Merge branch 'develop' of https://github.com/PaddlePaddle/models into ce_image_classification2
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
fluid/ocr_recognition/.run.sh
已删除
100644 → 0
fluid/ocr_recognition/.run_ce.sh
100644 → 100755
fluid/ocr_recognition/crnn_ctc_model.py
100644 → 100755
{kind=link}
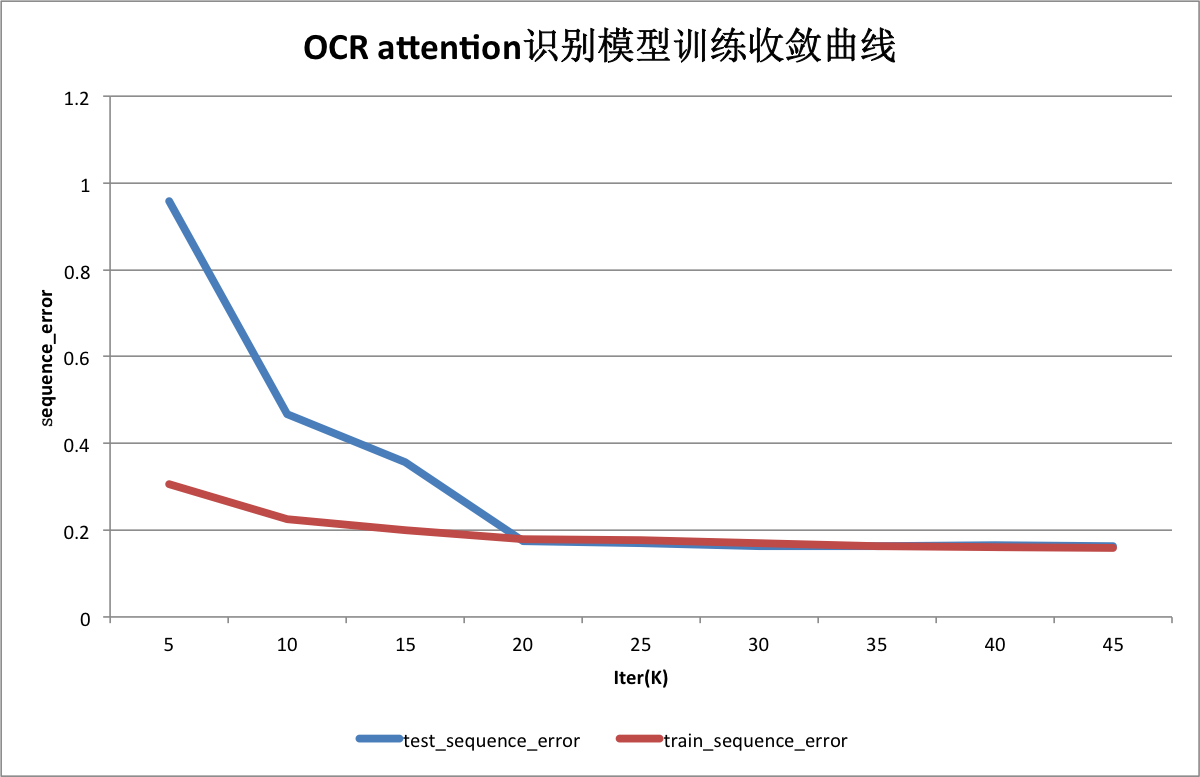
72.4 KB
fluid/ocr_recognition/infer.py
100644 → 100755
fluid/ocr_recognition/utility.py
100644 → 100755