Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
6e44fd66
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
6e44fd66
编写于
11月 24, 2017
作者:
W
wangmeng28
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Implement DeepFM for CTR prediction
上级
5d4166ab
变更
8
隐藏空白更改
内联
并排
Showing
8 changed file
with
158 addition
and
35 deletion
+158
-35
deep_fm/README.md
deep_fm/README.md
+83
-3
deep_fm/data/download.sh
deep_fm/data/download.sh
+4
-1
deep_fm/images/DeepFM.png
deep_fm/images/DeepFM.png
+0
-0
deep_fm/images/FM.png
deep_fm/images/FM.png
+0
-0
deep_fm/network_conf.py
deep_fm/network_conf.py
+4
-1
deep_fm/preprocess.py
deep_fm/preprocess.py
+40
-22
deep_fm/reader.py
deep_fm/reader.py
+3
-0
deep_fm/train.py
deep_fm/train.py
+24
-8
未找到文件。
deep_fm/README.md
浏览文件 @
6e44fd66
# Deep
FM 基于深度因子分解机的点击率预测模型
# Deep
Factorization Machines (DeepFM) for Click-Through Rate prediction
## 简介
## Introduction
This model implements the DeepFM proposed in the following paper:
[TBD]
```
text
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li and Xiuqiang He. DeepFM:
A Factorization-Machine based Neural Network for CTR Prediction.
Proceedings of the Twenty-Sixth International Joint Conference on
Artificial Intelligence (IJCAI-17), 2017
```
The DeepFm combines factorization machines and deep neural networks to model
both low order and high order feature interactions. For details of the
factorization machines, please refer to the paper
[
factorization
machines
](
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
)
## Dataset
This example uses Criteo dataset which was used for the
[
Display Advertising
Challenge
](
https://www.kaggle.com/c/criteo-display-ad-challenge/
)
hosted by Kaggle.
Each row is the features for an ad display and the first column is a label
indicating whether this ad has been clicked or not. There are 39 features in
total. 13 features take integer values and the other 26 features are
categorical features. For the test dataset, the labels are omitted.
Download dataset:
```
bash
cd
data
&&
./download.sh
&&
cd
..
```
## Model
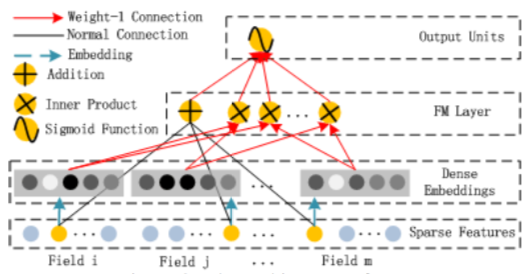
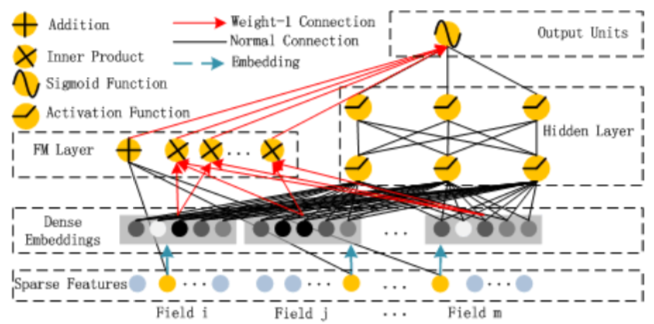
The DeepFM model is composed of the factorization machine layer (FM) and deep
neural networks (DNN). All the input features are feeded to both FM and DNN.
The output from FM and DNN are combined to form the final output. The embedding
layer for sparse features in the DNN shares the parameters with the latent
vectors (factors) of the FM layer.
The factorization machine layer in PaddlePaddle computes the second order
interactions. The following code example combines the factorization machine
layer and fully connected layer to form the full version of factorization
machine:
```
python
def
fm_layer
(
input
,
factor_size
):
first_order
=
paddle
.
layer
.
fc
(
input
=
input
,
size
=
1
,
act
=
paddle
.
activation
.
Linear
())
second_order
=
paddle
.
layer
.
factorization_machine
(
input
=
input
,
factor_size
=
factor_size
)
fm
=
paddle
.
layer
.
addto
(
input
=
[
first_order
,
second_order
],
act
=
paddle
.
activation
.
Linear
(),
ias_attr
=
False
)
return
fm
```
## Data preparation
To preprocess the raw dataset, the integer features are clipped then min-max
normalized to [0, 1] and the categorical features are one-hot encoded. The raw
training dataset are splited such that 90% are used for training and the other
10% are used for validation during training.
```
bash
python preprocess.py
--datadir
./data/raw
--outdir
./data
```
## Train
The command line options for training can be listed by
`python train.py -h`
.
To train the model:
```
bash
python train.py
\
--train_data_path
data/train.txt
\
--test_data_path
data/valid.txt
\
2>&1 | train.log
```
## Infer
The command line options for infering can be listed by
`python infer.py -h`
.
To make inference for the test dataset:
```
bash
python infer.py
\
--model_gz_path
models/model-pass-9-batch-10000.tar.gz
\
--data_path
data/test.txt
\
--prediction_output_path
./predict.txt
```
deep_fm/data/download.sh
浏览文件 @
6e44fd66
#!/bin/bash
#!/bin/bash
wget https://s3-eu-west-1.amazonaws.com/criteo-labs/dac.tar.gz
wget
--no-check-certificate
https://s3-eu-west-1.amazonaws.com/criteo-labs/dac.tar.gz
tar
zxf dac.tar.gz
tar
zxf dac.tar.gz
rm
-f
dac.tar.gz
rm
-f
dac.tar.gz
mkdir
raw
mv
./
*
.txt raw/
deep_fm/images/DeepFM.png
已删除
100644 → 0
浏览文件 @
5d4166ab
143.1 KB
deep_fm/images/FM.png
已删除
100644 → 0
浏览文件 @
5d4166ab
89.7 KB
deep_fm/network_conf.py
浏览文件 @
6e44fd66
...
@@ -14,7 +14,7 @@ def fm_layer(input, factor_size, fm_param_attr):
...
@@ -14,7 +14,7 @@ def fm_layer(input, factor_size, fm_param_attr):
param_attr
=
fm_param_attr
)
param_attr
=
fm_param_attr
)
out
=
paddle
.
layer
.
addto
(
out
=
paddle
.
layer
.
addto
(
input
=
[
first_order
,
second_order
],
input
=
[
first_order
,
second_order
],
act
=
paddle
.
activation
.
Sigmoid
(),
act
=
paddle
.
activation
.
Linear
(),
bias_attr
=
False
)
bias_attr
=
False
)
return
out
return
out
...
@@ -68,6 +68,9 @@ def DeepFM(factor_size, infer=False):
...
@@ -68,6 +68,9 @@ def DeepFM(factor_size, infer=False):
name
=
"label"
,
type
=
paddle
.
data_type
.
dense_vector
(
1
))
name
=
"label"
,
type
=
paddle
.
data_type
.
dense_vector
(
1
))
cost
=
paddle
.
layer
.
multi_binary_label_cross_entropy_cost
(
cost
=
paddle
.
layer
.
multi_binary_label_cross_entropy_cost
(
input
=
predict
,
label
=
label
)
input
=
predict
,
label
=
label
)
paddle
.
evaluator
.
classification_error
(
name
=
"classification_error"
,
input
=
predict
,
label
=
label
)
paddle
.
evaluator
.
auc
(
name
=
"auc"
,
input
=
predict
,
label
=
label
)
return
cost
return
cost
else
:
else
:
return
predict
return
predict
deep_fm/preprocess.py
浏览文件 @
6e44fd66
...
@@ -5,12 +5,17 @@ Challenge (https://www.kaggle.com/c/criteo-display-ad-challenge).
...
@@ -5,12 +5,17 @@ Challenge (https://www.kaggle.com/c/criteo-display-ad-challenge).
import
os
import
os
import
sys
import
sys
import
click
import
click
import
random
import
collections
import
collections
# There are 13 integer features and 26 categorical features
# There are 13 integer features and 26 categorical features
continous_features
=
range
(
1
,
14
)
continous_features
=
range
(
1
,
14
)
categorial_features
=
range
(
14
,
40
)
categorial_features
=
range
(
14
,
40
)
# Clip integer features. The clip point for each integer feature
# is derived from the 95% quantile of the total values in each feature
continous_clip
=
[
20
,
600
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
class
CategoryDictGenerator
:
class
CategoryDictGenerator
:
"""
"""
...
@@ -67,12 +72,14 @@ class ContinuousFeatureGenerator:
...
@@ -67,12 +72,14 @@ class ContinuousFeatureGenerator:
val
=
features
[
continous_features
[
i
]]
val
=
features
[
continous_features
[
i
]]
if
val
!=
''
:
if
val
!=
''
:
val
=
int
(
val
)
val
=
int
(
val
)
if
val
>
continous_clip
[
i
]:
val
=
continous_clip
[
i
]
self
.
min
[
i
]
=
min
(
self
.
min
[
i
],
val
)
self
.
min
[
i
]
=
min
(
self
.
min
[
i
],
val
)
self
.
max
[
i
]
=
max
(
self
.
max
[
i
],
val
)
self
.
max
[
i
]
=
max
(
self
.
max
[
i
],
val
)
def
gen
(
self
,
idx
,
val
):
def
gen
(
self
,
idx
,
val
):
if
val
==
''
:
if
val
==
''
:
return
0
return
0
.0
val
=
float
(
val
)
val
=
float
(
val
)
return
(
val
-
self
.
min
[
idx
])
/
(
self
.
max
[
idx
]
-
self
.
min
[
idx
])
return
(
val
-
self
.
min
[
idx
])
/
(
self
.
max
[
idx
]
-
self
.
min
[
idx
])
...
@@ -101,26 +108,36 @@ def preprocess(datadir, outdir):
...
@@ -101,26 +108,36 @@ def preprocess(datadir, outdir):
offset
=
categorial_feature_offset
[
i
-
1
]
+
dict_sizes
[
i
-
1
]
offset
=
categorial_feature_offset
[
i
-
1
]
+
dict_sizes
[
i
-
1
]
categorial_feature_offset
.
append
(
offset
)
categorial_feature_offset
.
append
(
offset
)
with
open
(
os
.
path
.
join
(
outdir
,
'train.txt'
),
'w'
)
as
out
:
random
.
seed
(
0
)
with
open
(
os
.
path
.
join
(
datadir
,
'train.txt'
),
'r'
)
as
f
:
for
line
in
f
:
# 90% of the data are used for training, and 10% of the data are used
features
=
line
.
rstrip
(
'
\n
'
).
split
(
'
\t
'
)
# for validation.
with
open
(
os
.
path
.
join
(
outdir
,
'train.txt'
),
'w'
)
as
out_train
:
continous_vals
=
[]
with
open
(
os
.
path
.
join
(
outdir
,
'valid.txt'
),
'w'
)
as
out_valid
:
for
i
in
range
(
0
,
len
(
continous_features
)):
with
open
(
os
.
path
.
join
(
datadir
,
'train.txt'
),
'r'
)
as
f
:
val
=
dists
.
gen
(
i
,
features
[
continous_features
[
i
]])
for
line
in
f
:
continous_vals
.
append
(
str
(
val
))
features
=
line
.
rstrip
(
'
\n
'
).
split
(
'
\t
'
)
categorial_vals
=
[]
for
i
in
range
(
0
,
len
(
categorial_features
)):
continous_vals
=
[]
val
=
dicts
.
gen
(
i
,
features
[
categorial_features
[
for
i
in
range
(
0
,
len
(
continous_features
)):
i
]])
+
categorial_feature_offset
[
i
]
val
=
dists
.
gen
(
i
,
features
[
continous_features
[
i
]])
categorial_vals
.
append
(
str
(
val
))
continous_vals
.
append
(
"{0:.6f}"
.
format
(
val
).
rstrip
(
'0'
).
rstrip
(
'.'
))
continous_vals
=
','
.
join
(
continous_vals
)
categorial_vals
=
[]
categorial_vals
=
','
.
join
(
categorial_vals
)
for
i
in
range
(
0
,
len
(
categorial_features
)):
label
=
features
[
0
]
val
=
dicts
.
gen
(
i
,
features
[
categorial_features
[
out
.
write
(
'
\t
'
.
join
([
continous_vals
,
categorial_vals
,
label
])
+
i
]])
+
categorial_feature_offset
[
i
]
'
\n
'
)
categorial_vals
.
append
(
str
(
val
))
continous_vals
=
','
.
join
(
continous_vals
)
categorial_vals
=
','
.
join
(
categorial_vals
)
label
=
features
[
0
]
if
random
.
randint
(
0
,
9999
)
%
10
!=
0
:
out_train
.
write
(
'
\t
'
.
join
(
[
continous_vals
,
categorial_vals
,
label
])
+
'
\n
'
)
else
:
out_valid
.
write
(
'
\t
'
.
join
(
[
continous_vals
,
categorial_vals
,
label
])
+
'
\n
'
)
with
open
(
os
.
path
.
join
(
outdir
,
'test.txt'
),
'w'
)
as
out
:
with
open
(
os
.
path
.
join
(
outdir
,
'test.txt'
),
'w'
)
as
out
:
with
open
(
os
.
path
.
join
(
datadir
,
'test.txt'
),
'r'
)
as
f
:
with
open
(
os
.
path
.
join
(
datadir
,
'test.txt'
),
'r'
)
as
f
:
...
@@ -130,7 +147,8 @@ def preprocess(datadir, outdir):
...
@@ -130,7 +147,8 @@ def preprocess(datadir, outdir):
continous_vals
=
[]
continous_vals
=
[]
for
i
in
range
(
0
,
len
(
continous_features
)):
for
i
in
range
(
0
,
len
(
continous_features
)):
val
=
dists
.
gen
(
i
,
features
[
continous_features
[
i
]
-
1
])
val
=
dists
.
gen
(
i
,
features
[
continous_features
[
i
]
-
1
])
continous_vals
.
append
(
str
(
val
))
continous_vals
.
append
(
"{0:.6f}"
.
format
(
val
).
rstrip
(
'0'
).
rstrip
(
'.'
))
categorial_vals
=
[]
categorial_vals
=
[]
for
i
in
range
(
0
,
len
(
categorial_features
)):
for
i
in
range
(
0
,
len
(
categorial_features
)):
val
=
dicts
.
gen
(
i
,
val
=
dicts
.
gen
(
i
,
...
...
deep_fm/reader.py
浏览文件 @
6e44fd66
...
@@ -18,6 +18,9 @@ class Dataset:
...
@@ -18,6 +18,9 @@ class Dataset:
def
train
(
self
,
path
):
def
train
(
self
,
path
):
return
self
.
_reader_creator
(
path
,
False
)
return
self
.
_reader_creator
(
path
,
False
)
def
test
(
self
,
path
):
return
self
.
_reader_creator
(
path
,
False
)
def
infer
(
self
,
path
):
def
infer
(
self
,
path
):
return
self
.
_reader_creator
(
path
,
True
)
return
self
.
_reader_creator
(
path
,
True
)
...
...
deep_fm/train.py
浏览文件 @
6e44fd66
...
@@ -20,11 +20,16 @@ def parse_args():
...
@@ -20,11 +20,16 @@ def parse_args():
type
=
str
,
type
=
str
,
required
=
True
,
required
=
True
,
help
=
"path of training dataset"
)
help
=
"path of training dataset"
)
parser
.
add_argument
(
'--test_data_path'
,
type
=
str
,
required
=
True
,
help
=
"path of testing dataset"
)
parser
.
add_argument
(
parser
.
add_argument
(
'--batch_size'
,
'--batch_size'
,
type
=
int
,
type
=
int
,
default
=
1000
0
,
default
=
1000
,
help
=
"size of mini-batch (default:1000
0
)"
)
help
=
"size of mini-batch (default:1000)"
)
parser
.
add_argument
(
parser
.
add_argument
(
'--num_passes'
,
'--num_passes'
,
type
=
int
,
type
=
int
,
...
@@ -52,7 +57,7 @@ def train():
...
@@ -52,7 +57,7 @@ def train():
paddle
.
init
(
use_gpu
=
False
,
trainer_count
=
1
)
paddle
.
init
(
use_gpu
=
False
,
trainer_count
=
1
)
optimizer
=
paddle
.
optimizer
.
Adam
(
learning_rate
=
1e-
3
)
optimizer
=
paddle
.
optimizer
.
Adam
(
learning_rate
=
1e-
4
)
model
=
DeepFM
(
args
.
factor_size
)
model
=
DeepFM
(
args
.
factor_size
)
...
@@ -66,11 +71,22 @@ def train():
...
@@ -66,11 +71,22 @@ def train():
def
__event_handler__
(
event
):
def
__event_handler__
(
event
):
if
isinstance
(
event
,
paddle
.
event
.
EndIteration
):
if
isinstance
(
event
,
paddle
.
event
.
EndIteration
):
num_samples
=
event
.
batch_id
*
args
.
batch_size
num_samples
=
event
.
batch_id
*
args
.
batch_size
if
event
.
batch_id
%
10
==
0
:
if
event
.
batch_id
%
100
==
0
:
logger
.
warning
(
"Pass %d, Batch %d, Samples %d, Cost %f"
%
(
logger
.
warning
(
"Pass %d, Batch %d, Samples %d, Cost %f, %s"
%
event
.
pass_id
,
event
.
batch_id
,
num_samples
,
event
.
cost
))
(
event
.
pass_id
,
event
.
batch_id
,
num_samples
,
event
.
cost
,
event
.
metrics
))
if
event
.
batch_id
%
10000
==
0
:
if
args
.
test_data_path
:
result
=
trainer
.
test
(
reader
=
paddle
.
batch
(
dataset
.
test
(
args
.
test_data_path
),
batch_size
=
args
.
batch_size
),
feeding
=
reader
.
feeding
)
logger
.
warning
(
"Test %d-%d, Cost %f, %s"
%
(
event
.
pass_id
,
event
.
batch_id
,
result
.
cost
,
result
.
metrics
))
if
event
.
batch_id
%
1000
==
0
:
path
=
"{}/model-pass-{}-batch-{}.tar.gz"
.
format
(
path
=
"{}/model-pass-{}-batch-{}.tar.gz"
.
format
(
args
.
model_output_dir
,
event
.
pass_id
,
event
.
batch_id
)
args
.
model_output_dir
,
event
.
pass_id
,
event
.
batch_id
)
with
gzip
.
open
(
path
,
'w'
)
as
f
:
with
gzip
.
open
(
path
,
'w'
)
as
f
:
...
@@ -80,7 +96,7 @@ def train():
...
@@ -80,7 +96,7 @@ def train():
reader
=
paddle
.
batch
(
reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
paddle
.
reader
.
shuffle
(
dataset
.
train
(
args
.
train_data_path
),
dataset
.
train
(
args
.
train_data_path
),
buf_size
=
args
.
batch_size
*
100
),
buf_size
=
args
.
batch_size
*
100
00
),
batch_size
=
args
.
batch_size
),
batch_size
=
args
.
batch_size
),
feeding
=
reader
.
feeding
,
feeding
=
reader
.
feeding
,
event_handler
=
__event_handler__
,
event_handler
=
__event_handler__
,
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}