Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
6b882d42
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
6b882d42
编写于
3月 24, 2020
作者:
C
ceci3
提交者:
GitHub
3月 24, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
delete cycle_gan (#4476)
上级
90fcad46
变更
18
隐藏空白更改
内联
并排
Showing
18 changed file
with
4 addition
and
1145 deletion
+4
-1145
PaddleCV/gan/cycle_gan/.run_ce.sh
PaddleCV/gan/cycle_gan/.run_ce.sh
+0
-8
PaddleCV/gan/cycle_gan/README.md
PaddleCV/gan/cycle_gan/README.md
+0
-92
PaddleCV/gan/cycle_gan/_ce.py
PaddleCV/gan/cycle_gan/_ce.py
+0
-68
PaddleCV/gan/cycle_gan/data/horse2zebra/trainA.txt
PaddleCV/gan/cycle_gan/data/horse2zebra/trainA.txt
+0
-1
PaddleCV/gan/cycle_gan/data/horse2zebra/trainA/n02381460_1001.jpg
.../gan/cycle_gan/data/horse2zebra/trainA/n02381460_1001.jpg
+0
-0
PaddleCV/gan/cycle_gan/data/horse2zebra/trainB.txt
PaddleCV/gan/cycle_gan/data/horse2zebra/trainB.txt
+0
-1
PaddleCV/gan/cycle_gan/data/horse2zebra/trainB/n02391049_10007.jpg
...gan/cycle_gan/data/horse2zebra/trainB/n02391049_10007.jpg
+0
-0
PaddleCV/gan/cycle_gan/data_reader.py
PaddleCV/gan/cycle_gan/data_reader.py
+0
-87
PaddleCV/gan/cycle_gan/images/A2B.jpg
PaddleCV/gan/cycle_gan/images/A2B.jpg
+0
-0
PaddleCV/gan/cycle_gan/images/B2A.jpg
PaddleCV/gan/cycle_gan/images/B2A.jpg
+0
-0
PaddleCV/gan/cycle_gan/images/cycleGAN_loss.png
PaddleCV/gan/cycle_gan/images/cycleGAN_loss.png
+0
-0
PaddleCV/gan/cycle_gan/infer.py
PaddleCV/gan/cycle_gan/infer.py
+0
-80
PaddleCV/gan/cycle_gan/layers.py
PaddleCV/gan/cycle_gan/layers.py
+0
-175
PaddleCV/gan/cycle_gan/model.py
PaddleCV/gan/cycle_gan/model.py
+0
-66
PaddleCV/gan/cycle_gan/train.py
PaddleCV/gan/cycle_gan/train.py
+0
-306
PaddleCV/gan/cycle_gan/trainer.py
PaddleCV/gan/cycle_gan/trainer.py
+0
-175
PaddleCV/gan/cycle_gan/utility.py
PaddleCV/gan/cycle_gan/utility.py
+0
-86
PaddleCV/gan/infer.py
PaddleCV/gan/infer.py
+4
-0
未找到文件。
PaddleCV/gan/cycle_gan/.run_ce.sh
已删除
100755 → 0
浏览文件 @
90fcad46
#!/bin/bash
# This file is only used for continuous evaluation.
export
FLAGS_cudnn_deterministic
=
True
export
ce_mode
=
1
CUDA_VISIBLE_DEVICES
=
0 python train.py
--batch_size
=
1
--epoch
=
10
--run_ce
=
True
--use_gpu
=
True | python _ce.py
PaddleCV/gan/cycle_gan/README.md
已删除
100644 → 0
浏览文件 @
90fcad46
运行本目录下的程序示例需要使用PaddlePaddle develop最新版本。如果您的PaddlePaddle安装版本低于此要求,请按照
[
安装文档
](
http://www.paddlepaddle.org/docs/develop/documentation/zh/build_and_install/pip_install_cn.html
)
中的说明更新PaddlePaddle安装版本。
## 代码结构
```
├── data_reader.py # 读取、处理数据。
├── layers.py # 封装定义基础的layers。
├── model.py # 定义基础生成网络和判别网络。
├── trainer.py # 构造loss和训练网络。
├── train.py # 训练脚本。
└── infer.py # 预测脚本。
```
## 简介
TODO
## 数据准备
本教程使用 horse2zebra 数据集 来进行模型的训练测试工作,该数据集是用关键字'wild horse'和'zebra'过滤
[
ImageNet
](
http://www.image-net.org/
)
数据集并下载得到的。
horse2zebra训练集包含1069张野马图片,1336张斑马图片。测试集包含121张野马图片和141张斑马图片。
数据下载处理完毕后,并组织为以下路径结构:
```
data
|-- horse2zebra
| |-- testA
| |-- testA.txt
| |-- testB
| |-- testB.txt
| |-- trainA
| |-- trainA.txt
| |-- trainB
| `-- trainB.txt
```
以上数据文件中,
`data`
文件夹需要放在训练脚本
`train.py`
同级目录下。
`testA`
为存放野马测试图片的文件夹,
`testB`
为存放斑马测试图片的文件夹,
`testA.txt`
和
`testB.txt`
分别为野马和斑马测试图片路径列表文件,格式如下:
```
testA/n02381460_9243.jpg
testA/n02381460_9244.jpg
testA/n02381460_9245.jpg
```
训练数据组织方式与测试数据相同。
## 模型训练与预测
### 训练
在GPU单卡上训练:
```
env CUDA_VISIBLE_DEVICES=0 python train.py
```
执行
`python train.py --help`
可查看更多使用方式和参数详细说明。
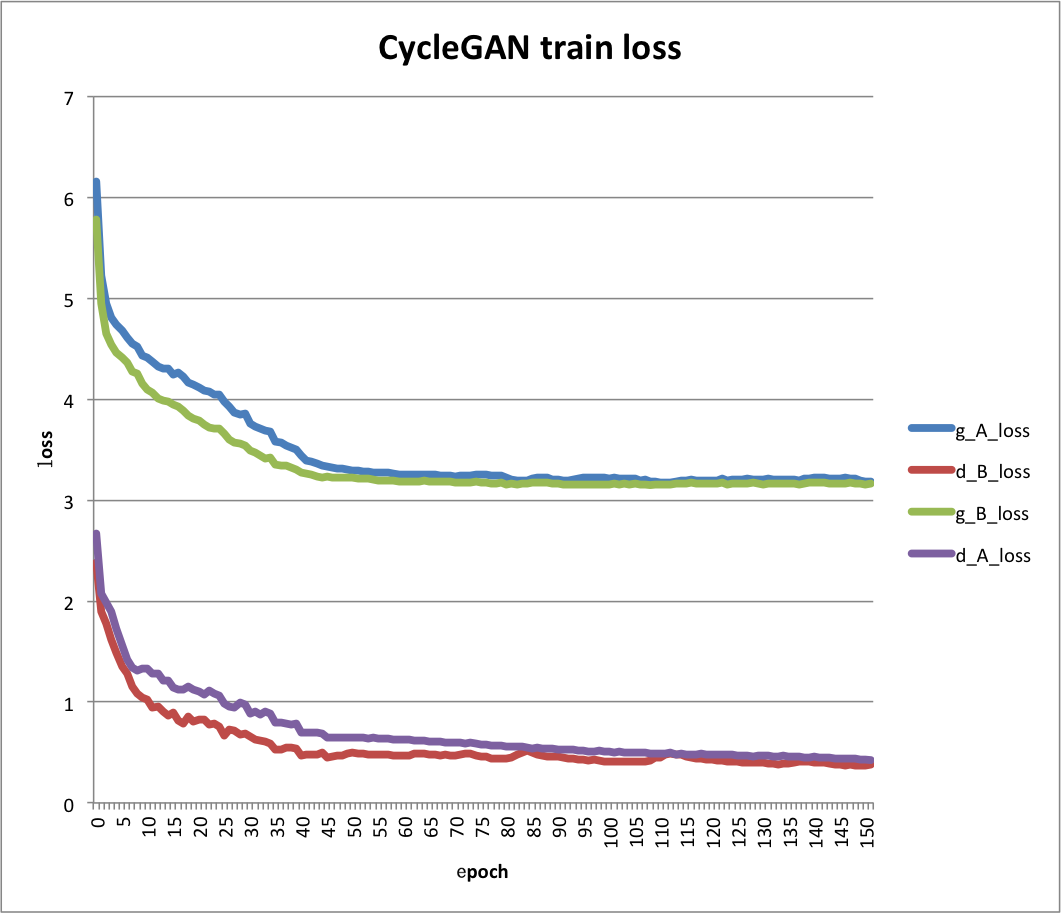
图1为训练152轮的训练损失示意图,其中横坐标轴为训练轮数,纵轴为在训练集上的损失。其中,'g_A_loss','g_B_loss','d_A_loss'和'd_B_loss'分别为生成器A、生成器B、判别器A和判别器B的训练损失。
<p
align=
"center"
>
<img
src=
"images/cycleGAN_loss.png"
width=
"620"
hspace=
'10'
/>
<br/>
<strong>
图 1
</strong>
</p>
### 预测
执行以下命令读取多张图片进行预测:
```
env CUDA_VISIBLE_DEVICES=0 python infer.py \
--init_model="output/checkpoints/1" --input="./data/horse2zebra/trainA/*" \
--input_style A --output="./output"
```
训练150轮的模型预测效果如图2和图3所示:
<p
align=
"center"
>
<img
src=
"images/A2B.jpg"
width=
"620"
hspace=
'10'
/>
<br/>
<strong>
图 2
</strong>
</p>
<p
align=
"center"
>
<img
src=
"images/B2A.jpg"
width=
"620"
hspace=
'10'
/>
<br/>
<strong>
图 3
</strong>
</p>
>在本文示例中,均可通过修改`CUDA_VISIBLE_DEVICES`改变使用的显卡号。
PaddleCV/gan/cycle_gan/_ce.py
已删除
100644 → 0
浏览文件 @
90fcad46
####this file is only used for continuous evaluation test!
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
os
import
sys
sys
.
path
.
append
(
os
.
environ
[
'ceroot'
])
from
kpi
import
CostKpi
,
DurationKpi
,
AccKpi
#### NOTE kpi.py should shared in models in some way!!!!
d_train_cost_kpi
=
CostKpi
(
'd_train_cost'
,
0.05
,
0
,
actived
=
True
,
desc
=
'train cost of discriminator'
)
g_train_cost_kpi
=
CostKpi
(
'g_train_cost'
,
0.05
,
0
,
actived
=
True
,
desc
=
'train cost of generator'
)
train_speed_kpi
=
DurationKpi
(
'duration'
,
0.05
,
0
,
actived
=
True
,
unit_repr
=
'second'
,
desc
=
'train time used in one GPU card'
)
tracking_kpis
=
[
d_train_cost_kpi
,
g_train_cost_kpi
,
train_speed_kpi
]
def
parse_log
(
log
):
'''
This method should be implemented by model developers.
The suggestion:
each line in the log should be key, value, for example:
"
train_cost
\t
1.0
test_cost
\t
1.0
train_cost
\t
1.0
train_cost
\t
1.0
train_acc
\t
1.2
"
'''
for
line
in
log
.
split
(
'
\n
'
):
fs
=
line
.
strip
().
split
(
','
)
print
(
fs
)
if
len
(
fs
)
==
3
and
fs
[
0
]
==
'kpis'
:
kpi_name
=
fs
[
1
]
kpi_value
=
float
(
fs
[
2
])
print
(
"kpi {}={}"
.
format
(
kpi_name
,
kpi_value
))
yield
kpi_name
,
kpi_value
def
log_to_ce
(
log
):
kpi_tracker
=
{}
for
kpi
in
tracking_kpis
:
kpi_tracker
[
kpi
.
name
]
=
kpi
for
(
kpi_name
,
kpi_value
)
in
parse_log
(
log
):
print
(
kpi_name
,
kpi_value
)
kpi_tracker
[
kpi_name
].
add_record
(
kpi_value
)
kpi_tracker
[
kpi_name
].
persist
()
if
__name__
==
'__main__'
:
log
=
sys
.
stdin
.
read
()
# print("*****")
# print(log)
# print("****")
log_to_ce
(
log
)
PaddleCV/gan/cycle_gan/data/horse2zebra/trainA.txt
已删除
100644 → 0
浏览文件 @
90fcad46
trainA/n02381460_1001.jpg
PaddleCV/gan/cycle_gan/data/horse2zebra/trainA/n02381460_1001.jpg
已删除
100755 → 0
浏览文件 @
90fcad46
36.8 KB
PaddleCV/gan/cycle_gan/data/horse2zebra/trainB.txt
已删除
100644 → 0
浏览文件 @
90fcad46
trainB/n02391049_10007.jpg
PaddleCV/gan/cycle_gan/data/horse2zebra/trainB/n02391049_10007.jpg
已删除
100755 → 0
浏览文件 @
90fcad46
19.2 KB
PaddleCV/gan/cycle_gan/data_reader.py
已删除
100644 → 0
浏览文件 @
90fcad46
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
os
from
PIL
import
Image
import
numpy
as
np
A_LIST_FILE
=
"./data/horse2zebra/trainA.txt"
B_LIST_FILE
=
"./data/horse2zebra/trainB.txt"
A_TEST_LIST_FILE
=
"./data/horse2zebra/testA.txt"
B_TEST_LIST_FILE
=
"./data/horse2zebra/testB.txt"
IMAGES_ROOT
=
"./data/horse2zebra/"
def
image_shape
():
return
[
3
,
256
,
256
]
def
max_images_num
():
return
1335
def
reader_creater
(
list_file
,
cycle
=
True
,
shuffle
=
True
,
return_name
=
False
):
images
=
[
IMAGES_ROOT
+
line
for
line
in
open
(
list_file
,
'r'
).
readlines
()]
def
reader
():
while
True
:
if
shuffle
:
np
.
random
.
shuffle
(
images
)
for
file
in
images
:
file
=
file
.
strip
(
"
\n\r\t
"
)
image
=
Image
.
open
(
file
)
image
=
image
.
resize
((
256
,
256
))
image
=
np
.
array
(
image
)
/
127.5
-
1
if
len
(
image
.
shape
)
!=
3
:
continue
image
=
image
[:,
:,
0
:
3
].
astype
(
"float32"
)
image
=
image
.
transpose
([
2
,
0
,
1
])
if
return_name
:
yield
image
[
np
.
newaxis
,
:],
os
.
path
.
basename
(
file
)
else
:
yield
image
if
not
cycle
:
break
return
reader
def
a_reader
(
shuffle
=
True
):
"""
Reader of images with A style for training.
"""
return
reader_creater
(
A_LIST_FILE
,
shuffle
=
shuffle
)
def
b_reader
(
shuffle
=
True
):
"""
Reader of images with B style for training.
"""
return
reader_creater
(
B_LIST_FILE
,
shuffle
=
shuffle
)
def
a_test_reader
():
"""
Reader of images with A style for test.
"""
return
reader_creater
(
A_TEST_LIST_FILE
,
cycle
=
False
,
return_name
=
True
)
def
b_test_reader
():
"""
Reader of images with B style for test.
"""
return
reader_creater
(
B_TEST_LIST_FILE
,
cycle
=
False
,
return_name
=
True
)
PaddleCV/gan/cycle_gan/images/A2B.jpg
已删除
100644 → 0
浏览文件 @
90fcad46
216.2 KB
PaddleCV/gan/cycle_gan/images/B2A.jpg
已删除
100644 → 0
浏览文件 @
90fcad46
200.8 KB
PaddleCV/gan/cycle_gan/images/cycleGAN_loss.png
已删除
100644 → 0
浏览文件 @
90fcad46
77.3 KB
PaddleCV/gan/cycle_gan/infer.py
已删除
100644 → 0
浏览文件 @
90fcad46
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
argparse
import
functools
import
os
from
PIL
import
Image
import
paddle.fluid
as
fluid
import
paddle
import
numpy
as
np
from
scipy.misc
import
imsave
from
model
import
build_generator_resnet_9blocks
,
build_gen_discriminator
import
glob
from
utility
import
add_arguments
,
print_arguments
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
# yapf: disable
add_arg
(
'input'
,
str
,
None
,
"The images to be infered."
)
add_arg
(
'output'
,
str
,
"./infer_result"
,
"The directory the infer result to be saved to."
)
add_arg
(
'init_model'
,
str
,
None
,
"The init model file of directory."
)
add_arg
(
'input_style'
,
str
,
"A"
,
"The style of the input, A or B"
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether to use GPU to train."
)
# yapf: enable
def
infer
(
args
):
data_shape
=
[
-
1
,
3
,
256
,
256
]
input
=
fluid
.
layers
.
data
(
name
=
'input'
,
shape
=
data_shape
,
dtype
=
'float32'
)
if
args
.
input_style
==
"A"
:
model_name
=
'g_a'
fake
=
build_generator_resnet_9blocks
(
input
,
name
=
"g_A"
)
elif
args
.
input_style
==
"B"
:
model_name
=
'g_b'
fake
=
build_generator_resnet_9blocks
(
input
,
name
=
"g_B"
)
else
:
raise
"Input with style [%s] is not supported."
%
args
.
input_style
# prepare environment
place
=
fluid
.
CPUPlace
()
if
args
.
use_gpu
:
place
=
fluid
.
CUDAPlace
(
0
)
exe
=
fluid
.
Executor
(
place
)
exe
.
run
(
fluid
.
default_startup_program
())
fluid
.
io
.
load_persistables
(
exe
,
args
.
init_model
+
"/"
+
model_name
)
if
not
os
.
path
.
exists
(
args
.
output
):
os
.
makedirs
(
args
.
output
)
for
file
in
glob
.
glob
(
args
.
input
):
image_name
=
os
.
path
.
basename
(
file
)
image
=
Image
.
open
(
file
)
image
=
image
.
resize
((
256
,
256
))
image
=
np
.
array
(
image
)
/
127.5
-
1
if
len
(
image
.
shape
)
!=
3
:
continue
data
=
image
.
transpose
([
2
,
0
,
1
])[
np
.
newaxis
,
:].
astype
(
"float32"
)
tensor
=
fluid
.
LoDTensor
()
tensor
.
set
(
data
,
place
)
fake_temp
=
exe
.
run
(
fetch_list
=
[
fake
.
name
],
feed
=
{
"input"
:
tensor
})
fake_temp
=
np
.
squeeze
(
fake_temp
[
0
]).
transpose
([
1
,
2
,
0
])
input_temp
=
np
.
squeeze
(
data
).
transpose
([
1
,
2
,
0
])
imsave
(
args
.
output
+
"/fake_"
+
image_name
,
(
(
fake_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
if
__name__
==
"__main__"
:
args
=
parser
.
parse_args
()
print_arguments
(
args
)
infer
(
args
)
PaddleCV/gan/cycle_gan/layers.py
已删除
100644 → 0
浏览文件 @
90fcad46
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
division
import
paddle.fluid
as
fluid
import
numpy
as
np
import
os
# cudnn is not better when batch size is 1.
use_cudnn_conv2d_transpose
=
False
use_cudnn_conv2d
=
True
use_layer_norm
=
True
def
cal_padding
(
img_size
,
stride
,
filter_size
,
dilation
=
1
):
"""Calculate padding size."""
valid_filter_size
=
dilation
*
(
filter_size
-
1
)
+
1
if
img_size
%
stride
==
0
:
out_size
=
max
(
filter_size
-
stride
,
0
)
else
:
out_size
=
max
(
filter_size
-
(
img_size
%
stride
),
0
)
return
out_size
//
2
,
out_size
-
out_size
//
2
def
instance_norm
(
input
,
name
=
None
):
# TODO(lvmengsi@baidu.com): Check the accuracy when using fluid.layers.layer_norm.
if
use_layer_norm
:
return
fluid
.
layers
.
layer_norm
(
input
,
begin_norm_axis
=
2
)
helper
=
fluid
.
layer_helper
.
LayerHelper
(
"instance_norm"
,
**
locals
())
dtype
=
helper
.
input_dtype
()
epsilon
=
1e-5
mean
=
fluid
.
layers
.
reduce_mean
(
input
,
dim
=
[
2
,
3
],
keep_dim
=
True
)
var
=
fluid
.
layers
.
reduce_mean
(
fluid
.
layers
.
square
(
input
-
mean
),
dim
=
[
2
,
3
],
keep_dim
=
True
)
if
name
is
not
None
:
scale_name
=
name
+
"_scale"
offset_name
=
name
+
"_offset"
scale_param
=
fluid
.
ParamAttr
(
name
=
scale_name
,
initializer
=
fluid
.
initializer
.
TruncatedNormal
(
1.0
,
0.02
),
trainable
=
True
)
offset_param
=
fluid
.
ParamAttr
(
name
=
offset_name
,
initializer
=
fluid
.
initializer
.
Constant
(
0.0
),
trainable
=
True
)
scale
=
helper
.
create_parameter
(
attr
=
scale_param
,
shape
=
input
.
shape
[
1
:
2
],
dtype
=
dtype
)
offset
=
helper
.
create_parameter
(
attr
=
offset_param
,
shape
=
input
.
shape
[
1
:
2
],
dtype
=
dtype
)
tmp
=
fluid
.
layers
.
elementwise_mul
(
x
=
(
input
-
mean
),
y
=
scale
,
axis
=
1
)
tmp
=
tmp
/
fluid
.
layers
.
sqrt
(
var
+
epsilon
)
tmp
=
fluid
.
layers
.
elementwise_add
(
tmp
,
offset
,
axis
=
1
)
return
tmp
def
conv2d
(
input
,
num_filters
=
64
,
filter_size
=
7
,
stride
=
1
,
stddev
=
0.02
,
padding
=
"VALID"
,
name
=
"conv2d"
,
norm
=
True
,
relu
=
True
,
relufactor
=
0.0
):
"""Wrapper for conv2d op to support VALID and SAME padding mode."""
need_crop
=
False
if
padding
==
"SAME"
:
top_padding
,
bottom_padding
=
cal_padding
(
input
.
shape
[
2
],
stride
,
filter_size
)
left_padding
,
right_padding
=
cal_padding
(
input
.
shape
[
2
],
stride
,
filter_size
)
height_padding
=
bottom_padding
width_padding
=
right_padding
if
top_padding
!=
bottom_padding
or
left_padding
!=
right_padding
:
height_padding
=
top_padding
+
stride
width_padding
=
left_padding
+
stride
need_crop
=
True
else
:
height_padding
=
0
width_padding
=
0
padding
=
[
height_padding
,
width_padding
]
param_attr
=
fluid
.
ParamAttr
(
name
=
name
+
"_w"
,
initializer
=
fluid
.
initializer
.
TruncatedNormal
(
scale
=
stddev
))
bias_attr
=
fluid
.
ParamAttr
(
name
=
name
+
"_b"
,
initializer
=
fluid
.
initializer
.
Constant
(
0.0
))
conv
=
fluid
.
layers
.
conv2d
(
input
,
num_filters
,
filter_size
,
name
=
name
,
stride
=
stride
,
padding
=
padding
,
use_cudnn
=
use_cudnn_conv2d
,
param_attr
=
param_attr
,
bias_attr
=
bias_attr
)
if
need_crop
:
conv
=
fluid
.
layers
.
crop
(
conv
,
shape
=
(
-
1
,
conv
.
shape
[
1
],
conv
.
shape
[
2
]
-
1
,
conv
.
shape
[
3
]
-
1
),
offsets
=
(
0
,
0
,
1
,
1
))
if
norm
:
conv
=
instance_norm
(
input
=
conv
,
name
=
name
+
"_norm"
)
if
relu
:
conv
=
fluid
.
layers
.
leaky_relu
(
conv
,
alpha
=
relufactor
)
return
conv
def
deconv2d
(
input
,
out_shape
,
num_filters
=
64
,
filter_size
=
7
,
stride
=
1
,
stddev
=
0.02
,
padding
=
"VALID"
,
name
=
"conv2d"
,
norm
=
True
,
relu
=
True
,
relufactor
=
0.0
):
"""Wrapper for deconv2d op to support VALID and SAME padding mode."""
need_crop
=
False
if
padding
==
"SAME"
:
top_padding
,
bottom_padding
=
cal_padding
(
out_shape
[
0
],
stride
,
filter_size
)
left_padding
,
right_padding
=
cal_padding
(
out_shape
[
1
],
stride
,
filter_size
)
height_padding
=
top_padding
width_padding
=
left_padding
if
top_padding
!=
bottom_padding
or
left_padding
!=
right_padding
:
need_crop
=
True
else
:
height_padding
=
0
width_padding
=
0
padding
=
[
height_padding
,
width_padding
]
param_attr
=
fluid
.
ParamAttr
(
name
=
name
+
"_w"
,
initializer
=
fluid
.
initializer
.
TruncatedNormal
(
scale
=
stddev
))
bias_attr
=
fluid
.
ParamAttr
(
name
=
name
+
"_b"
,
initializer
=
fluid
.
initializer
.
Constant
(
0.0
))
conv
=
fluid
.
layers
.
conv2d_transpose
(
input
,
num_filters
,
name
=
name
,
filter_size
=
filter_size
,
stride
=
stride
,
padding
=
padding
,
use_cudnn
=
use_cudnn_conv2d_transpose
,
param_attr
=
param_attr
,
bias_attr
=
bias_attr
)
if
need_crop
:
conv
=
fluid
.
layers
.
crop
(
conv
,
shape
=
(
-
1
,
conv
.
shape
[
1
],
conv
.
shape
[
2
]
-
1
,
conv
.
shape
[
3
]
-
1
),
offsets
=
(
0
,
0
,
0
,
0
))
if
norm
:
conv
=
instance_norm
(
input
=
conv
,
name
=
name
+
"_norm"
)
if
relu
:
conv
=
fluid
.
layers
.
leaky_relu
(
conv
,
alpha
=
relufactor
)
return
conv
PaddleCV/gan/cycle_gan/model.py
已删除
100644 → 0
浏览文件 @
90fcad46
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
layers
import
conv2d
,
deconv2d
import
paddle.fluid
as
fluid
def
build_resnet_block
(
inputres
,
dim
,
name
=
"resnet"
):
out_res
=
fluid
.
layers
.
pad2d
(
inputres
,
[
1
,
1
,
1
,
1
],
mode
=
"reflect"
)
out_res
=
conv2d
(
out_res
,
dim
,
3
,
1
,
0.02
,
"VALID"
,
name
+
"_c1"
)
out_res
=
fluid
.
layers
.
pad2d
(
out_res
,
[
1
,
1
,
1
,
1
],
mode
=
"reflect"
)
out_res
=
conv2d
(
out_res
,
dim
,
3
,
1
,
0.02
,
"VALID"
,
name
+
"_c2"
,
relu
=
False
)
return
fluid
.
layers
.
relu
(
out_res
+
inputres
)
def
build_generator_resnet_9blocks
(
inputgen
,
name
=
"generator"
):
'''The shape of input should be equal to the shape of output.'''
pad_input
=
fluid
.
layers
.
pad2d
(
inputgen
,
[
3
,
3
,
3
,
3
],
mode
=
"reflect"
)
o_c1
=
conv2d
(
pad_input
,
32
,
7
,
1
,
0.02
,
name
=
name
+
"_c1"
)
o_c2
=
conv2d
(
o_c1
,
64
,
3
,
2
,
0.02
,
"SAME"
,
name
+
"_c2"
)
o_c3
=
conv2d
(
o_c2
,
128
,
3
,
2
,
0.02
,
"SAME"
,
name
+
"_c3"
)
o_r1
=
build_resnet_block
(
o_c3
,
128
,
name
+
"_r1"
)
o_r2
=
build_resnet_block
(
o_r1
,
128
,
name
+
"_r2"
)
o_r3
=
build_resnet_block
(
o_r2
,
128
,
name
+
"_r3"
)
o_r4
=
build_resnet_block
(
o_r3
,
128
,
name
+
"_r4"
)
o_r5
=
build_resnet_block
(
o_r4
,
128
,
name
+
"_r5"
)
o_r6
=
build_resnet_block
(
o_r5
,
128
,
name
+
"_r6"
)
o_r7
=
build_resnet_block
(
o_r6
,
128
,
name
+
"_r7"
)
o_r8
=
build_resnet_block
(
o_r7
,
128
,
name
+
"_r8"
)
o_r9
=
build_resnet_block
(
o_r8
,
128
,
name
+
"_r9"
)
o_c4
=
deconv2d
(
o_r9
,
[
128
,
128
],
64
,
3
,
2
,
0.02
,
"SAME"
,
name
+
"_c4"
)
o_c5
=
deconv2d
(
o_c4
,
[
256
,
256
],
32
,
3
,
2
,
0.02
,
"SAME"
,
name
+
"_c5"
)
o_c6
=
conv2d
(
o_c5
,
3
,
7
,
1
,
0.02
,
"SAME"
,
name
+
"_c6"
,
relu
=
False
)
out_gen
=
fluid
.
layers
.
tanh
(
o_c6
,
name
+
"_t1"
)
return
out_gen
def
build_gen_discriminator
(
inputdisc
,
name
=
"discriminator"
):
o_c1
=
conv2d
(
inputdisc
,
64
,
4
,
2
,
0.02
,
"SAME"
,
name
+
"_c1"
,
norm
=
False
,
relufactor
=
0.2
)
o_c2
=
conv2d
(
o_c1
,
128
,
4
,
2
,
0.02
,
"SAME"
,
name
+
"_c2"
,
relufactor
=
0.2
)
o_c3
=
conv2d
(
o_c2
,
256
,
4
,
2
,
0.02
,
"SAME"
,
name
+
"_c3"
,
relufactor
=
0.2
)
o_c4
=
conv2d
(
o_c3
,
512
,
4
,
1
,
0.02
,
"SAME"
,
name
+
"_c4"
,
relufactor
=
0.2
)
o_c5
=
conv2d
(
o_c4
,
1
,
4
,
1
,
0.02
,
"SAME"
,
name
+
"_c5"
,
norm
=
False
,
relu
=
False
)
return
o_c5
PaddleCV/gan/cycle_gan/train.py
已删除
100644 → 0
浏览文件 @
90fcad46
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
os
def
set_paddle_flags
(
flags
):
for
key
,
value
in
flags
.
items
():
if
os
.
environ
.
get
(
key
,
None
)
is
None
:
os
.
environ
[
key
]
=
str
(
value
)
use_cudnn_deterministic
=
os
.
environ
.
get
(
'FLAGS_cudnn_deterministic'
,
None
)
if
use_cudnn_deterministic
:
use_cudnn_exhaustive_search
=
0
else
:
use_cudnn_exhaustive_search
=
1
# NOTE(paddle-dev): All of these flags should be
# set before `import paddle`. Otherwise, it would
# not take any effect.
set_paddle_flags
({
'FLAGS_cudnn_exhaustive_search'
:
use_cudnn_exhaustive_search
,
'FLAGS_conv_workspace_size_limit'
:
256
,
'FLAGS_eager_delete_tensor_gb'
:
0
,
# enable gc
# You can omit the following settings, because the default
# value of FLAGS_memory_fraction_of_eager_deletion is 1,
# and default value of FLAGS_fast_eager_deletion_mode is 1
'FLAGS_memory_fraction_of_eager_deletion'
:
1
,
'FLAGS_fast_eager_deletion_mode'
:
1
})
import
random
import
sys
import
paddle
import
argparse
import
functools
import
time
import
numpy
as
np
from
scipy.misc
import
imsave
import
paddle.fluid
as
fluid
import
paddle.fluid.profiler
as
profiler
import
data_reader
from
utility
import
add_arguments
,
print_arguments
,
ImagePool
from
trainer
import
GATrainer
,
GBTrainer
,
DATrainer
,
DBTrainer
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
# yapf: disable
add_arg
(
'batch_size'
,
int
,
1
,
"Minibatch size."
)
add_arg
(
'epoch'
,
int
,
2
,
"The number of epoched to be trained."
)
add_arg
(
'output'
,
str
,
"./output"
,
"The directory the model and the test result to be saved to."
)
add_arg
(
'init_model'
,
str
,
None
,
"The init model file of directory."
)
add_arg
(
'save_checkpoints'
,
bool
,
True
,
"Whether to save checkpoints."
)
add_arg
(
'run_test'
,
bool
,
True
,
"Whether to run test."
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether to use GPU to train."
)
add_arg
(
'profile'
,
bool
,
False
,
"Whether to profile."
)
# NOTE: args for profiler, used for benchmark
add_arg
(
'profiler_path'
,
str
,
'./profiler_cyclegan'
,
"the path of profiler output files. used for benchmark"
)
add_arg
(
'max_iter'
,
int
,
0
,
"the max batch nums to train. used for benchmark"
)
add_arg
(
'run_ce'
,
bool
,
False
,
"Whether to run for model ce."
)
# yapf: enable
def
train
(
args
):
max_images_num
=
data_reader
.
max_images_num
()
shuffle
=
True
if
args
.
run_ce
:
np
.
random
.
seed
(
10
)
fluid
.
default_startup_program
().
random_seed
=
90
max_images_num
=
1
shuffle
=
False
data_shape
=
[
-
1
]
+
data_reader
.
image_shape
()
input_A
=
fluid
.
layers
.
data
(
name
=
'input_A'
,
shape
=
data_shape
,
dtype
=
'float32'
)
input_B
=
fluid
.
layers
.
data
(
name
=
'input_B'
,
shape
=
data_shape
,
dtype
=
'float32'
)
fake_pool_A
=
fluid
.
layers
.
data
(
name
=
'fake_pool_A'
,
shape
=
data_shape
,
dtype
=
'float32'
)
fake_pool_B
=
fluid
.
layers
.
data
(
name
=
'fake_pool_B'
,
shape
=
data_shape
,
dtype
=
'float32'
)
g_A_trainer
=
GATrainer
(
input_A
,
input_B
)
g_B_trainer
=
GBTrainer
(
input_A
,
input_B
)
d_A_trainer
=
DATrainer
(
input_A
,
fake_pool_A
)
d_B_trainer
=
DBTrainer
(
input_B
,
fake_pool_B
)
# prepare environment
place
=
fluid
.
CPUPlace
()
if
args
.
use_gpu
:
place
=
fluid
.
CUDAPlace
(
0
)
exe
=
fluid
.
Executor
(
place
)
exe
.
run
(
fluid
.
default_startup_program
())
A_pool
=
ImagePool
()
B_pool
=
ImagePool
()
A_reader
=
paddle
.
batch
(
data_reader
.
a_reader
(
shuffle
=
shuffle
),
args
.
batch_size
)()
B_reader
=
paddle
.
batch
(
data_reader
.
b_reader
(
shuffle
=
shuffle
),
args
.
batch_size
)()
if
not
args
.
run_ce
:
A_test_reader
=
data_reader
.
a_test_reader
()
B_test_reader
=
data_reader
.
b_test_reader
()
def
test
(
epoch
):
out_path
=
args
.
output
+
"/test"
if
not
os
.
path
.
exists
(
out_path
):
os
.
makedirs
(
out_path
)
i
=
0
for
data_A
,
data_B
in
zip
(
A_test_reader
(),
B_test_reader
()):
A_name
=
data_A
[
1
]
B_name
=
data_B
[
1
]
tensor_A
=
fluid
.
LoDTensor
()
tensor_B
=
fluid
.
LoDTensor
()
tensor_A
.
set
(
data_A
[
0
],
place
)
tensor_B
.
set
(
data_B
[
0
],
place
)
fake_A_temp
,
fake_B_temp
,
cyc_A_temp
,
cyc_B_temp
=
exe
.
run
(
g_A_trainer
.
infer_program
,
fetch_list
=
[
g_A_trainer
.
fake_A
,
g_A_trainer
.
fake_B
,
g_A_trainer
.
cyc_A
,
g_A_trainer
.
cyc_B
],
feed
=
{
"input_A"
:
tensor_A
,
"input_B"
:
tensor_B
})
fake_A_temp
=
np
.
squeeze
(
fake_A_temp
[
0
]).
transpose
([
1
,
2
,
0
])
fake_B_temp
=
np
.
squeeze
(
fake_B_temp
[
0
]).
transpose
([
1
,
2
,
0
])
cyc_A_temp
=
np
.
squeeze
(
cyc_A_temp
[
0
]).
transpose
([
1
,
2
,
0
])
cyc_B_temp
=
np
.
squeeze
(
cyc_B_temp
[
0
]).
transpose
([
1
,
2
,
0
])
input_A_temp
=
np
.
squeeze
(
data_A
[
0
]).
transpose
([
1
,
2
,
0
])
input_B_temp
=
np
.
squeeze
(
data_B
[
0
]).
transpose
([
1
,
2
,
0
])
imsave
(
out_path
+
"/fakeB_"
+
str
(
epoch
)
+
"_"
+
A_name
,
(
(
fake_B_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
imsave
(
out_path
+
"/fakeA_"
+
str
(
epoch
)
+
"_"
+
B_name
,
(
(
fake_A_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
imsave
(
out_path
+
"/cycA_"
+
str
(
epoch
)
+
"_"
+
A_name
,
(
(
cyc_A_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
imsave
(
out_path
+
"/cycB_"
+
str
(
epoch
)
+
"_"
+
B_name
,
(
(
cyc_B_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
imsave
(
out_path
+
"/inputA_"
+
str
(
epoch
)
+
"_"
+
A_name
,
(
(
input_A_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
imsave
(
out_path
+
"/inputB_"
+
str
(
epoch
)
+
"_"
+
B_name
,
(
(
input_B_temp
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
i
+=
1
def
checkpoints
(
epoch
):
out_path
=
args
.
output
+
"/checkpoints/"
+
str
(
epoch
)
if
not
os
.
path
.
exists
(
out_path
):
os
.
makedirs
(
out_path
)
fluid
.
io
.
save_persistables
(
exe
,
out_path
+
"/g_a"
,
main_program
=
g_A_trainer
.
program
)
fluid
.
io
.
save_persistables
(
exe
,
out_path
+
"/g_b"
,
main_program
=
g_B_trainer
.
program
)
fluid
.
io
.
save_persistables
(
exe
,
out_path
+
"/d_a"
,
main_program
=
d_A_trainer
.
program
)
fluid
.
io
.
save_persistables
(
exe
,
out_path
+
"/d_b"
,
main_program
=
d_B_trainer
.
program
)
print
(
"saved checkpoint to {}"
.
format
(
out_path
))
sys
.
stdout
.
flush
()
def
init_model
():
assert
os
.
path
.
exists
(
args
.
init_model
),
"[%s] cann't be found."
%
args
.
init_mode
fluid
.
io
.
load_persistables
(
exe
,
args
.
init_model
+
"/g_a"
,
main_program
=
g_A_trainer
.
program
)
fluid
.
io
.
load_persistables
(
exe
,
args
.
init_model
+
"/g_b"
,
main_program
=
g_B_trainer
.
program
)
fluid
.
io
.
load_persistables
(
exe
,
args
.
init_model
+
"/d_a"
,
main_program
=
d_A_trainer
.
program
)
fluid
.
io
.
load_persistables
(
exe
,
args
.
init_model
+
"/d_b"
,
main_program
=
d_B_trainer
.
program
)
print
(
"Load model from {}"
.
format
(
args
.
init_model
))
if
args
.
init_model
:
init_model
()
losses
=
[[],
[]]
t_time
=
0
build_strategy
=
fluid
.
BuildStrategy
()
exec_strategy
=
fluid
.
ExecutionStrategy
()
exec_strategy
.
num_threads
=
1
exec_strategy
.
use_experimental_executor
=
True
g_A_trainer_program
=
fluid
.
CompiledProgram
(
g_A_trainer
.
program
).
with_data_parallel
(
loss_name
=
g_A_trainer
.
g_loss_A
.
name
,
build_strategy
=
build_strategy
,
exec_strategy
=
exec_strategy
)
g_B_trainer_program
=
fluid
.
CompiledProgram
(
g_B_trainer
.
program
).
with_data_parallel
(
loss_name
=
g_B_trainer
.
g_loss_B
.
name
,
build_strategy
=
build_strategy
,
exec_strategy
=
exec_strategy
)
d_B_trainer_program
=
fluid
.
CompiledProgram
(
d_B_trainer
.
program
).
with_data_parallel
(
loss_name
=
d_B_trainer
.
d_loss_B
.
name
,
build_strategy
=
build_strategy
,
exec_strategy
=
exec_strategy
)
d_A_trainer_program
=
fluid
.
CompiledProgram
(
d_A_trainer
.
program
).
with_data_parallel
(
loss_name
=
d_A_trainer
.
d_loss_A
.
name
,
build_strategy
=
build_strategy
,
exec_strategy
=
exec_strategy
)
total_batch_num
=
0
# this is for benchmark
for
epoch
in
range
(
args
.
epoch
):
batch_id
=
0
for
i
in
range
(
max_images_num
):
if
args
.
max_iter
and
total_batch_num
==
args
.
max_iter
:
# this for benchmark
return
data_A
=
next
(
A_reader
)
data_B
=
next
(
B_reader
)
tensor_A
=
fluid
.
LoDTensor
()
tensor_B
=
fluid
.
LoDTensor
()
tensor_A
.
set
(
data_A
,
place
)
tensor_B
.
set
(
data_B
,
place
)
s_time
=
time
.
time
()
# optimize the g_A network
g_A_loss
,
fake_B_tmp
=
exe
.
run
(
g_A_trainer_program
,
fetch_list
=
[
g_A_trainer
.
g_loss_A
,
g_A_trainer
.
fake_B
],
feed
=
{
"input_A"
:
tensor_A
,
"input_B"
:
tensor_B
})
fake_pool_B
=
B_pool
.
pool_image
(
fake_B_tmp
)
# optimize the d_B network
d_B_loss
=
exe
.
run
(
d_B_trainer_program
,
fetch_list
=
[
d_B_trainer
.
d_loss_B
],
feed
=
{
"input_B"
:
tensor_B
,
"fake_pool_B"
:
fake_pool_B
})[
0
]
# optimize the g_B network
g_B_loss
,
fake_A_tmp
=
exe
.
run
(
g_B_trainer_program
,
fetch_list
=
[
g_B_trainer
.
g_loss_B
,
g_B_trainer
.
fake_A
],
feed
=
{
"input_A"
:
tensor_A
,
"input_B"
:
tensor_B
})
fake_pool_A
=
A_pool
.
pool_image
(
fake_A_tmp
)
# optimize the d_A network
d_A_loss
=
exe
.
run
(
d_A_trainer_program
,
fetch_list
=
[
d_A_trainer
.
d_loss_A
],
feed
=
{
"input_A"
:
tensor_A
,
"fake_pool_A"
:
fake_pool_A
})[
0
]
batch_time
=
time
.
time
()
-
s_time
t_time
+=
batch_time
print
(
"epoch{}; batch{}; g_A_loss: {}; d_B_loss: {}; g_B_loss: {}; d_A_loss: {}; "
"Batch_time_cost: {}"
.
format
(
epoch
,
batch_id
,
g_A_loss
[
0
],
d_B_loss
[
0
],
g_B_loss
[
0
],
d_A_loss
[
0
],
batch_time
))
losses
[
0
].
append
(
g_A_loss
[
0
])
losses
[
1
].
append
(
d_A_loss
[
0
])
sys
.
stdout
.
flush
()
batch_id
+=
1
total_batch_num
=
total_batch_num
+
1
# this is for benchmark
# profiler tools for benchmark
if
args
.
profile
and
epoch
==
0
and
batch_id
==
10
:
profiler
.
reset_profiler
()
elif
args
.
profile
and
epoch
==
0
and
batch_id
==
15
:
return
if
args
.
run_test
and
not
args
.
run_ce
:
test
(
epoch
)
if
args
.
save_checkpoints
and
not
args
.
run_ce
:
checkpoints
(
epoch
)
if
args
.
run_ce
:
print
(
"kpis,g_train_cost,{}"
.
format
(
np
.
mean
(
losses
[
0
])))
print
(
"kpis,d_train_cost,{}"
.
format
(
np
.
mean
(
losses
[
1
])))
print
(
"kpis,duration,{}"
.
format
(
t_time
/
args
.
epoch
))
if
__name__
==
"__main__"
:
args
=
parser
.
parse_args
()
print_arguments
(
args
)
if
args
.
profile
:
if
args
.
use_gpu
:
with
profiler
.
profiler
(
'All'
,
'total'
,
args
.
profiler_path
)
as
prof
:
train
(
args
)
else
:
with
profiler
.
profiler
(
"CPU"
,
sorted_key
=
'total'
)
as
cpuprof
:
train
(
args
)
else
:
train
(
args
)
PaddleCV/gan/cycle_gan/trainer.py
已删除
100644 → 0
浏览文件 @
90fcad46
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
from
model
import
build_generator_resnet_9blocks
,
build_gen_discriminator
import
paddle.fluid
as
fluid
step_per_epoch
=
1335
cycle_loss_factor
=
10.0
class
GATrainer
():
def
__init__
(
self
,
input_A
,
input_B
):
self
.
program
=
fluid
.
default_main_program
().
clone
()
with
fluid
.
program_guard
(
self
.
program
):
self
.
fake_B
=
build_generator_resnet_9blocks
(
input_A
,
name
=
"g_A"
)
self
.
fake_A
=
build_generator_resnet_9blocks
(
input_B
,
name
=
"g_B"
)
self
.
cyc_A
=
build_generator_resnet_9blocks
(
self
.
fake_B
,
"g_B"
)
self
.
cyc_B
=
build_generator_resnet_9blocks
(
self
.
fake_A
,
"g_A"
)
self
.
infer_program
=
self
.
program
.
clone
()
diff_A
=
fluid
.
layers
.
abs
(
fluid
.
layers
.
elementwise_sub
(
x
=
input_A
,
y
=
self
.
cyc_A
))
diff_B
=
fluid
.
layers
.
abs
(
fluid
.
layers
.
elementwise_sub
(
x
=
input_B
,
y
=
self
.
cyc_B
))
self
.
cyc_loss
=
(
fluid
.
layers
.
reduce_mean
(
diff_A
)
+
fluid
.
layers
.
reduce_mean
(
diff_B
))
*
cycle_loss_factor
self
.
fake_rec_B
=
build_gen_discriminator
(
self
.
fake_B
,
"d_B"
)
self
.
disc_loss_B
=
fluid
.
layers
.
reduce_mean
(
fluid
.
layers
.
square
(
self
.
fake_rec_B
-
1
))
self
.
g_loss_A
=
fluid
.
layers
.
elementwise_add
(
self
.
cyc_loss
,
self
.
disc_loss_B
)
vars
=
[]
for
var
in
self
.
program
.
list_vars
():
if
fluid
.
io
.
is_parameter
(
var
)
and
var
.
name
.
startswith
(
"g_A"
):
vars
.
append
(
var
.
name
)
self
.
param
=
vars
lr
=
0.0002
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
fluid
.
layers
.
piecewise_decay
(
boundaries
=
[
100
*
step_per_epoch
,
120
*
step_per_epoch
,
140
*
step_per_epoch
,
160
*
step_per_epoch
,
180
*
step_per_epoch
],
values
=
[
lr
,
lr
*
0.8
,
lr
*
0.6
,
lr
*
0.4
,
lr
*
0.2
,
lr
*
0.1
]),
beta1
=
0.5
,
name
=
"g_A"
)
optimizer
.
minimize
(
self
.
g_loss_A
,
parameter_list
=
vars
)
class
GBTrainer
():
def
__init__
(
self
,
input_A
,
input_B
):
self
.
program
=
fluid
.
default_main_program
().
clone
()
with
fluid
.
program_guard
(
self
.
program
):
self
.
fake_B
=
build_generator_resnet_9blocks
(
input_A
,
name
=
"g_A"
)
self
.
fake_A
=
build_generator_resnet_9blocks
(
input_B
,
name
=
"g_B"
)
self
.
cyc_A
=
build_generator_resnet_9blocks
(
self
.
fake_B
,
"g_B"
)
self
.
cyc_B
=
build_generator_resnet_9blocks
(
self
.
fake_A
,
"g_A"
)
self
.
infer_program
=
self
.
program
.
clone
()
diff_A
=
fluid
.
layers
.
abs
(
fluid
.
layers
.
elementwise_sub
(
x
=
input_A
,
y
=
self
.
cyc_A
))
diff_B
=
fluid
.
layers
.
abs
(
fluid
.
layers
.
elementwise_sub
(
x
=
input_B
,
y
=
self
.
cyc_B
))
self
.
cyc_loss
=
(
fluid
.
layers
.
reduce_mean
(
diff_A
)
+
fluid
.
layers
.
reduce_mean
(
diff_B
))
*
cycle_loss_factor
self
.
fake_rec_A
=
build_gen_discriminator
(
self
.
fake_A
,
"d_A"
)
disc_loss_A
=
fluid
.
layers
.
reduce_mean
(
fluid
.
layers
.
square
(
self
.
fake_rec_A
-
1
))
self
.
g_loss_B
=
fluid
.
layers
.
elementwise_add
(
self
.
cyc_loss
,
disc_loss_A
)
vars
=
[]
for
var
in
self
.
program
.
list_vars
():
if
fluid
.
io
.
is_parameter
(
var
)
and
var
.
name
.
startswith
(
"g_B"
):
vars
.
append
(
var
.
name
)
self
.
param
=
vars
lr
=
0.0002
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
fluid
.
layers
.
piecewise_decay
(
boundaries
=
[
100
*
step_per_epoch
,
120
*
step_per_epoch
,
140
*
step_per_epoch
,
160
*
step_per_epoch
,
180
*
step_per_epoch
],
values
=
[
lr
,
lr
*
0.8
,
lr
*
0.6
,
lr
*
0.4
,
lr
*
0.2
,
lr
*
0.1
]),
beta1
=
0.5
,
name
=
"g_B"
)
optimizer
.
minimize
(
self
.
g_loss_B
,
parameter_list
=
vars
)
class
DATrainer
():
def
__init__
(
self
,
input_A
,
fake_pool_A
):
self
.
program
=
fluid
.
default_main_program
().
clone
()
with
fluid
.
program_guard
(
self
.
program
):
self
.
rec_A
=
build_gen_discriminator
(
input_A
,
"d_A"
)
self
.
fake_pool_rec_A
=
build_gen_discriminator
(
fake_pool_A
,
"d_A"
)
self
.
d_loss_A
=
(
fluid
.
layers
.
square
(
self
.
fake_pool_rec_A
)
+
fluid
.
layers
.
square
(
self
.
rec_A
-
1
))
/
2.0
self
.
d_loss_A
=
fluid
.
layers
.
reduce_mean
(
self
.
d_loss_A
)
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
0.0002
,
beta1
=
0.5
)
optimizer
.
_name
=
"d_A"
vars
=
[]
for
var
in
self
.
program
.
list_vars
():
if
fluid
.
io
.
is_parameter
(
var
)
and
var
.
name
.
startswith
(
"d_A"
):
vars
.
append
(
var
.
name
)
self
.
param
=
vars
lr
=
0.0002
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
fluid
.
layers
.
piecewise_decay
(
boundaries
=
[
100
*
step_per_epoch
,
120
*
step_per_epoch
,
140
*
step_per_epoch
,
160
*
step_per_epoch
,
180
*
step_per_epoch
],
values
=
[
lr
,
lr
*
0.8
,
lr
*
0.6
,
lr
*
0.4
,
lr
*
0.2
,
lr
*
0.1
]),
beta1
=
0.5
,
name
=
"d_A"
)
optimizer
.
minimize
(
self
.
d_loss_A
,
parameter_list
=
vars
)
class
DBTrainer
():
def
__init__
(
self
,
input_B
,
fake_pool_B
):
self
.
program
=
fluid
.
default_main_program
().
clone
()
with
fluid
.
program_guard
(
self
.
program
):
self
.
rec_B
=
build_gen_discriminator
(
input_B
,
"d_B"
)
self
.
fake_pool_rec_B
=
build_gen_discriminator
(
fake_pool_B
,
"d_B"
)
self
.
d_loss_B
=
(
fluid
.
layers
.
square
(
self
.
fake_pool_rec_B
)
+
fluid
.
layers
.
square
(
self
.
rec_B
-
1
))
/
2.0
self
.
d_loss_B
=
fluid
.
layers
.
reduce_mean
(
self
.
d_loss_B
)
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
0.0002
,
beta1
=
0.5
)
vars
=
[]
for
var
in
self
.
program
.
list_vars
():
if
fluid
.
io
.
is_parameter
(
var
)
and
var
.
name
.
startswith
(
"d_B"
):
vars
.
append
(
var
.
name
)
self
.
param
=
vars
lr
=
0.0002
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
fluid
.
layers
.
piecewise_decay
(
boundaries
=
[
100
*
step_per_epoch
,
120
*
step_per_epoch
,
140
*
step_per_epoch
,
160
*
step_per_epoch
,
180
*
step_per_epoch
],
values
=
[
lr
,
lr
*
0.8
,
lr
*
0.6
,
lr
*
0.4
,
lr
*
0.2
,
lr
*
0.1
]),
beta1
=
0.5
,
name
=
"d_B"
)
optimizer
.
minimize
(
self
.
d_loss_B
,
parameter_list
=
vars
)
PaddleCV/gan/cycle_gan/utility.py
已删除
100644 → 0
浏览文件 @
90fcad46
"""Contains common utility functions."""
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
#
#Licensed under the Apache License, Version 2.0 (the "License");
#you may not use this file except in compliance with the License.
#You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#Unless required by applicable law or agreed to in writing, software
#distributed under the License is distributed on an "AS IS" BASIS,
#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
#See the License for the specific language governing permissions and
#limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
distutils.util
import
six
import
random
import
glob
import
numpy
as
np
def
print_arguments
(
args
):
"""Print argparse's arguments.
Usage:
.. code-block:: python
parser = argparse.ArgumentParser()
parser.add_argument("name", default="Jonh", type=str, help="User name.")
args = parser.parse_args()
print_arguments(args)
:param args: Input argparse.Namespace for printing.
:type args: argparse.Namespace
"""
print
(
"----------- Configuration Arguments -----------"
)
for
arg
,
value
in
sorted
(
six
.
iteritems
(
vars
(
args
))):
print
(
"%s: %s"
%
(
arg
,
value
))
print
(
"------------------------------------------------"
)
def
add_arguments
(
argname
,
type
,
default
,
help
,
argparser
,
**
kwargs
):
"""Add argparse's argument.
Usage:
.. code-block:: python
parser = argparse.ArgumentParser()
add_argument("name", str, "Jonh", "User name.", parser)
args = parser.parse_args()
"""
type
=
distutils
.
util
.
strtobool
if
type
==
bool
else
type
argparser
.
add_argument
(
"--"
+
argname
,
default
=
default
,
type
=
type
,
help
=
help
+
' Default: %(default)s.'
,
**
kwargs
)
class
ImagePool
(
object
):
def
__init__
(
self
,
pool_size
=
50
):
self
.
pool
=
[]
self
.
count
=
0
self
.
pool_size
=
pool_size
def
pool_image
(
self
,
image
):
if
self
.
count
<
self
.
pool_size
:
self
.
pool
.
append
(
image
)
self
.
count
+=
1
return
image
else
:
p
=
random
.
random
()
if
p
>
0.5
:
random_id
=
random
.
randint
(
0
,
self
.
pool_size
-
1
)
temp
=
self
.
pool
[
random_id
]
self
.
pool
[
random_id
]
=
image
return
temp
else
:
return
image
PaddleCV/gan/infer.py
浏览文件 @
6b882d42
...
@@ -204,6 +204,7 @@ def infer(args):
...
@@ -204,6 +204,7 @@ def infer(args):
if
not
os
.
path
.
exists
(
args
.
output
):
if
not
os
.
path
.
exists
(
args
.
output
):
os
.
makedirs
(
args
.
output
)
os
.
makedirs
(
args
.
output
)
attr_names
=
args
.
selected_attrs
.
split
(
','
)
attr_names
=
args
.
selected_attrs
.
split
(
','
)
if
args
.
model_net
==
'AttGAN'
or
args
.
model_net
==
'STGAN'
:
if
args
.
model_net
==
'AttGAN'
or
args
.
model_net
==
'STGAN'
:
...
@@ -311,6 +312,9 @@ def infer(args):
...
@@ -311,6 +312,9 @@ def infer(args):
fake_temp
=
save_batch_image
(
fake_temp
[
0
])
fake_temp
=
save_batch_image
(
fake_temp
[
0
])
input_temp
=
save_batch_image
(
np
.
array
(
real_img
))
input_temp
=
save_batch_image
(
np
.
array
(
real_img
))
if
len
(
image_names
)
==
1
:
fake_temp
=
np
.
expand_dims
(
fake_temp
,
axis
=
0
)
input_temp
=
np
.
expand_dims
(
input_temp
,
axis
=
0
)
for
i
,
name
in
enumerate
(
image_names
):
for
i
,
name
in
enumerate
(
image_names
):
fake_image
=
Image
.
fromarray
(((
fake_temp
[
i
]
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
fake_image
=
Image
.
fromarray
(((
fake_temp
[
i
]
+
1
)
*
127.5
).
astype
(
np
.
uint8
))
fake_image
.
save
(
os
.
path
.
join
(
args
.
output
,
"fake_"
+
name
))
fake_image
.
save
(
os
.
path
.
join
(
args
.
output
,
"fake_"
+
name
))
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}