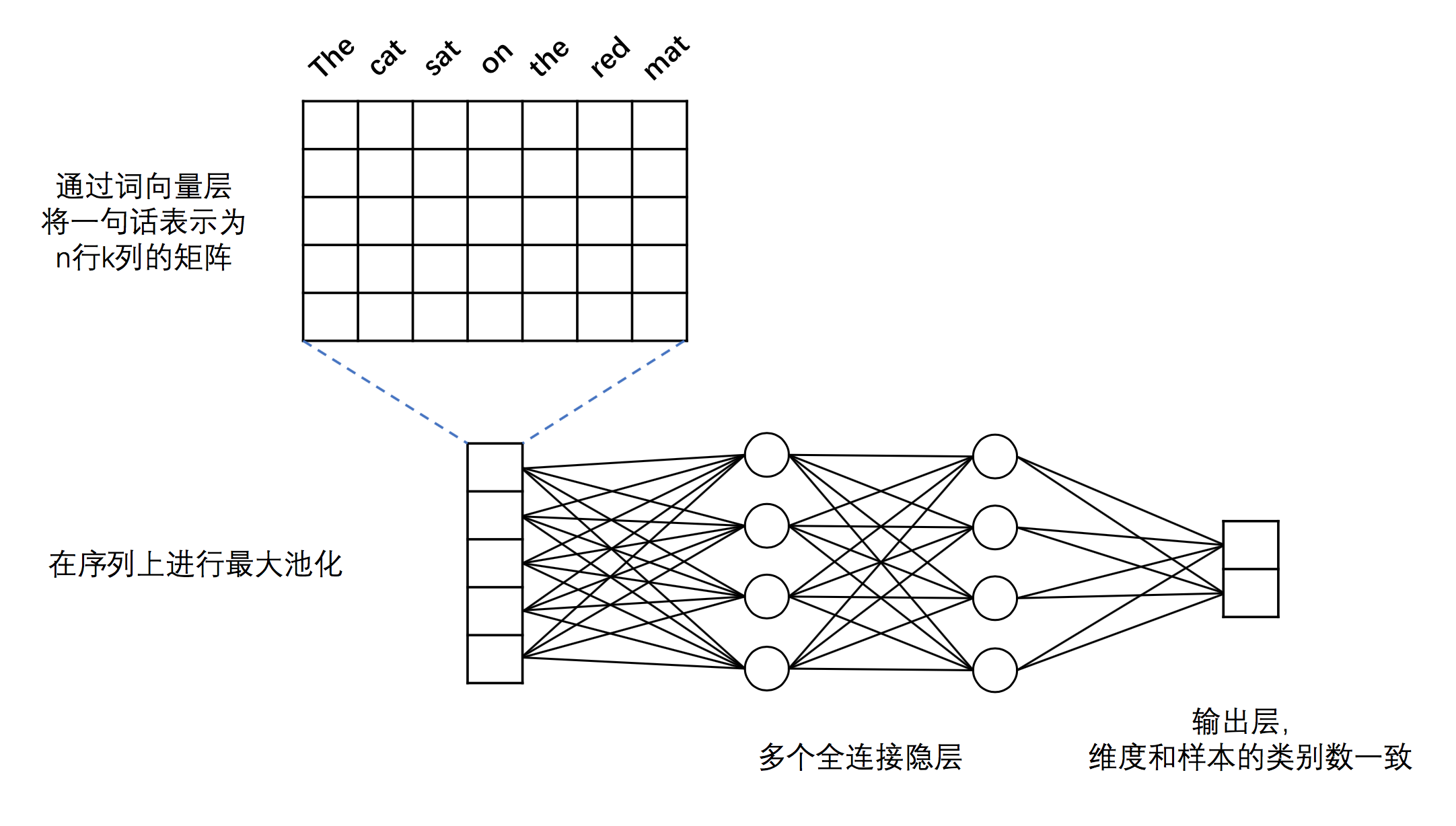
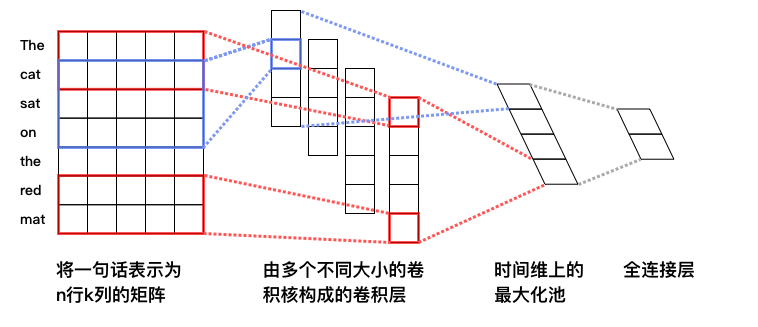
-**词向量层**:与DNN中词向量层的作用一样,将英文单词转化为固定维度的向量,利用向量之间的距离来表示词之间的语义相关程度。如图2中所示,将得到的词向量定义为行向量,再将语料中所有的单词产生的行向量拼接在一起组成矩阵。假设词向量维度为5,语料“The cat sat on the read mat”包含7个单词,那么得到的矩阵维度为7*5。关于词向量的更多信息请参考PaddleBook中的[词向量](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec)一节。
{kind=link}
{kind=link}