add similarity_net dygraph (#4289)
* Update README.md (#4267) * test=develop (#4269) * 3d use new api (#4275) * PointNet++ and PointRCNN use new API * Update Readme of Dygraph BERT (#4277) Fix some typos. * Update run_classifier_multi_gpu.sh (#4279) remove the CUDA_VISIBLE_DEVICES * Update README.md (#4280) * add similarity_net dygraph Co-authored-by: Npkpk <xiyzhouang@gmail.com> Co-authored-by: NKaipeng Deng <dengkaipeng@baidu.com>
Showing
dygraph/similarity_net/.run_ce.sh
0 → 100644
dygraph/similarity_net/README.md
0 → 100644
dygraph/similarity_net/_ce.py
0 → 100644
dygraph/similarity_net/config.py
0 → 100644
dygraph/similarity_net/mmdnn.py
0 → 100644
此差异已折叠。
此差异已折叠。
dygraph/similarity_net/reader.py
0 → 100644
dygraph/similarity_net/run.sh
0 → 100644
此差异已折叠。
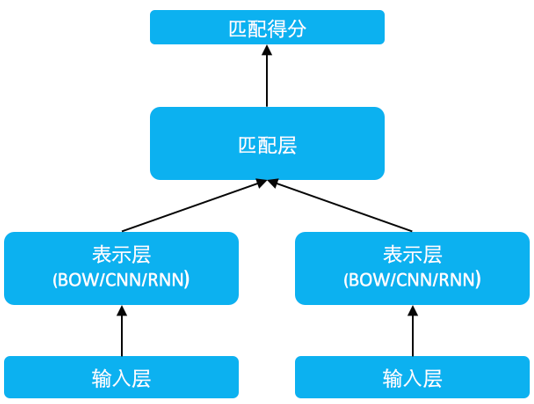
dygraph/similarity_net/struct.jpg
0 → 100644
{kind=link}
37.2 KB
dygraph/similarity_net/utils.py
0 → 100644
此差异已折叠。