_file_path
)
vocab4
=
Vocab
.
from_json
(
json_file_path
)
```
#### `paddlenlp.data.JiebaTokenizer`
`paddlenlp.data.JiebaTokenizer`
初始化需传入
`paddlenlp.data.Vocab`
类,包含
`cut`
分词方法和将句子转换为ids的
`encode`
方法。
```
python
from
paddlenlp.data
import
Vocab
,
JiebaTokenizer
# 词表文件路径,运行示例程序可先下载词表文件
# wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
vocab_file_path
=
'./senta_word_dict.txt'
# 构建词表
vocab
=
Vocab
.
load_vocabulary
(
vocab_file_path
,
unk_token
=
'[UNK]'
,
pad_token
=
'[PAD]'
)
tokenizer
=
JiebaTokenizer
(
vocab
)
tokens
=
tokenizer
.
cut
(
'我爱你中国'
)
# ['我爱你', '中国']
ids
=
tokenizer
.
encode
(
'我爱你中国'
)
# [1170578, 575565]
```
### 构建`batch_sampler`
#### `paddlenlp.data.SamplerHelper`
`paddlenlp.data.SamplerHelper`
的作用是构建用于
`DataLoader`
的可迭代采样器,它包含
`shuffle`
、
`sort`
、
`batch`
、
`shard`
等一系列方法,方便用户灵活使用。
```
python
from
paddlenlp.data
import
SamplerHelper
from
paddle.io
import
Dataset
class
MyDataset
(
Dataset
):
def
__init__
(
self
):
super
(
MyDataset
,
self
).
__init__
()
self
.
data
=
[
[[
1
,
2
,
3
,
4
],
[
1
]],
[[
5
,
6
,
7
],
[
0
]],
[[
8
,
9
],
[
1
]],
]
def
__getitem__
(
self
,
index
):
data
=
self
.
data
[
index
][
0
]
label
=
self
.
data
[
index
][
1
]
return
data
,
label
def
__len__
(
self
):
return
len
(
self
.
data
)
dataset
=
MyDataset
()
# SamplerHelper返回的是数据索引的可迭代对象,产生的迭代的索引为:[0, 1, 2]
sampler
=
SamplerHelper
(
dataset
)
# shuffle()的作用是随机打乱索引顺序,产生的迭代的索引为:[0, 2, 1]
sampler
=
sampler
.
shuffle
()
# sort()的作用是按照指定key为排序方式并在buffer_size大小个样本中排序
# 示例中以样本第一个字段的长度进行升序排序,产生的迭代的索引为:[2, 0, 1]
key
=
(
lambda
x
,
data_source
:
len
(
data_source
[
x
][
0
]))
sampler
=
sampler
.
sort
(
key
=
key
,
buffer_size
=
2
)
# batch()的作用是按照batch_size组建mini-batch,产生的迭代的索引为:[[2, 0], [1]]
sampler
=
sampler
.
batch
(
batch_size
=
2
)
# shard()的作用是为多卡训练切分数据集,当前卡产生的迭代的索引为:[[2, 0]]
sampler
=
sampler
.
shard
(
num_replicas
=
2
)
```
### 构建`collate_fn`
#### `paddlenlp.data.Stack`
`paddlenlp.data.Stack`
用来组建batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。
```
python
from
paddlenlp.data
import
Stack
a
=
[
1
,
2
,
3
,
4
]
b
=
[
3
,
4
,
5
,
6
]
c
=
[
5
,
6
,
7
,
8
]
result
=
Stack
()([
a
,
b
,
c
])
"""
[[1, 2, 3, 4],
[3, 4, 5, 6],
[5, 6, 7, 8]]
"""
```
#### `paddlenlp.data.Pad`
`paddlenlp.data.Pad`
用来组建batch,它的输入长度不同,它首先会将输入数据全部padding到最大长度,然后再堆叠组成batch数据输出。
```
python
from
paddlenlp.data
import
Pad
a
=
[
1
,
2
,
3
,
4
]
b
=
[
5
,
6
,
7
]
c
=
[
8
,
9
]
result
=
Pad
(
pad_val
=
0
)([
a
,
b
,
c
])
"""
[[1, 2, 3, 4],
[5, 6, 7, 0],
[8, 9, 0, 0]]
"""
```
#### `paddlenlp.data.Tuple`
`paddlenlp.data.Tuple`
会将多个组batch的函数包装在一起。
```
python
from
paddlenlp.data
import
Stack
,
Pad
,
Tuple
data
=
[
[[
1
,
2
,
3
,
4
],
[
1
]],
[[
5
,
6
,
7
],
[
0
]],
[[
8
,
9
],
[
1
]],
]
batchify_fn
=
Tuple
(
Pad
(
pad_val
=
0
),
Stack
())
ids
,
label
=
batchify_fn
(
data
)
"""
ids:
[[1, 2, 3, 4],
[5, 6, 7, 0],
[8, 9, 0, 0]]
label: [[1], [0], [1]]
"""
```
### 综合示例
```
python
from
paddlenlp.data
import
Vocab
,
JiebaTokenizer
,
Stack
,
Pad
,
Tuple
,
SamplerHelper
from
paddlenlp.datasets
import
ChnSentiCorp
from
paddlenlp.datasets
import
MapDatasetWrapper
from
paddle.io
import
DataLoader
# 词表文件路径,运行示例程序可先下载词表文件
# wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
vocab_file_path
=
'./senta_word_dict.txt'
# 构建词表
vocab
=
Vocab
.
load_vocabulary
(
vocab_file_path
,
unk_token
=
'[UNK]'
,
pad_token
=
'[PAD]'
)
# 初始化分词器
tokenizer
=
JiebaTokenizer
(
vocab
)
def
convert_example
(
example
):
text
,
label
=
example
ids
=
tokenizer
.
encode
(
text
)
label
=
[
label
]
return
ids
,
label
dataset
=
ChnSentiCorp
(
'train'
)
dataset
=
MapDatasetWrapper
(
dataset
).
apply
(
convert_example
,
lazy
=
True
)
pad_id
=
vocab
.
token_to_idx
[
vocab
.
pad_token
]
batchify_fn
=
Tuple
(
Pad
(
axis
=
0
,
pad_val
=
pad_id
),
# ids
Stack
(
dtype
=
'int64'
)
# label
)
batch_sampler
=
SamplerHelper
(
dataset
).
shuffle
().
batch
(
batch_size
=
16
)
data_loader
=
DataLoader
(
dataset
,
batch_sampler
=
batch_sampler
,
collate_fn
=
batchify_fn
,
return_list
=
True
)
# 测试数据集
for
batch
in
data_loader
:
ids
,
label
=
batch
print
(
ids
.
shape
,
label
.
shape
)
print
(
ids
)
print
(
label
)
break
```
PaddleNLP/examples/dialogue/plato-2/README.md
浏览文件 @
7c2e0190
...
...
@@ -6,14 +6,10 @@
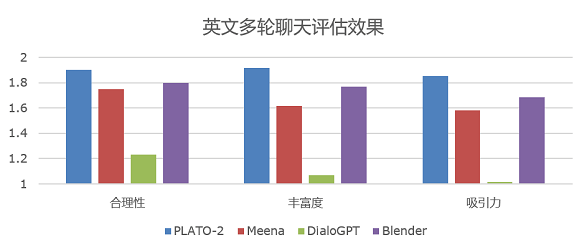
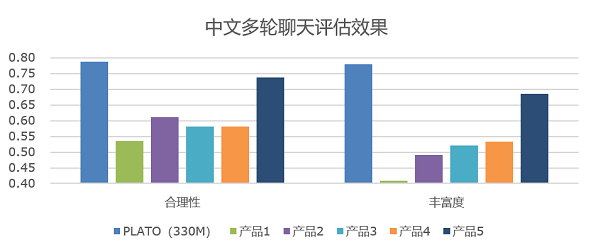
为了能够简易地构建一个高质量的开放域聊天机器人,本项目在Paddle2.0上实现了PLATO-2的预测模型,并基于终端实现了简单的人机交互。用户可以通过下载预训练模型快速构建一个开放域聊天机器人。
PLATO-2的网络结构
及评估结果
见下图:
PLATO-2的网络结构见下图:
<p
align=
"center"
><img
src=
"./imgs/network.png"
hspace=
"10"
/></p>
<p
align=
"center"
><img
src=
"./imgs/eval_en.png"
hspace=
"10"
/></p>
<p
align=
"center"
><img
src=
"./imgs/eval_cn.png"
hspace=
"10"
/></p>
PLATO-2的训练过程及其他细节详见
[
Knover
](
https://github.com/PaddlePaddle/Knover
)
## 快速开始
...
...
PaddleNLP/examples/dialogue/plato-2/imgs/eval_cn.png
已删除
100644 → 0
浏览文件 @
60d5b7a0
8.7 KB
PaddleNLP/examples/dialogue/plato-2/imgs/eval_en.png
已删除
100644 → 0
浏览文件 @
60d5b7a0
6.8 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}