Merge pull request #477 from wanghaoshuang/fix_text_classification
fix data reader error of text classification.
Showing
deep_fm/README.md
0 → 100644
deep_fm/data/download.sh
0 → 100755
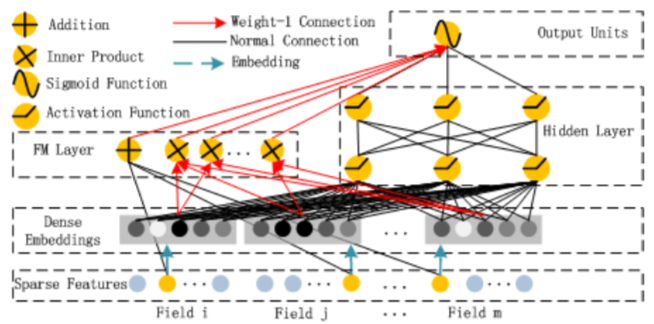
deep_fm/images/DeepFM.png
0 → 100644
{kind=link}
143.1 KB
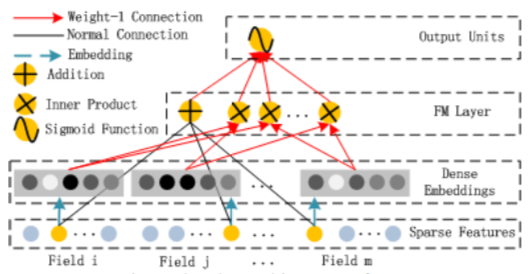
deep_fm/images/FM.png
0 → 100644
{kind=link}
89.7 KB
deep_fm/infer.py
0 → 100755
deep_fm/network_conf.py
0 → 100644
deep_fm/preprocess.py
0 → 100755
deep_fm/reader.py
0 → 100644
deep_fm/train.py
0 → 100755