@@ -39,6 +39,8 @@ You can test if distributed training works on a single node before deploying to
***NOTE: for best performance, we recommend using multi-process mode, see No.3. And together with fp16.***
***NOTE: for nccl2 distributed mode, you must ensure each node train same number of samples, or set skip_unbalanced_data to 1 to do sync training.***
1. simply run `python dist_train.py` to start local training with default configuratioins.
2. for pserver mode, run `bash run_ps_mode.sh` to start 2 pservers and 2 trainers, these 2 trainers
will use GPU 0 and 1 to simulate 2 workers.
...
...
@@ -90,4 +92,19 @@ The default resnet50 distributed training config is based on this paper: https:/
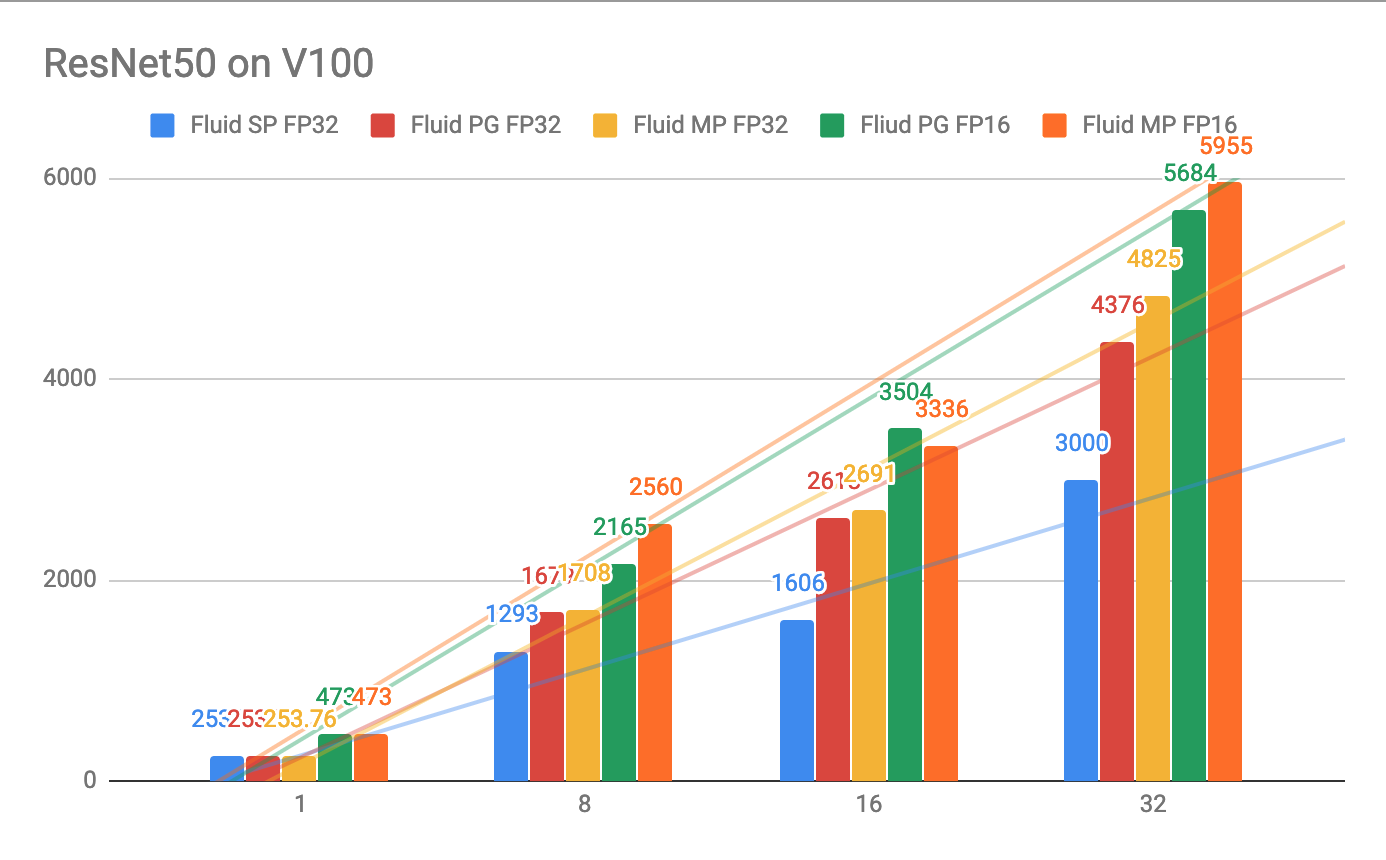
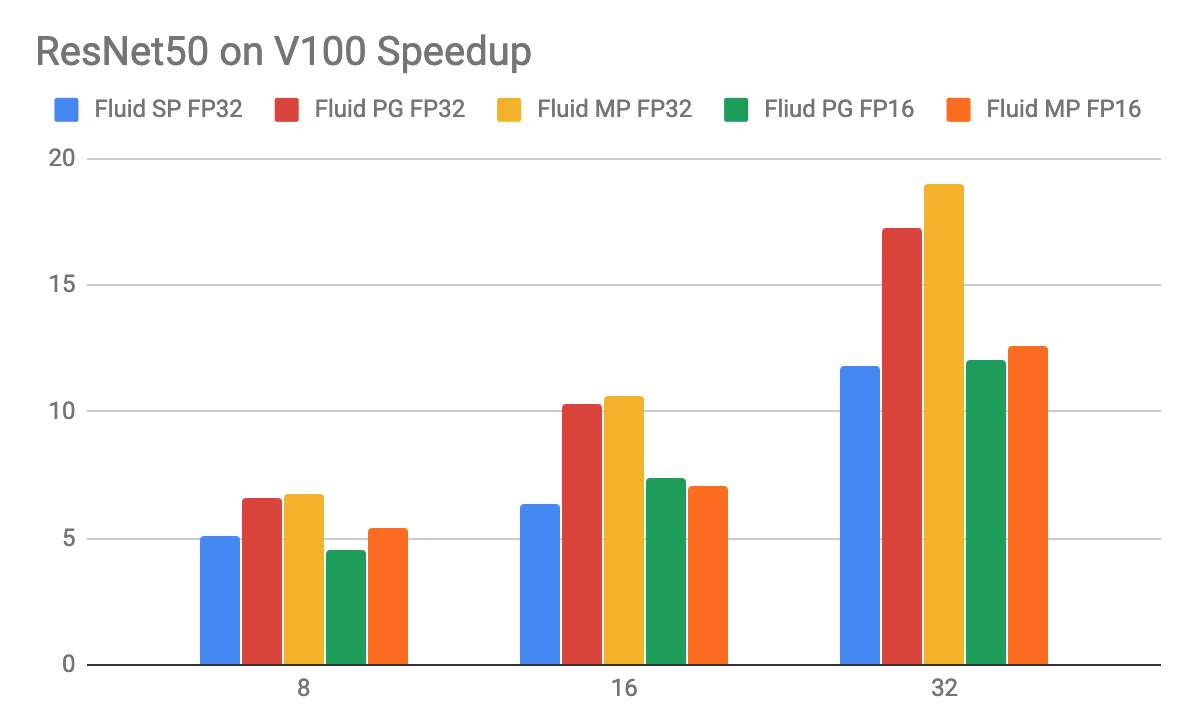
### Performance
TBD
The below figure shows fluid distributed training performances. We did these on a 4-node V100 GPU cluster,
each has 8 V100 GPU card, with total of 32 GPUs. All modes can reach the "state of the art (choose loss scale carefully when using fp16 mode)" of ResNet50 model with imagenet dataset. The Y axis in the figure shows
the images/s while the X-axis shows the number of GPUs.
{kind=link}
{kind=link}