Code clean for release (#2650)
Showing
AutoDL/HiNAS_models/README.md
已删除
100755 → 0
AutoDL/HiNAS_models/reader.py
已删除
100755 → 0
文件已删除
文件已删除
文件已删除
AutoDL/LRC/README.md
已删除
100644 → 0
AutoDL/LRC/README_cn.md
已删除
100644 → 0
AutoDL/LRC/genotypes.py
已删除
100644 → 0
AutoDL/LRC/learning_rate.py
已删除
100644 → 0
AutoDL/LRC/model.py
已删除
100644 → 0
AutoDL/LRC/operations.py
已删除
100644 → 0
AutoDL/LRC/reader.py
已删除
100644 → 0
AutoDL/LRC/run.sh
已删除
100644 → 0
AutoDL/LRC/train_mixup.py
已删除
100644 → 0
AutoDL/LRC/utils.py
已删除
100644 → 0
{kind=link}
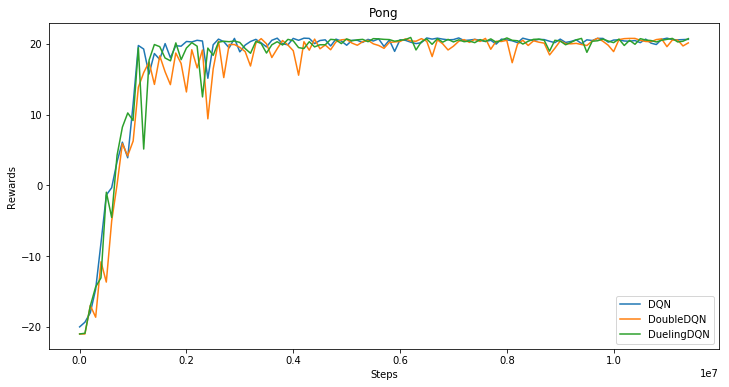
38.1 KB
PaddleRL/DeepQNetwork/play.py
已删除
100644 → 0
文件已删除
文件已删除
PaddleRL/README.md
已删除
100644 → 0
{kind=link}
{kind=link}
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
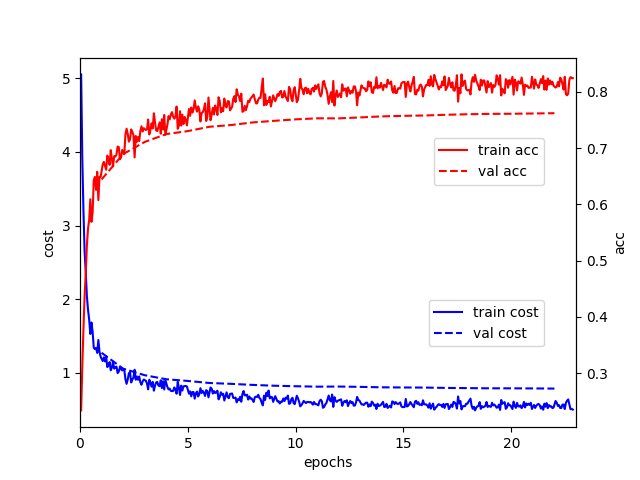
41.7 KB
{kind=link}
此差异已折叠。
PaddleSpeech/DeepASR/infer.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
PaddleSpeech/DeepASR/train.py
已删除
100644 → 0
此差异已折叠。
PaddleSpeech/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
fluid/AutoDL/LRC/README.md
已删除
100644 → 0
此差异已折叠。
fluid/AutoDL/LRC/README_cn.md
已删除
100644 → 0
此差异已折叠。
fluid/DeepASR/README.md
已删除
100644 → 0
此差异已折叠。
fluid/DeepASR/README_cn.md
已删除
100644 → 0
此差异已折叠。
fluid/DeepQNetwork/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/PaddleCV/rcnn/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/PaddleRec/ctr/README.md
已删除
100644 → 0
此差异已折叠。
fluid/PaddleRec/din/README.md
已删除
100644 → 0
此差异已折叠。
fluid/PaddleRec/gnn/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/PaddleRec/ssr/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/adversarial/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/README.cn.md
已删除
100644 → 0
此差异已折叠。
legacy/README.md
已删除
100644 → 0
此差异已折叠。
legacy/conv_seq2seq/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/conv_seq2seq/infer.py
已删除
100644 → 0
此差异已折叠。
legacy/conv_seq2seq/model.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/conv_seq2seq/reader.py
已删除
100644 → 0
此差异已折叠。
legacy/conv_seq2seq/train.py
已删除
100644 → 0
此差异已折叠。
legacy/ctr/README.cn.md
已删除
100644 → 0
此差异已折叠。
legacy/ctr/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/ctr/dataset.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
legacy/ctr/infer.py
已删除
100644 → 0
此差异已折叠。
legacy/ctr/network_conf.py
已删除
100644 → 0
此差异已折叠。
legacy/ctr/reader.py
已删除
100644 → 0
此差异已折叠。
legacy/ctr/train.py
已删除
100644 → 0
此差异已折叠。
legacy/ctr/utils.py
已删除
100644 → 0
此差异已折叠。
legacy/deep_fm/README.cn.md
已删除
100644 → 0
此差异已折叠。
legacy/deep_fm/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/deep_fm/infer.py
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
legacy/deep_fm/preprocess.py
已删除
100755 → 0
此差异已折叠。
legacy/deep_fm/reader.py
已删除
100644 → 0
此差异已折叠。
legacy/deep_fm/train.py
已删除
100755 → 0
此差异已折叠。
legacy/dssm/README.cn.md
已删除
100644 → 0
此差异已折叠。
legacy/dssm/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/dssm/data/vocab.txt
已删除
100644 → 0
此差异已折叠。
legacy/dssm/images/dssm.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/dssm/images/dssm.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/dssm/images/dssm2.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/dssm/images/dssm2.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/dssm/images/dssm3.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/dssm/infer.py
已删除
100644 → 0
此差异已折叠。
legacy/dssm/network_conf.py
已删除
100644 → 0
此差异已折叠。
legacy/dssm/reader.py
已删除
100644 → 0
此差异已折叠。
legacy/dssm/train.py
已删除
100644 → 0
此差异已折叠。
legacy/dssm/utils.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/hsigmoid/.gitignore
已删除
100644 → 0
此差异已折叠。
legacy/hsigmoid/README.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
legacy/hsigmoid/infer.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/hsigmoid/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/ltr/README.md
已删除
100644 → 0
此差异已折叠。
legacy/ltr/README_en.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
legacy/ltr/images/ranknet.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
legacy/ltr/infer.py
已删除
100644 → 0
此差异已折叠。
legacy/ltr/lambda_rank.py
已删除
100644 → 0
此差异已折叠。
legacy/ltr/ranknet.py
已删除
100644 → 0
此差异已折叠。
legacy/ltr/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/nce_cost/.gitignore
已删除
100644 → 0
此差异已折叠。
legacy/nce_cost/README.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
legacy/nce_cost/infer.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/nce_cost/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/neural_qa/.gitignore
已删除
100644 → 0
此差异已折叠。
legacy/neural_qa/README.md
已删除
100644 → 0
此差异已折叠。
legacy/neural_qa/config.py
已删除
100644 → 0
此差异已折叠。
legacy/neural_qa/infer.py
已删除
100644 → 0
此差异已折叠。
legacy/neural_qa/network.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/neural_qa/reader.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/neural_qa/train.py
已删除
100644 → 0
此差异已折叠。
legacy/neural_qa/utils.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
legacy/ssd/README.cn.md
已删除
100644 → 0
此差异已折叠。
legacy/ssd/README.md
已删除
100644 → 0
此差异已折叠。
legacy/ssd/config/__init__.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/ssd/data/label_list
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
legacy/ssd/data_provider.py
已删除
100644 → 0
此差异已折叠。
legacy/ssd/eval.py
已删除
100644 → 0
此差异已折叠。
legacy/ssd/image_util.py
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
legacy/ssd/images/vis_1.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/ssd/images/vis_2.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/ssd/images/vis_3.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/ssd/images/vis_4.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
legacy/ssd/infer.py
已删除
100644 → 0
此差异已折叠。
legacy/ssd/train.py
已删除
100644 → 0
此差异已折叠。
legacy/ssd/vgg_ssd_net.py
已删除
100644 → 0
此差异已折叠。
legacy/ssd/visual.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。