add Deeplabv3+ model (#1252)
* add Deeplabv3+ model
Showing
fluid/deeplabv3+/README.md
0 → 100644
fluid/deeplabv3+/eval.py
0 → 100644
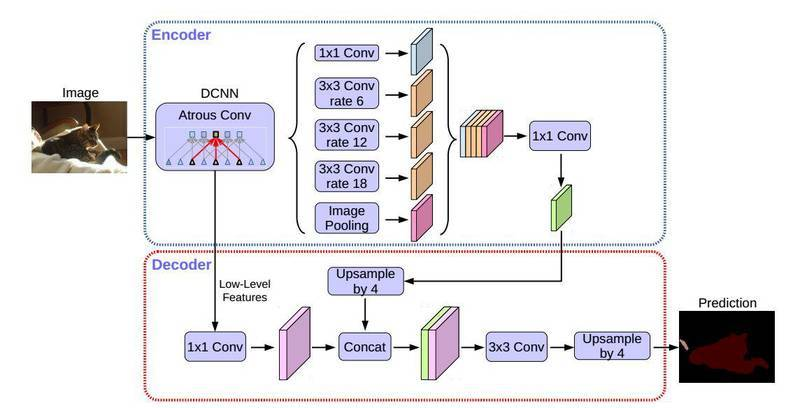
fluid/deeplabv3+/imgs/model.png
0 → 100644
{kind=link}
269.2 KB
fluid/deeplabv3+/models.py
0 → 100644
fluid/deeplabv3+/reader.py
0 → 100644
fluid/deeplabv3+/train.py
0 → 100644