Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
65765531
M
models
项目概览
PaddlePaddle
/
models
1 年多 前同步成功
通知
226
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
65765531
编写于
12月 16, 2020
作者:
S
smallv0221
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/models
into yxp1216
上级
c26e7dbb
cd646190
变更
10
展开全部
隐藏空白更改
内联
并排
Showing
10 changed file
with
738 addition
and
53 deletion
+738
-53
PaddleNLP/examples/machine_translation/seq2seq/README.md
PaddleNLP/examples/machine_translation/seq2seq/README.md
+7
-6
PaddleNLP/examples/machine_translation/transformer/README.md
PaddleNLP/examples/machine_translation/transformer/README.md
+13
-10
PaddleNLP/examples/slim/README.md
PaddleNLP/examples/slim/README.md
+106
-0
PaddleNLP/examples/slim/ofa_bert.jpg
PaddleNLP/examples/slim/ofa_bert.jpg
+0
-0
PaddleNLP/examples/slim/run_glue_ofa.py
PaddleNLP/examples/slim/run_glue_ofa.py
+582
-0
PaddleNLP/examples/text_generation/couplet/README.md
PaddleNLP/examples/text_generation/couplet/README.md
+1
-5
PaddleNLP/examples/text_generation/couplet/data.py
PaddleNLP/examples/text_generation/couplet/data.py
+3
-6
PaddleNLP/examples/text_generation/couplet/predict.py
PaddleNLP/examples/text_generation/couplet/predict.py
+1
-1
PaddleNLP/paddlenlp/__init__.py
PaddleNLP/paddlenlp/__init__.py
+1
-1
PaddleNLP/paddlenlp/data/vocab.py
PaddleNLP/paddlenlp/data/vocab.py
+24
-24
未找到文件。
PaddleNLP/examples/machine_translation/seq2seq/README.md
浏览文件 @
65765531
...
...
@@ -31,7 +31,7 @@ Sequence to Sequence (Seq2Seq),使用编码器-解码器(Encoder-Decoder)
本教程使用
[
IWSLT'15 English-Vietnamese data
](
https://nlp.stanford.edu/projects/nmt/
)
数据集中的英语到越南语的数据作为训练语料,tst2012的数据作为开发集,tst2013的数据作为测试集。
### 数据获取
如果用户在初始化数据集时没有提供路径,数据集会自动下载到
`paddlenlp.utils.env.DATA_HOME`
的
`/machine_translation/IWSLT15/`
路径下,例如在linux系统下,默认存储路径是
`
/root
/.paddlenlp/datasets/machine_translation/IWSLT15`
。
如果用户在初始化数据集时没有提供路径,数据集会自动下载到
`paddlenlp.utils.env.DATA_HOME`
的
`/machine_translation/IWSLT15/`
路径下,例如在linux系统下,默认存储路径是
`
~
/.paddlenlp/datasets/machine_translation/IWSLT15`
。
## 模型训练
...
...
@@ -56,7 +56,7 @@ python train.py \
## 模型预测
训练完成之后,可以使用保存的模型(由
`--init_from_ckpt`
指定)对测试集的数据集进行beam search解码,其中译文数据由
`--infer_target_file`
指定),在linux系统下,默认安装路径为
`
/root
/.paddlenlp/datasets/machine_translation/IWSLT15/iwslt15.en-vi/tst2013.vi`
,如果您使用的是Windows系统,需要更改下面的路径。预测命令如下:
训练完成之后,可以使用保存的模型(由
`--init_from_ckpt`
指定)对测试集的数据集进行beam search解码,其中译文数据由
`--infer_target_file`
指定),在linux系统下,默认安装路径为
`
~
/.paddlenlp/datasets/machine_translation/IWSLT15/iwslt15.en-vi/tst2013.vi`
,如果您使用的是Windows系统,需要更改下面的路径。预测命令如下:
```
sh
python predict.py
\
...
...
@@ -67,7 +67,7 @@ python predict.py \
--init_scale
0.1
\
--max_grad_norm
5.0
\
--init_from_ckpt
attention_models/9
\
--infer_target_file
/root
/.paddlenlp/datasets/machine_translation/IWSLT15/iwslt15.en-vi/tst2013.vi
\
--infer_target_file
~
/.paddlenlp/datasets/machine_translation/IWSLT15/iwslt15.en-vi/tst2013.vi
\
--infer_output_file
infer_output.txt
\
--beam_size
10
\
--use_gpu
True
...
...
@@ -75,11 +75,12 @@ python predict.py \
各参数的具体说明请参阅
`args.py`
,注意预测时所用模型超参数需和训练时一致。
## 效果评价
使用
[
*multi-bleu.perl*
](
https://github.com/moses-smt/mosesdecoder.git
)
工具来评价模型预测的翻译质量,使用方法如下:
## 预测效果评价
使用
[
*multi-bleu.perl*
](
https://github.com/moses-smt/mosesdecoder.git
)
工具来评价模型预测的翻译质量,将该工具下载在该项目路径下,然后使用如下的命令,可以看到BLEU指标的结果
(需要注意的是,在windows系统下,可能需要更改文件路径
`~/.paddlenlp/datasets/machine_translation/IWSLT15/iwslt15.en-vi/tst2013.vi`
):
```
sh
perl mosesdecoder/scripts/generic/multi-bleu.perl
data/
en-vi/tst2013.vi < infer_output.txt
perl mosesdecoder/scripts/generic/multi-bleu.perl
~/.paddlenlp/datasets/machine_translation/IWSLT15/iwslt15.
en-vi/tst2013.vi < infer_output.txt
```
取第10个epoch保存的模型进行预测,取beam_size=10。效果如下:
...
...
PaddleNLP/examples/machine_translation/transformer/README.md
浏览文件 @
65765531
...
...
@@ -25,7 +25,7 @@
1.
paddle安装
本项目依赖于 PaddlePaddle 2.0rc及以上版本或适当的develop版本,请参考 [安装指南](https://www.paddlepaddle.org.cn/install/quick) 进行安装
本项目依赖于 PaddlePaddle 2.0rc
1
及以上版本或适当的develop版本,请参考 [安装指南](https://www.paddlepaddle.org.cn/install/quick) 进行安装
2.
下载代码
...
...
@@ -37,7 +37,6 @@
此外,需要另外涉及:
* attrdict
* pyyaml
* subword-nmt (可选,用于处理数据)
...
...
@@ -60,42 +59,45 @@ dataset = WMT14ende.get_datasets(mode="train", transform_func=transform_func)
以提供的英德翻译数据为例,可以执行以下命令进行模型训练:
```
sh
```
sh
# setting visible devices for training
export
CUDA_VISIBLE_DEVICES
=
0
python train.py
--config
./configs/transformer.base.yaml
```
可以在
`configs/transformer.big.yaml`
和
`configs/transformer.base.yaml`
文件中设置相应的参数。
可以在
`configs/transformer.big.yaml`
和
`configs/transformer.base.yaml`
文件中设置相应的参数。
如果执行不提供
`--config`
选项,程序将默认使用 big model 的配置。
### 单机多卡
同样,可以执行如下命令实现八卡训练:
```
sh
```
sh
export
CUDA_VISIBLE_DEVICES
=
0,1,2,3,4,5,6,7
python
-m
paddle.distributed.launch
--gpus
"0,1,2,3,4,5,6,7"
train.py
--config
./configs/transformer.base.yaml
```
与上面的情况相似,可以在
`configs/transformer.big.yaml`
和
`configs/transformer.base.yaml`
文件中设置相应的参数。如果执行不提供
`--config`
选项,程序将默认使用 big model 的配置。
### 模型推断
以英德翻译数据为例,模型训练完成后可以执行以下命令对指定文件中的文本进行翻译:
```
sh
```
sh
# setting visible devices for prediction
export
CUDA_VISIBLE_DEVICES
=
0
python predict.py
python predict.py
--config
./configs/transformer.base.yaml
```
由
`predict_file`
指定的文件中文本的翻译结果会输出到
`output_file`
指定的文件。执行预测时需要设置
`init_from_params`
来给出模型所在目录,更多参数的使用可以在
`configs/transformer.big.yaml`
和
`configs/transformer.base.yaml`
文件中查阅注释说明并进行更改设置。需要注意的是,目前预测仅实现了单卡的预测,原因在于,翻译后面需要的模型评估依赖于预测结果写入文件顺序,多卡情况下,目前不能保证结果写入文件的顺序。
由
`predict_file`
指定的文件中文本的翻译结果会输出到
`output_file`
指定的文件。执行预测时需要设置
`init_from_params`
来给出模型所在目录,更多参数的使用可以在
`configs/transformer.big.yaml`
和
`configs/transformer.base.yaml`
文件中查阅注释说明并进行更改设置。如果执行不提供
`--config`
选项,程序将默认使用 big model 的配置。
需要注意的是,目前预测仅实现了单卡的预测,原因在于,翻译后面需要的模型评估依赖于预测结果写入文件顺序,多卡情况下,目前暂未支持将结果按照指定顺序写入文件。
### 模型评估
预测结果中每行输出是对应行输入的得分最高的翻译,对于使用 BPE 的数据,预测出的翻译结果也将是 BPE 表示的数据,要还原成原始的数据(这里指 tokenize 后的数据)才能进行正确的评估。评估过程具体如下(BLEU 是翻译任务常用的自动评估方法指标):
```
sh
```
sh
# 还原 predict.txt 中的预测结果为 tokenize 后的数据
sed
-r
's/(@@ )|(@@ ?$)//g'
predict.txt
>
predict.tok.txt
# 若无 BLEU 评估工具,需先进行下载
...
...
@@ -103,7 +105,8 @@ git clone https://github.com/moses-smt/mosesdecoder.git
# 以英德翻译 newstest2014 测试数据为例
perl mosesdecoder/scripts/generic/multi-bleu.perl ~/.paddlenlp/datasets/machine_translation/WMT14ende/WMT14.en-de/wmt14_ende_data/newstest2014.tok.de < predict.tok.txt
```
可以看到类似如下的结果,此处结果是 big model 在 newstest2014 上的结果:
执行上述操作之后,可以看到类似如下的结果,此处结果是 big model 在 newstest2014 上的 BLEU 结果:
```
BLEU = 27.48, 58.6/33.2/21.1/13.9 (BP=1.000, ratio=1.012, hyp_len=65312, ref_len=64506)
```
...
...
PaddleNLP/examples/slim/README.md
0 → 100644
浏览文件 @
65765531
# PaddleSlim-OFA in BERT
BERT-base模型是一个迁移能力很强的通用语义表示模型,但是模型中也有一些参数冗余。本教程将介绍如何使用PaddleSlim对BERT-base模型进行压缩。
## 压缩结果
基于
`bert-base-uncased`
在GLUE dev数据集上的finetune结果进行压缩。压缩后模型精度和压缩前模型在GLUE dev数据集上的精度对比如下表所示, 压缩后模型相比压缩前加速约2倍,模型参数大小减小26%(从110M减少到81M)。
| Task | Metric | Result | Result with PaddleSlim |
|:-----:|:----------------------------:|:-----------------:|:----------------------:|
| SST-2 | Accuracy | 0.93005 | 0.931193 |
| QNLI | Accuracy | 0.91781 | 0.920740 |
| CoLA | Mattehew's corr | 0.59557 | 0.601244 |
| MRPC | F1/Accuracy | 0.91667/0.88235 | 0.91740/0.88480 |
| STS-B | Person/Spearman corr | 0.88847/0.88350 | 0.89271/0.88958 |
| QQP | Accuracy/F1 | 0.90581/0.87347 | 0.90994/0.87947 |
| MNLI | Matched acc/MisMatched acc | 0.84422/0.84825 | 0.84687/0.85242 |
| RTE | Accuracy | 0.711191 | 0.718412 |
## 快速开始
本教程示例以GLUE/SST-2 数据集为例。
### Fine-tuing
首先需要对Pretrain-Model在实际的下游任务上进行Finetuning,得到需要压缩的模型。
```
shell
cd
../bert/
export
PYTHOPATH
=
${
PATH_OF_PaddleNLP
}
```
```
python
export
CUDA_VISIBLE_DEVICES
=
0
export
TASK_NAME
=
SST
-
2
python
-
u
.
/
run_glue
.
py
\
--
model_type
bert
\
--
model_name_or_path
bert
-
base
-
uncased
\
--
task_name
$
TASK_NAME
\
--
max_seq_length
128
\
--
batch_size
32
\
--
learning_rate
2e-5
\
--
num_train_epochs
3
\
--
logging_steps
1
\
--
save_steps
500
\
--
output_dir
.
/
tmp
/
$
TASK_NAME
/
\
--
n_gpu
1
\
```
参数详细含义参考
[
README.md
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/bert
)
Fine-tuning 在dev上的结果如压缩结果表格中Result那一列所示。
### 安装PaddleSlim
压缩功能依赖最新版本的PaddleSlim.
```
shell
git clone https://github.com/PaddlePaddle/PaddleSlim.git
cd
Paddleslim
python setup.py
install
```
### 压缩训练
```
python
python
-
u
.
/
run_glue_ofa
.
py
--
model_type
bert
\
--
model_name_or_path
$
{
task_pretrained_model_dir
}
\
--
task_name
$
TASK_NAME
--
max_seq_length
128
\
--
batch_size
32
\
--
learning_rate
2e-5
\
--
num_train_epochs
6
\
--
logging_steps
10
\
--
save_steps
100
\
--
output_dir
.
/
tmp
/
$
TASK_NAME
\
--
n_gpu
1
\
--
width_mult_list
1.0
0.8333333333333334
0.6666666666666666
0.5
```
其中参数释义如下:
-
`model_type`
指示了模型类型,当前仅支持BERT模型。
-
`model_name_or_path`
指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer。若模型相关内容保存在本地,这里也可以提供相应目录地址。
-
`task_name`
表示 Fine-tuning 的任务。
-
`max_seq_length`
表示最大句子长度,超过该长度将被截断。
-
`batch_size`
表示每次迭代
**每张卡**
上的样本数目。
-
`learning_rate`
表示基础学习率大小,将于learning rate scheduler产生的值相乘作为当前学习率。
-
`num_train_epochs`
表示训练轮数。
-
`logging_steps`
表示日志打印间隔。
-
`save_steps`
表示模型保存及评估间隔。
-
`output_dir`
表示模型保存路径。
-
`n_gpu`
表示使用的 GPU 卡数。若希望使用多卡训练,将其设置为指定数目即可;若为0,则使用CPU。
-
`width_mult_list`
表示压缩训练过程中,对每层Transformer Block的宽度选择的范围。
压缩训练之后在dev上的结果如压缩结果表格中Result with PaddleSlim那一列所示, 速度相比原始模型加速2倍。
## 压缩原理
1.
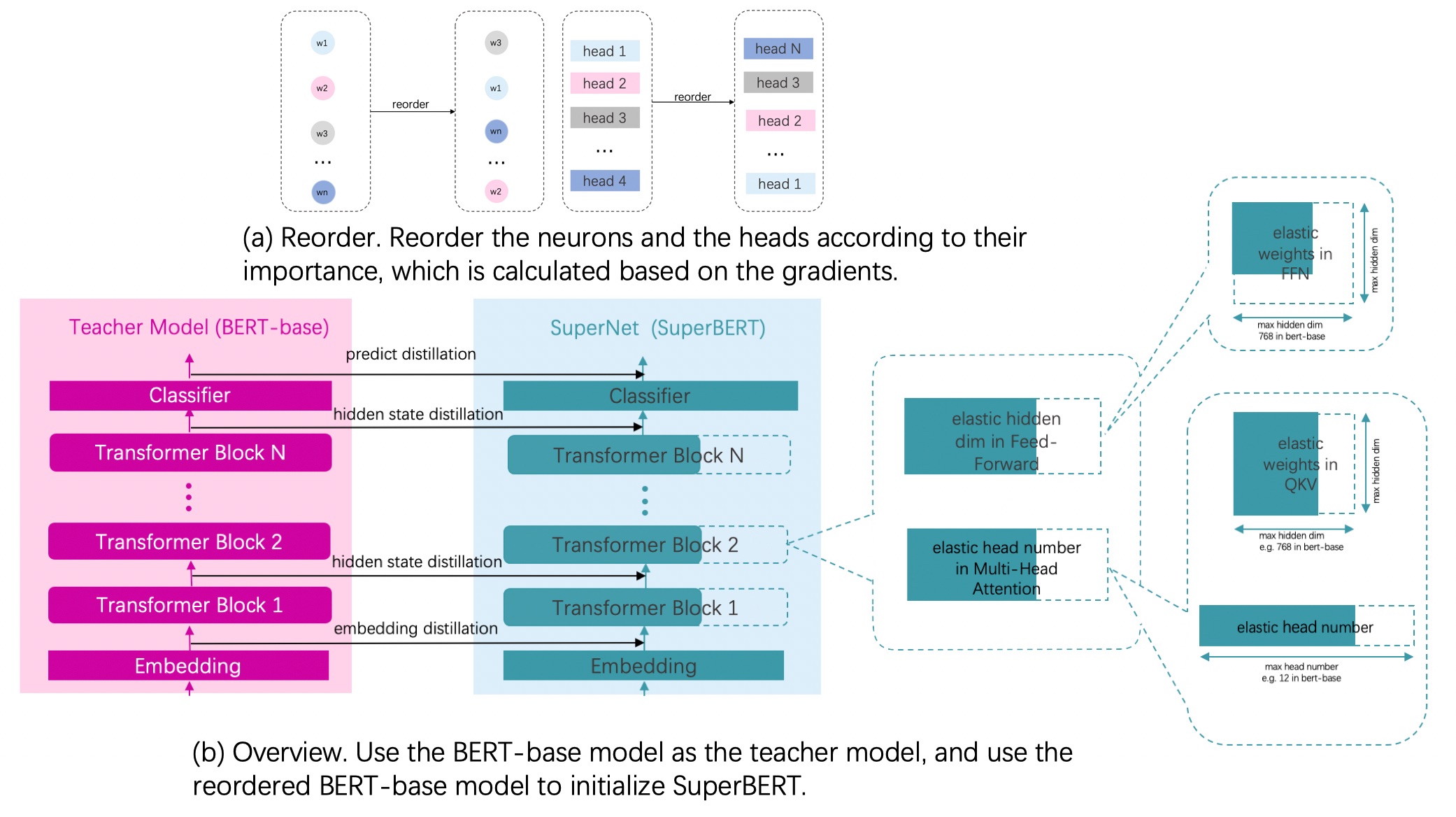
对Fine-tuning得到模型通过计算参数及其梯度的乘积得到参数的重要性,把模型参数根据重要性进行重排序。
2.
超网络中最大的子网络选择和Bert-base模型网络结构一致的网络结构,其他小的子网络是对最大网络的进行不同的宽度选择来得到的,宽度选择具体指的是网络中的参数进行裁剪,所有子网络在整个训练过程中都是参数共享的。
2.
用重排序之后的模型参数作为超网络模型的初始化参数。
3.
Fine-tuning之后的模型作为教师网络,超网络作为学生网络,进行知识蒸馏。
<p
align=
"center"
>
<img
src=
"ofa_bert.jpg"
width=
"950"
/><br
/>
整体流程图
</p>
## 参考论文
1.
Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu. DynaBERT: Dynamic BERT with Adaptive Width and Depth.
2.
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han. Once for all: Train one network and specialize it for efficient deployment.
PaddleNLP/examples/slim/ofa_bert.jpg
0 → 100644
浏览文件 @
65765531
364.6 KB
PaddleNLP/examples/slim/run_glue_ofa.py
0 → 100644
浏览文件 @
65765531
此差异已折叠。
点击以展开。
PaddleNLP/examples/text_generation/couplet/README.md
浏览文件 @
65765531
...
...
@@ -30,7 +30,7 @@ Sequence to Sequence (Seq2Seq),使用编码器-解码器(Encoder-Decoder)
本教程使用
[
couplet数据集
](
https://paddlenlp.bj.bcebos.com/datasets/couplet.tar.gz
)
数据集作为训练语料,train_src.tsv及train_tgt.tsv为训练集,dev_src.tsv及test_tgt.tsv为开发集,test_src.tsv及test_tgt.tsv为测试集。
数据集会在
`CoupletDataset`
初始化时自动下载,如果用户在初始化数据集时没有提供路径,在linux系统下,数据集会自动下载到
`
/root
/.paddlenlp/datasets/machine_translation/CoupletDataset/`
目录下
数据集会在
`CoupletDataset`
初始化时自动下载,如果用户在初始化数据集时没有提供路径,在linux系统下,数据集会自动下载到
`
~
/.paddlenlp/datasets/machine_translation/CoupletDataset/`
目录下
## 模型训练
...
...
@@ -72,16 +72,12 @@ python predict.py \
上联:崖悬风雨骤 下联:月落水云寒
上联:约春章柳下 下联:邀月醉花间
上联:箬笠红尘外 下联:扁舟明月中
上联:书香醉倒窗前月 下联:烛影摇红梦里人
上联:踏雪寻梅求雅趣 下联:临风把酒觅知音
上联:未出南阳天下论 下联:先登北斗汉中书
...
...
PaddleNLP/examples/text_generation/couplet/data.py
浏览文件 @
65765531
...
...
@@ -19,10 +19,8 @@ from functools import partial
import
numpy
as
np
import
paddle
from
paddle.utils.download
import
get_path_from_url
from
paddlenlp.data
import
Vocab
,
Pad
from
paddlenlp.data
import
SamplerHelper
from
paddlenlp.utils.env
import
DATA_HOME
from
paddlenlp.datasets
import
TranslationDataset
...
...
@@ -32,7 +30,7 @@ def create_train_loader(batch_size=128):
pad_id
=
vocab
[
CoupletDataset
.
EOS_TOKEN
]
train_batch_sampler
=
SamplerHelper
(
train_ds
).
shuffle
().
batch
(
batch_size
=
batch_size
)
.
shard
()
batch_size
=
batch_size
)
train_loader
=
paddle
.
io
.
DataLoader
(
train_ds
,
...
...
@@ -50,8 +48,7 @@ def create_infer_loader(batch_size=128):
bos_id
=
vocab
[
CoupletDataset
.
BOS_TOKEN
]
eos_id
=
vocab
[
CoupletDataset
.
EOS_TOKEN
]
test_batch_sampler
=
SamplerHelper
(
test_ds
).
batch
(
batch_size
=
batch_size
).
shard
()
test_batch_sampler
=
SamplerHelper
(
test_ds
).
batch
(
batch_size
=
batch_size
)
test_loader
=
paddle
.
io
.
DataLoader
(
test_ds
,
...
...
@@ -103,7 +100,7 @@ class CoupletDataset(TranslationDataset):
raise
TypeError
(
'`train`, `dev` or `test` is supported but `{}` is passed in'
.
format
(
mode
))
# Download data
# Download
and read
data
self
.
data
=
self
.
get_data
(
mode
=
mode
,
root
=
root
)
self
.
vocab
,
_
=
self
.
get_vocab
(
root
)
self
.
transform
()
...
...
PaddleNLP/examples/text_generation/couplet/predict.py
浏览文件 @
65765531
...
...
@@ -44,7 +44,7 @@ def do_predict(args):
test_loader
,
vocab_size
,
pad_id
,
bos_id
,
eos_id
=
create_infer_loader
(
args
.
batch_size
)
vocab
,
_
=
CoupletDataset
.
get_vocab
()
trg_idx2word
=
vocab
.
_
idx_to_token
trg_idx2word
=
vocab
.
idx_to_token
model
=
paddle
.
Model
(
Seq2SeqAttnInferModel
(
...
...
PaddleNLP/paddlenlp/__init__.py
浏览文件 @
65765531
...
...
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
__version__
=
'2.0.0a
7
'
__version__
=
'2.0.0a
8
'
from
.
import
data
from
.
import
datasets
...
...
PaddleNLP/paddlenlp/data/vocab.py
浏览文件 @
65765531
...
...
@@ -36,14 +36,14 @@ class Vocab(object):
between tokens and indices to be used. If provided, adjust the tokens
and indices mapping according to it. If None, counter must be provided.
Default: None.
unk_token (str): special token for unknow token. If no need, it also
could be None. Default:
'<unk>'
.
pad_token (str): special token for padding token. If no need, it also
could be None. Default:
'<pad>'
.
bos_token (str): special token for bos token. If no need, it also
could be None. Default:
<bos>'
.
eos_token (str): special token for eos token. If no need, it also
could be None. Default:
'<eos>'
.
unk_token (str): special token for unknow token
'<unk>'
. If no need, it also
could be None. Default:
None
.
pad_token (str): special token for padding token
'<pad>'
. If no need, it also
could be None. Default:
None
.
bos_token (str): special token for bos token
'<bos>'
. If no need, it also
could be None. Default:
None
.
eos_token (str): special token for eos token
'<eos>'
. If no need, it also
could be None. Default:
None
.
**kwargs (dict): Keyword arguments ending with `_token`. It can be used
to specify further special tokens that will be exposed as attribute
of the vocabulary and associated with an index.
...
...
@@ -54,10 +54,10 @@ class Vocab(object):
max_size
=
None
,
min_freq
=
1
,
token_to_idx
=
None
,
unk_token
=
'<unk>'
,
pad_token
=
'<pad>'
,
bos_token
=
'<bos>'
,
eos_token
=
'<eos>'
,
unk_token
=
None
,
pad_token
=
None
,
bos_token
=
None
,
eos_token
=
None
,
**
kwargs
):
# Handle special tokens
combs
=
((
'unk_token'
,
unk_token
),
(
'pad_token'
,
pad_token
),
...
...
@@ -317,10 +317,10 @@ class Vocab(object):
max_size
=
None
,
min_freq
=
1
,
token_to_idx
=
None
,
unk_token
=
'<unk>'
,
pad_token
=
'<pad>'
,
bos_token
=
'<bos>'
,
eos_token
=
'<eos>'
,
unk_token
=
None
,
pad_token
=
None
,
bos_token
=
None
,
eos_token
=
None
,
**
kwargs
):
"""
Building vocab accoring to given iterator and other information. Iterate
...
...
@@ -333,14 +333,14 @@ class Vocab(object):
between tokens and indices to be used. If provided, adjust the tokens
and indices mapping according to it. If None, counter must be provided.
Default: None.
unk_token (str): special token for unknow token. If no need, it also
could be None. Default:
'<unk>'
.
pad_token (str): special token for padding token. If no need, it also
could be None. Default:
'<pad>'
.
bos_token (str): special token for bos token. If no need, it also
could be None. Default:
<bos>'
.
eos_token (str): special token for eos token. If no need, it also
could be None. Default:
'<eos>'
.
unk_token (str): special token for unknow token
'<unk>'
. If no need, it also
could be None. Default:
None
.
pad_token (str): special token for padding token
'<pad>'
. If no need, it also
could be None. Default:
None
.
bos_token (str): special token for bos token
'<bos>'
. If no need, it also
could be None. Default:
None
.
eos_token (str): special token for eos token
'<eos>'
. If no need, it also
could be None. Default:
None
.
**kwargs (dict): Keyword arguments ending with `_token`. It can be used
to specify further special tokens that will be exposed as attribute
of the vocabulary and associated with an index.
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}